







🚀 Performance
you are looking for
Performance drives the development of Manticore Search. We are dedicated to achieving low response times, which are crucial for analyzing large datasets. Throughput is also a key consideration, allowing Manticore to handle a high number of queries per second. Manticore Search is the fastest open-source search engine for big data and vector search.
10.09x
faster for Log Analytics
than Elasticsearch in the log analytics benchmark (10M Nginx log records)
7.28x
faster in big Hackernews benchmark (medium-size data)
than Elasticsearch in the 100M Hackernews comments benchmark
16.7x
faster in small Hackernews benchmark (small data)
than Elasticsearch in the 1 million Hackernews comments benchmark
Cost-effective search engine
Manticore Search is the most user-friendly, accessible, and cost-effective database for search. We excel in efficiency, even on small VM/container setups with minimal resources, such as 1 core and 1GB of memory, while still delivering impressive speed . Manticore Search is designed to handle a wide range of use cases and offers powerful performance with resource efficiency for operations of all scales. Explore our benchmarks here to see how Manticore outperforms other solutions in various scenarios.

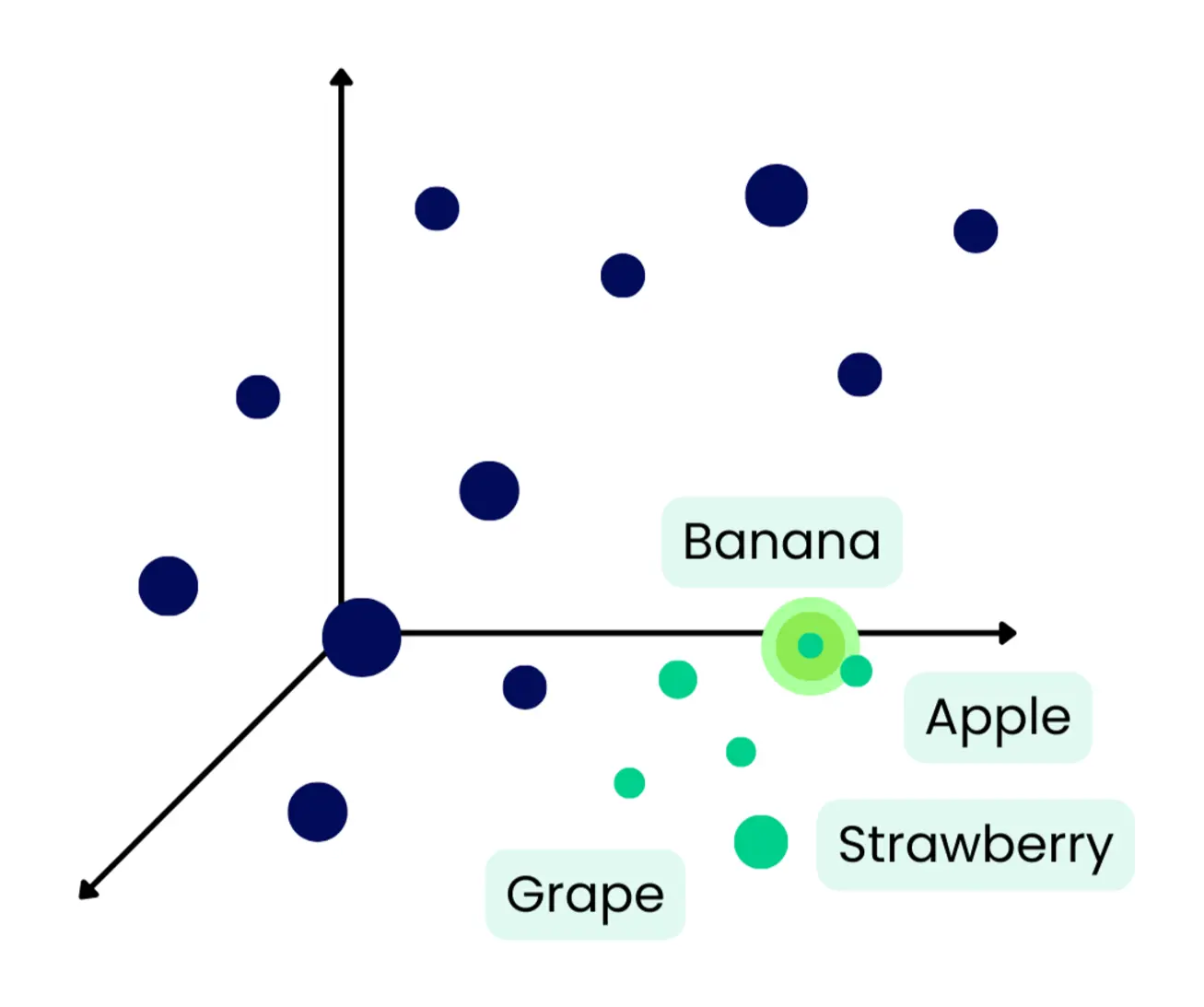
Vector Search
Discover the powerful capabilities of Semantic and Vector Search with Manticore Search. Learn more by exploring our articles on Vector Search in Manticore and Integrating Vector Search into GitHub .
Elasticsearch alternative
Manticore Search is a powerful alternative to Elasticsearch. Integrate it with Logstash and Beats to see performance improvements of up to 29x faster than Elasticsearch when processing a 10M Nginx logs dataset. For log analysis, Manticore also works seamlessly with Kibana, offering better performance. Learn more in our comparison: Manticore Search vs. Elasticsearch for Log Analysis . Explore how Manticore boosts search speeds in various use cases .

Professional Services
While Manticore is 100% open-source, we're here to help you make the most of it!
✓ Consulting: Save your team's time and resources while building faster
✓ Fine-tuning: Ensure your instance runs at peak performance
✓ Feature Development: Get custom features tailored to your business needs
Discover more about our full range of services .

True open source
We love open source. Manticore Search and other publicly available Manticore products are all free to use and published under OSI-approved open source licences . Feel free to contribute on GitHub .

Easy to use
Check out how easy to use Manticore Search with popular programming languages.
Setup and perform a search in a few lines of code under 1 minute.
curl -sS "http://127.0.0.1:9308/sql?mode=raw" -d "DROP TABLE IF EXISTS products"
curl -sS "http://127.0.0.1:9308/sql?mode=raw" -d "CREATE TABLE products(title text, price float) morphology='stem_en'"
curl -sS "http://127.0.0.1:9308/_bulk" -H "Content-Type: application/x-ndjson" -d '
{ "index" : { "_index" : "products" } }
{ "title": "Crossbody Bag with Tassel", "price": 19.85 }
{ "index" : { "_index" : "products" } }
{ "title": "microfiber sheet set", "price": 19.99 }
{ "index" : { "_index" : "products" } }
{ "title": "Pet Hair Remover Glove", "price": 7.99 }
'
curl -sS "http://127.0.0.1:9308/search" -d '{
"index": "products",
"query": { "query_string": "@title bag" },
"highlight": { "fields": ["title"] }
}'
mysql -P9306 -h0 -e "DROP TABLE IF EXISTS products"
mysql -P9306 -h0 -e "CREATE TABLE products(title text, price float) morphology='stem_en'"
mysql -P9306 -h0 -e "INSERT INTO products (id, title, price) VALUES
(1, 'Crossbody Bag with Tassel', 19.85),
(2, 'microfiber sheet set', 19.99),
(3, 'Pet Hair Remover Glove', 7.99)"
mysql -P9306 -h0 -e "SELECT id, HIGHLIGHT(), price FROM products WHERE MATCH('@title bag')"
curl -sS "http://127.0.0.1:9308/sql?mode=raw" -d "DROP TABLE IF EXISTS products"
curl -sS "http://127.0.0.1:9308/sql?mode=raw" -d "CREATE TABLE products(title text, price float) morphology='stem_en'"
curl -sS "http://127.0.0.1:9308/sql?mode=raw" -d "INSERT INTO products (id, title, price) VALUES (1,'Crossbody Bag with Tassel',19.85),(2,'microfiber sheet set',19.99),(3,'Pet Hair Remover Glove',7.99)"
curl -sS "http://127.0.0.1:9308/sql" -d "SELECT id, HIGHLIGHT(), price FROM products WHERE MATCH('@title bag')"
<?php
require __DIR__ . '/vendor/autoload.php';
use Manticoresearch\Client;
$client = new Client(['host' => '127.0.0.1', 'port' => 9308]);
$table = $client->table('products');
$table->drop(true);
$table->create([
'title' => ['type' => 'text'],
'price' => ['type' => 'float'],
]);
$table->addDocument(['title' => 'Crossbody Bag with Tassel', 'price' => 19.85], 1);
$table->addDocument(['title' => 'microfiber sheet set', 'price' => 19.99], 2);
$table->addDocument(['title' => 'Pet Hair Remover Glove', 'price' => 7.99], 3);
$result = $table
->search('@title bag')
->highlight(['title'])
->get();
print_r($result);
const Manticoresearch = require('manticoresearch');
async function main() {
const client = new Manticoresearch.ApiClient();
client.basePath = 'http://127.0.0.1:9308';
const indexApi = new Manticoresearch.IndexApi(client);
const searchApi = new Manticoresearch.SearchApi(client);
const utilsApi = new Manticoresearch.UtilsApi(client);
await utilsApi.sql('DROP TABLE IF EXISTS products');
await utilsApi.sql("CREATE TABLE products(title text, price float) morphology='stem_en'");
await indexApi.insert({ index: 'products', id: 1, doc: { title: 'Crossbody Bag with Tassel', price: 19.85 } });
await indexApi.insert({ index: 'products', id: 2, doc: { title: 'microfiber sheet set', price: 19.99 } });
await indexApi.insert({ index: 'products', id: 3, doc: { title: 'Pet Hair Remover Glove', price: 7.99 } });
const res = await searchApi.search({
index: 'products',
query: { query_string: '@title bag' },
highlight: { fields: { title: {} } },
});
console.log(JSON.stringify(res, null, 2));
}
main().catch((err) => {
console.error(err);
});
import {Configuration, IndexApi, SearchApi, UtilsApi} from "manticoresearch-ts";
async function main(): Promise<void> {
const config = new Configuration({ basePath: "http://127.0.0.1:9308" });
const utilsApi = new UtilsApi(config);
const indexApi = new IndexApi(config);
const searchApi = new SearchApi(config);
await utilsApi.sql("DROP TABLE IF EXISTS products");
await utilsApi.sql("CREATE TABLE products(title text, price float) morphology='stem_en'");
await indexApi.insert({ index: "products", id: 1, doc: { title: "Crossbody Bag with Tassel", price: 19.85 } });
await indexApi.insert({ index: "products", id: 2, doc: { title: "microfiber sheet set", price: 19.99 } });
await indexApi.insert({ index: "products", id: 3, doc: { title: "Pet Hair Remover Glove", price: 7.99 } });
const res = await searchApi.search({
index: "products",
query: { query_string: "@title 包" },
highlight: { fields: ["title"] },
});
console.log(JSON.stringify(res, null, 2));
}
main().catch(console.error);
from __future__ import annotations
from pprint import pprint
import manticoresearch
def main() -> None:
config = manticoresearch.Configuration(host="http://127.0.0.1:9308")
with manticoresearch.ApiClient(config) as client:
index_api = manticoresearch.IndexApi(client)
search_api = manticoresearch.SearchApi(client)
utils_api = manticoresearch.UtilsApi(client)
utils_api.sql("DROP TABLE IF EXISTS products")
utils_api.sql("CREATE TABLE products(title text, price float) morphology='stem_en'")
index_api.insert({"index": "products", "id": 1, "doc": {"title": "Crossbody Bag with Tassel", "price": 19.85}})
index_api.insert({"index": "products", "id": 2, "doc": {"title": "microfiber sheet set", "price": 19.99}})
index_api.insert({"index": "products", "id": 3, "doc": {"title": "Pet Hair Remover Glove", "price": 7.99}})
res = search_api.search(
{
"index": "products",
"query": {"query_string": "@title bag"},
"highlight": {"fields": {"title": {}}},
}
)
pprint(res)
if __name__ == "__main__":
main()
from __future__ import annotations
import asyncio
from pprint import pprint
import manticoresearch
async def main() -> None:
config = manticoresearch.Configuration(host="http://127.0.0.1:9308")
async with manticoresearch.ApiClient(config) as client:
index_api = manticoresearch.IndexApi(client)
search_api = manticoresearch.SearchApi(client)
utils_api = manticoresearch.UtilsApi(client)
await utils_api.sql("DROP TABLE IF EXISTS products")
await utils_api.sql("CREATE TABLE products(title text, price float) morphology='stem_en'")
await index_api.insert({"index": "products", "id": 1, "doc": {"title": "Crossbody Bag with Tassel", "price": 19.85}})
await index_api.insert({"index": "products", "id": 2, "doc": {"title": "microfiber sheet set", "price": 19.99}})
await index_api.insert({"index": "products", "id": 3, "doc": {"title": "Pet Hair Remover Glove", "price": 7.99}})
res = await search_api.search(
{
"index": "products",
"query": {"query_string": "@title bag"},
"highlight": {"fields": {"title": {}}},
}
)
pprint(res)
if __name__ == "__main__":
asyncio.run(main())
package main
import (
"context"
"encoding/json"
"fmt"
"os"
Manticoresearch "github.com/manticoresoftware/manticoresearch-go"
)
func main() {
ctx := context.Background()
configuration := Manticoresearch.NewConfiguration()
configuration.Servers[0].URL = "http://127.0.0.1:9308"
apiClient := Manticoresearch.NewAPIClient(configuration)
_, _, _ = apiClient.UtilsAPI.Sql(ctx).Body("DROP TABLE IF EXISTS products").Execute()
_, _, _ = apiClient.UtilsAPI.Sql(ctx).Body("CREATE TABLE products(title text, price float) morphology='stem_en'").Execute()
docs := []struct {
id int64
title string
price float64
}{
{1, "Crossbody Bag with Tassel", 19.85},
{2, "microfiber sheet set", 19.99},
{3, "Pet Hair Remover Glove", 7.99},
}
for _, d := range docs {
indexDoc := map[string]interface{}{
"title": d.title,
"price": d.price,
}
req := Manticoresearch.NewInsertDocumentRequest("products", indexDoc)
req.SetId(d.id)
if _, _, err := apiClient.IndexAPI.Insert(ctx).InsertDocumentRequest(*req).Execute(); err != nil {
panic(err)
}
}
searchRequest := Manticoresearch.NewSearchRequest("products")
searchQuery := Manticoresearch.NewSearchQuery()
searchQuery.QueryString = "@title bag"
searchRequest.Query = searchQuery
hl := Manticoresearch.NewHighlight()
hl.Fields = map[string]interface{}{"title": map[string]interface{}{}}
searchRequest.Highlight = hl
resp, _, err := apiClient.SearchAPI.Search(ctx).SearchRequest(*searchRequest).Execute()
if err != nil {
panic(err)
}
b, _ := json.MarshalIndent(resp, "", " ")
fmt.Println(string(b))
}
using System;
using System.Collections.Generic;
using System.Net.Http;
using ManticoreSearch.Api;
using ManticoreSearch.Client;
using ManticoreSearch.Model;
internal class Program
{
private static void Main()
{
var baseUrl = "http://127.0.0.1:9308";
var config = new Configuration { BasePath = baseUrl };
using var httpClientHandler = new HttpClientHandler();
using var httpClient = new HttpClient(httpClientHandler);
var utilsApi = new UtilsApi(httpClient, config, httpClientHandler);
var indexApi = new IndexApi(httpClient, config, httpClientHandler);
var searchApi = new SearchApi(httpClient, config, httpClientHandler);
utilsApi.Sql("DROP TABLE IF EXISTS products", true);
utilsApi.Sql("CREATE TABLE products(title text, price float) morphology='stem_en'", true);
var docs = new[]
{
new Dictionary<string, object> { ["title"] = "Crossbody Bag with Tassel", ["price"] = 19.85 },
new Dictionary<string, object> { ["title"] = "microfiber sheet set", ["price"] = 19.99 },
new Dictionary<string, object> { ["title"] = "Pet Hair Remover Glove", ["price"] = 7.99 },
};
foreach (var doc in docs)
{
var insertRequest = new InsertDocumentRequest(Index: "products", Doc: doc);
indexApi.Insert(insertRequest);
}
var searchRequest = new SearchRequest(Index: "products")
{
Query = new SearchQuery { QueryString = "@title bag" },
Highlight = new Highlight { Fields = new List<string> { "title" } }
};
var searchResponse = searchApi.Search(searchRequest);
Console.WriteLine(searchResponse);
}
}
import com.manticoresearch.client.ApiClient;
import com.manticoresearch.client.ApiException;
import com.manticoresearch.client.api.IndexApi;
import com.manticoresearch.client.api.SearchApi;
import com.manticoresearch.client.api.UtilsApi;
public class ManticoreExample {
public static void main(String[] args) throws ApiException {
ApiClient client = new ApiClient();
client.setBasePath("http://127.0.0.1:9308");
IndexApi indexApi = new IndexApi(client);
SearchApi searchApi = new SearchApi(client);
UtilsApi utilsApi = new UtilsApi(client);
utilsApi.sql("DROP TABLE IF EXISTS products", true);
utilsApi.sql("CREATE TABLE products(title text, price float) morphology='stem_en'", true);
indexApi.insert("{"index":"products","id":1,"doc":{"title":"Crossbody Bag with Tassel","price":19.85}}");
indexApi.insert("{"index":"products","id":2,"doc":{"title":"microfiber sheet set","price":19.99}}");
indexApi.insert("{"index":"products","id":3,"doc":{"title":"Pet Hair Remover Glove","price":7.99}}");
String searchRequest = "{"
+ ""index":"products","
+ ""query":{"query_string":"@title bag"},"
+ ""highlight":{"fields":{"title":{}}}"
+ "}";
System.out.println(searchApi.search(searchRequest));
}
}
use manticoresearch::apis::configuration::Configuration;
use manticoresearch::apis::{index_api, search_api, utils_api};
use manticoresearch::models::{
Highlight, HighlightFieldOption, HighlightFields, SearchQuery, SearchRequest,
};
use serde_json::json;
fn main() {
let mut config = Configuration::new();
config.base_path = "http://127.0.0.1:9308".to_string();
let _ = utils_api::sql(&config, "DROP TABLE IF EXISTS products", None);
let _ = utils_api::sql(&config, "CREATE TABLE products(title text, price float) morphology='stem_en'", None);
let docs = [
(1, "Crossbody Bag with Tassel", 19.85),
(2, "microfiber sheet set", 19.99),
(3, "Pet Hair Remover Glove", 7.99),
];
for (id, title, price) in docs {
let body = json!({
"index": "products",
"id": id,
"doc": { "title": title, "price": price }
});
index_api::insert(&config, body, None).unwrap();
}
let query = SearchQuery {
query_string: Some("@title bag".to_string()),
..Default::default()
};
let highlight = Highlight {
fields: Some(HighlightFields {
title: Some(HighlightFieldOption {
..Default::default()
}),
}),
..Default::default()
};
let req = SearchRequest {
index: "products".to_string(),
query: Box::new(query),
highlight: Some(Box::new(highlight)),
..Default::default()
};
let resp = search_api::search(&config, req, None).unwrap();
println!("{}", serde_json::to_string_pretty(&resp).unwrap());
}
What people say about Manticore Search
Don't just take our word for it, hear what our lovely users have to say!
We rely on Manticore daily as the backbone of our text analysis service, leveraging both its powerful core engine and Python API. The support from the Manticore team is exceptional—they're always responsive, knowledgeable, and eager to help. Among its many strengths, we particularly appreciate: - Efficient bulk inserts/updates for high-throughput operations. - Seamless container integration, simplifying deployment and scalability. - The flexible match() functionality, which enables precise and customizable querying. After evaluating multiple solutions with similar capabilities, we chose Manticore for its unmatched flexibility and rich feature set.

orazs
I use the engine itself and the go and php clients. I chose Manticore because it's open source, easy to integrate, has responsive developers, and doesn't need much hardware. Very positive experience—the engine gave a huge performance boost and opened doors for new services.

Alisher Rusinov
Flumtec
I like Manticore search for its low resource consumption. Elasticsearch as an alternative is more resource hungry because of Java. The documentation could explain faceted and prefix search more clearly. Overall, I really like it - I haven't used it in production yet, but I will soon. Big thanks to the community for pointing me to Manticore!

Roman
Python Backend Dev
I found out about Manticore at work in https://poisk.im/ (The site where we use Manticore). The docs are great, the product is fast, and overall it's solid—I'd rate it 8/10. I'd love to see features like associative search, vector search, and fuzzy search available over HTTP, not just SQL.

Flild
Backend developer in notissimus
We found Manticore while looking for a Meilisearch alternative. In our use case, it's been more reliable, flexible, and predictable than Meilisearch. It would be great to have prepared statements in SQL mode and auto optimize without a balancer. Overall, everything's good.

Max Besogonov
Developer at @thermos
I use Manticore for full-text search and love how fast the queries are. I'd give it 7/10—at some places the error messages need to be more clear, but the support team is great and I believe the project will keep getting better.

Ali Suliman
Developer at BeInMedia
Manticoresearch is fast, handles high load even on weak servers, and configs are very flexible. It's super stable—I'm on version 4 in production and preparing to move to version 9. If something's missing, I usually handle it in custom code. Overall, my experience is very positive—docs and the Telegram support channel help with everything.

Yuri (godem111)
We use Manticore Search for over 5 years now. It's flexible, easy to set up, and scales well with large indexes. We'd love to see more advanced grouping options like median, and the ability to use functions like month() and day() with time zone support. Overall, our experience has been very positive — we switched from Sphinx long ago due to its limited features. Some context: - Indexed documents: ~100m - Indexed bytes: 35TiB (in the future, we plan to increase this number up to 100)

sabnak
I use manticore search and the columnar library—it's a complete and easy search solution that covers all my use cases. It's fast, scalable, open source, and supports mysql protocol and geo search. I'd give it 9/10. I'd love better docs for non-experts, easier data ingestion, and maybe Parquet support. Found it after trying Sphinx and other tools—Manticore just works better

blackrez
One of the defining features of Manticore that immediately grabbed my attention was its remarkable speed. The ability to interface with the service using JSON made for a flexible and modern approach to handling search queries, aligning well with current development practices. My overall experience with Manticore has been somewhat mixed. On one hand, I've genuinely enjoyed the capabilities it brings to the table, particularly the performance and the JSON communication method. These aspects have significantly enhanced the efficiency and adaptability of my projects. On the other hand, mastering Manticore has been a journey that required a thorough dive into its manual. The learning curve, while not insurmountable, demanded considerable time and effort. An active community and a support forum also made a significant contribution to the process of finding solutions to the problems that arose in front of me. A notable challenge has been the strong orientation towards SQL, including the training materials, which, while comprehensive, posed a steep learning path for someone more accustomed to JSON-centric systems. Despite these challenges, my experience with Manticore has been largely positive. The blend of speed, flexibility, and powerful search capabilities it offers has been invaluable. Moving forward, I hope to see a broader range of learning resources that cater to both SQL veterans and those more comfortable with JSON. Manticore has the potential to be a versatile tool in the search technology space, and I'm keen to continue exploring its possibilities.

THE-KONDRAT
We rely on Manticore daily as the backbone of our text analysis service, leveraging both its powerful core engine and Python API. The support from the Manticore team is exceptional—they're always responsive, knowledgeable, and eager to help. Among its many strengths, we particularly appreciate: - Efficient bulk inserts/updates for high-throughput operations. - Seamless container integration, simplifying deployment and scalability. - The flexible match() functionality, which enables precise and customizable querying. After evaluating multiple solutions with similar capabilities, we chose Manticore for its unmatched flexibility and rich feature set.
orazs
I use the engine itself and the go and php clients. I chose Manticore because it's open source, easy to integrate, has responsive developers, and doesn't need much hardware. Very positive experience—the engine gave a huge performance boost and opened doors for new services.
Alisher Rusinov
Flumtec
I like Manticore search for its low resource consumption. Elasticsearch as an alternative is more resource hungry because of Java. The documentation could explain faceted and prefix search more clearly. Overall, I really like it - I haven't used it in production yet, but I will soon. Big thanks to the community for pointing me to Manticore!
Roman
Python Backend Dev
I found out about Manticore at work in https://poisk.im/ (The site where we use Manticore). The docs are great, the product is fast, and overall it's solid—I'd rate it 8/10. I'd love to see features like associative search, vector search, and fuzzy search available over HTTP, not just SQL.
Flild
Backend developer in notissimus
We found Manticore while looking for a Meilisearch alternative. In our use case, it's been more reliable, flexible, and predictable than Meilisearch. It would be great to have prepared statements in SQL mode and auto optimize without a balancer. Overall, everything's good.
Max Besogonov
Developer at @thermos
I use Manticore for full-text search and love how fast the queries are. I'd give it 7/10—at some places the error messages need to be more clear, but the support team is great and I believe the project will keep getting better.
Ali Suliman
Developer at BeInMedia
Manticoresearch is fast, handles high load even on weak servers, and configs are very flexible. It's super stable—I'm on version 4 in production and preparing to move to version 9. If something's missing, I usually handle it in custom code. Overall, my experience is very positive—docs and the Telegram support channel help with everything.
Yuri (godem111)
We use Manticore Search for over 5 years now. It's flexible, easy to set up, and scales well with large indexes. We'd love to see more advanced grouping options like median, and the ability to use functions like month() and day() with time zone support. Overall, our experience has been very positive — we switched from Sphinx long ago due to its limited features. Some context: - Indexed documents: ~100m - Indexed bytes: 35TiB (in the future, we plan to increase this number up to 100)
sabnak
I use manticore search and the columnar library—it's a complete and easy search solution that covers all my use cases. It's fast, scalable, open source, and supports mysql protocol and geo search. I'd give it 9/10. I'd love better docs for non-experts, easier data ingestion, and maybe Parquet support. Found it after trying Sphinx and other tools—Manticore just works better
blackrez
One of the defining features of Manticore that immediately grabbed my attention was its remarkable speed. The ability to interface with the service using JSON made for a flexible and modern approach to handling search queries, aligning well with current development practices. My overall experience with Manticore has been somewhat mixed. On one hand, I've genuinely enjoyed the capabilities it brings to the table, particularly the performance and the JSON communication method. These aspects have significantly enhanced the efficiency and adaptability of my projects. On the other hand, mastering Manticore has been a journey that required a thorough dive into its manual. The learning curve, while not insurmountable, demanded considerable time and effort. An active community and a support forum also made a significant contribution to the process of finding solutions to the problems that arose in front of me. A notable challenge has been the strong orientation towards SQL, including the training materials, which, while comprehensive, posed a steep learning path for someone more accustomed to JSON-centric systems. Despite these challenges, my experience with Manticore has been largely positive. The blend of speed, flexibility, and powerful search capabilities it offers has been invaluable. Moving forward, I hope to see a broader range of learning resources that cater to both SQL veterans and those more comfortable with JSON. Manticore has the potential to be a versatile tool in the search technology space, and I'm keen to continue exploring its possibilities.