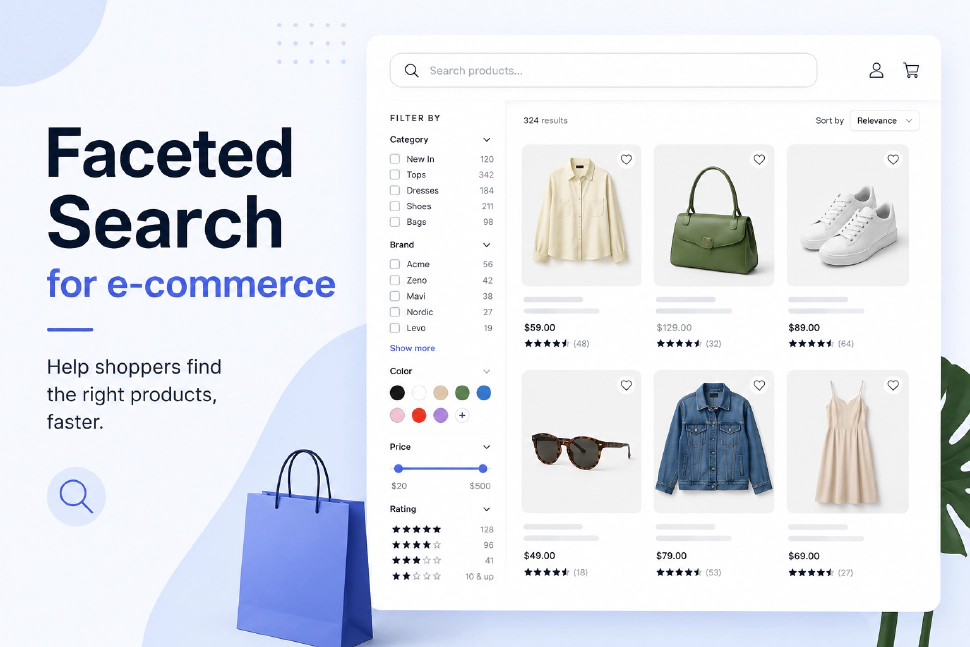
Faceted search under active filters
Manticore Search 25.12.0 adds strict, auto, and max facet modes so e-commerce filters can show selected, available, and unavailable values without manually building separate queries.
Manticore Search 25.12.0 adds strict, auto, and max facet modes so e-commerce filters can show selected, available, and unavailable values without manually building separate queries.

Install Manticore Search with one command that sets up package sources, installs the package, and starts the service.


Meilisearch published a comparison of Meilisearch and Manticore Search. We tested the claims against the latest versions of both engines — here's what a fresh look shows, with reproducible commands.
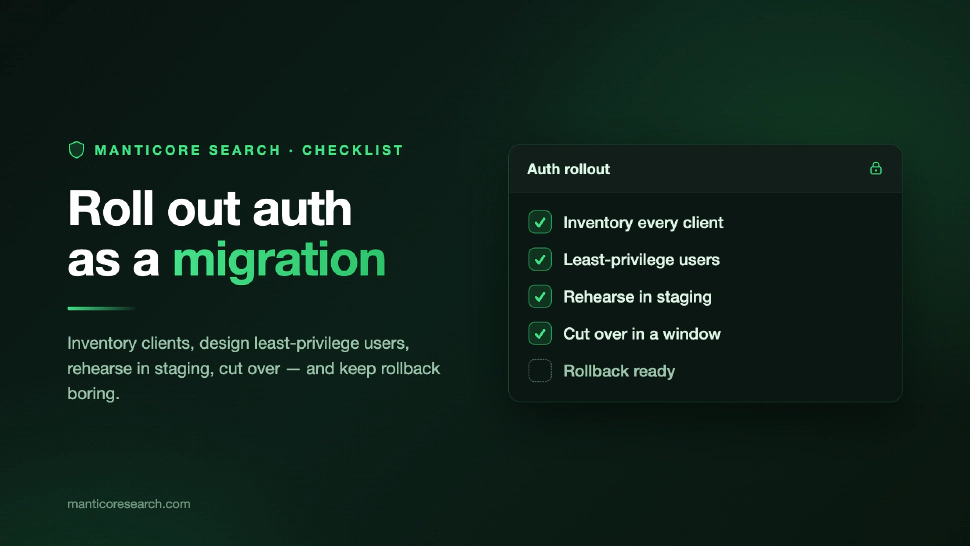
A practical checklist for migrating standalone, distributed, and replicated Manticore Search deployments to authentication without losing access or cluster state.

Learn how to enable Manticore authentication, bootstrap the first administrator, create least-privilege users, use SQL and HTTP credentials, and verify allowed and denied access.

Manticore Search adds built-in authentication and authorization across SQL/MySQL, HTTP, and replication-related operations so teams can control who connects and what each user can do.