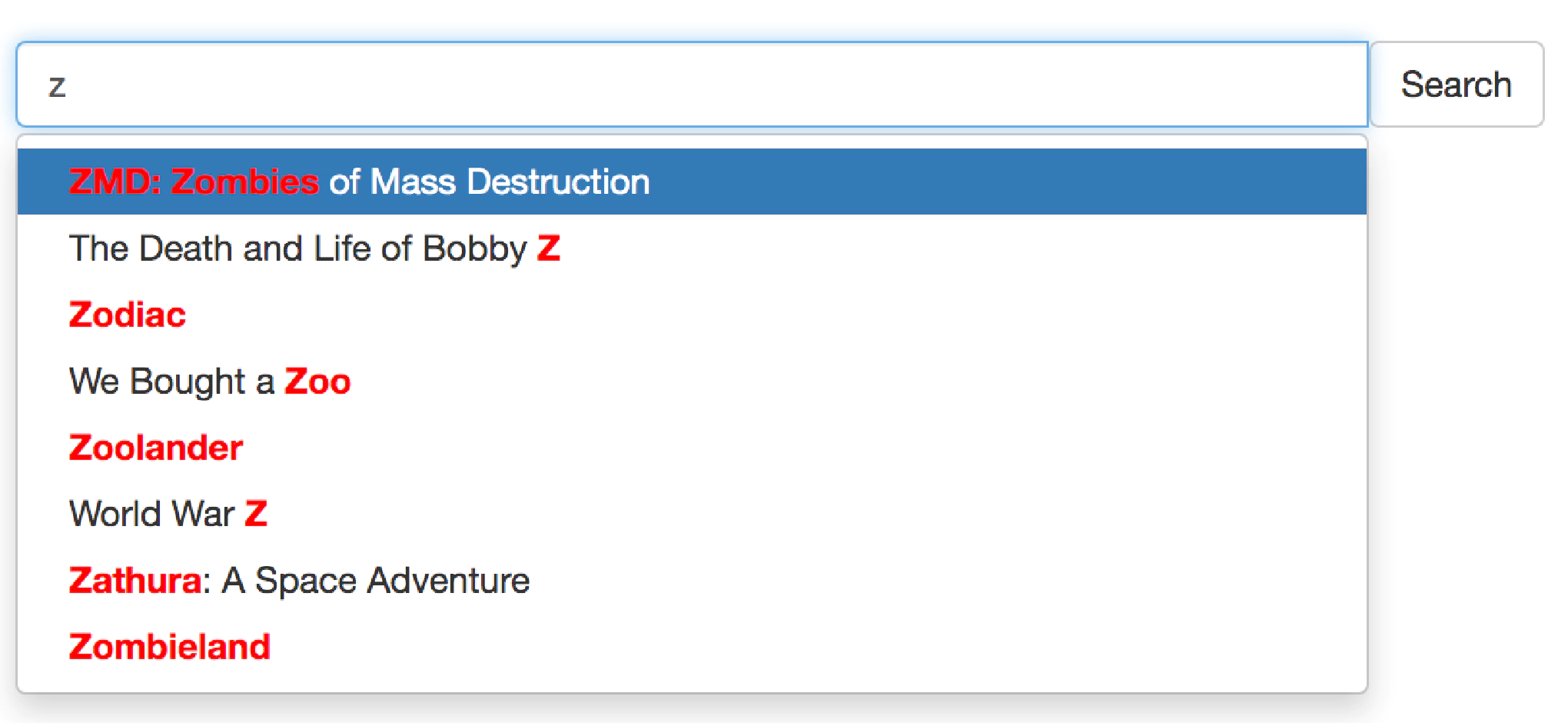
本文描述了在 Manticore Search 中实现词补全的一种方法。
什么是自动补全?
自动补全(或词补全)是一种功能,允许应用程序在用户输入时预测剩余的单词。通常的工作方式是:用户在搜索栏中开始输入一个单词,然后会弹出一个包含建议的下拉菜单,用户可以从列表中选择一个。
建议的来源可以是各种各样的。最好是显示的单词或句子在现有的数据集中可用,这样用户不会选择返回空结果的内容。但在某些情况下,自动补全基于之前的(成功)搜索,理论上可能找不到结果,但仍可能有意义。这取决于您应用程序的具体情况。
最简单的自动补全可以通过从数据集中项目标题中查找建议来实现。这可以是文章/新闻的标题、产品的名称,或者正如我们很快将展示的电影名称。为此,我们需要将字段定义为 字符串属性 或 存储字段 ,以避免在原始数据中进行额外的查找。
由于用户需要提供一个不完整的单词,我们需要执行通配符搜索。可以通过在索引中启用前缀匹配或中缀匹配来实现通配符搜索。由于这可能 影响响应时间 ,您需要决定是否要在用于搜索的索引中启用它,或者仅在专门用于自动补全功能的索引中启用。另一个原因是为了使后者尽可能紧凑,以提供最小的延迟,这对于自动补全的用户体验尤为重要。通常我们会将通配符星号添加到右侧,因为我们假设用户开始输入一个单词,但为了更广泛的结果,我们会在两侧都添加星号以获取可能具有前缀的单词。在本教程中,对于电影数据集,我们选择中缀匹配,因为它还启用了用于单词更正的 SUGGEST 功能( 参见此教程 中的说明)。我们的索引声明将是:
index movies {
type = plain
path = /var/lib/manticore/data/movies
source = movies
min_infix_len = 3
}
由于我们将从电影标题提供自动补全,我们的查询将仅限于 'movie_title' 字段。
电影标题的自动补全
您的应用程序前端可以在搜索框中输入第一个字符时开始查询建议。然而,如果索引非常大,这可能会对系统造成更大的压力,因为它将向服务器发送更多请求,而且 1-2 个字符的通配符搜索可能较慢。假设用户输入 'sha'。
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title sha*');
+------+---------------------------------------+
| id | movie_title |
+------+---------------------------------------+
| 118 | A Low Down Dirty Shame |
| 394 | Austin Powers: The Spy Who Shagged Me |
| 604 | Book of Shadows: Blair Witch 2 |
| 951 | Dark Shadows |
| 1318 | Fifty Shades of Black |
| 1319 | Fifty Shades of Grey |
| 1389 | Forty Shades of Blue |
| 1853 | In the Shadow of the Moon |
| 1928 | Jack Ryan: Shadow Recruit |
| 3114 | Shade |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 3117 | Shadowlands |
| 3118 | Shaft |
| 3119 | Shakespeare in Love |
| 3120 | Shalako |
| 3121 | Shall We Dance |
| 3122 | Shallow Hal |
| 3123 | Shame |
| 3124 | Shanghai Calling |
+------+---------------------------------------+
20 rows in set (0.00 sec)
我们主要关注电影标题,因此不会返回所有列。正如我们所见,返回了大量结果。我们可以通过例如按 Facebook 喜欢数进行二次排序来调整查询,但此时还太早做出用户正在寻找什么的准确猜测:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title sha*') ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3131 | Shark Tale |
| 394 | Austin Powers: The Spy Who Shagged Me |
| 3118 | Shaft |
| 4326 | The Shaggy Dog |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3134 | Shattered |
| 3123 | Shame |
| 3525 | The Adventures of Sharkboy and Lavagirl 3-D |
| 3117 | Shadowlands |
| 3129 | Shark Lake |
| 4328 | The Shawshank Redemption |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 3135 | Shattered Glass |
| 3130 | Shark Night 3D |
| 1319 | Fifty Shades of Grey |
| 4619 | Tristram Shandy: A Cock and Bull Story |
| 118 | A Low Down Dirty Shame |
| 3132 | Sharknado |
| 1318 | Fifty Shades of Black |
+------+--------------------------------------------------+
20 rows in set (0.00 sec)
假设用户输入另一个字母:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shaf*') ORDER BY WEIGHT() DES , cast_total_facebook_likes DESC;
+------+-------------+
| id | movie_title |
+------+-------------+
| 3118 | Shaft |
+------+-------------+
1 row in set (0.00 sec)
现在我们只有一个结果。
让我们再举一个例子,假设我们输入 'shad*'。
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shad*') ORDER BY WEIGHT() DES , cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3117 | Shadowlands |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 1319 | Fifty Shades of Grey |
| 1318 | Fifty Shades of Black |
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 1389 | Forty Shades of Blue |
| 604 | Book of Shadows: Blair Witch 2 |
| 3114 | Shade |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+--------------------------------------------------+
15 rows in set (0.00 sec)
然后输入 shado*:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shado*') ORDER BY WEIGHT() DE C, cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3117 | Shadowlands |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 604 | Book of Shadows: Blair Witch 2 |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+--------------------------------------------------+
11 rows in set (0.00 sec)
以及 'shadow':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shadow') ORDER BY WEIGHT() DE C, cast_total_facebook_likes DESC;
+------+---------------------------+
| id | movie_title |
+------+---------------------------+
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+---------------------------+
6 rows in set (0.00 sec)
假设用户正在寻找 'shadow' 作为第一个词,他将继续输入另一个词,例如 'shadow c':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shadow c*') ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+------+-------------------+
| id | movie_title |
+------+-------------------+
| 3115 | Shadow Conspiracy |
+------+-------------------+
1 row in set (0.01 sec)
在这种情况下,我们得到一个结果,应该能满足用户,但在其他情况下可能会得到更多结果,用户将继续输入字母,就像第一个词一样,Manticore 会根据输入返回更多建议:

添加更多过滤条件
在之前的示例中,匹配项的唯一限制是必须是指定字段的一部分。如果我们想要,可以实现更严格的自动补全。
例如,这里我们获取以 'americ' 开头的匹配项,如 'American Hustle',还有 'Captain America: Civil War':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title americ* ') ORDER BY WEIGHT() D SC, cast_total_facebook_likes DESC;
+------+---------------------------------------------------+
| id | movie_title |
+------+---------------------------------------------------+
| 277 | American Hustle |
| 701 | Captain America: Civil War |
| 703 | Captain America: The Winter Soldier |
| 282 | American Psycho |
| 2612 | Once Upon a Time in America |
| 272 | American Gangster |
| 702 | Captain America: The First Avenger |
| 269 | American Beauty |
| 478 | Beavis and Butt-Head Do America |
| 284 | American Sniper |
| 4036 | The Legend of Hell's Gate: An American Conspiracy |
| 273 | American Graffiti |
| 285 | American Splendor |
| 274 | American Heist |
| 287 | America's Sweethearts |
| 283 | American Reunion |
| 280 | American Pie |
| 281 | American Pie 2 |
| 271 | American Dreamz |
| 286 | American Wedding |
+------+---------------------------------------------------+
20 rows in set (0.00 sec)
我们可以使用起始字段运算符仅显示以输入项开头的记录:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title ^americ* ') ORDER BY WEIGHT() ESC, cast_total_facebook_likes DESC;
+------+-------------------------------------+
| id | movie_title |
+------+-------------------------------------+
| 277 | American Hustle |
| 282 | American Psycho |
| 272 | American Gangster |
| 269 | American Beauty |
| 284 | American Sniper |
| 273 | American Graffiti |
| 285 | American Splendor |
| 274 | American Heist |
| 287 | America's Sweethearts |
| 283 | American Reunion |
| 280 | American Pie |
| 281 | American Pie 2 |
| 271 | American Dreamz |
| 286 | American Wedding |
| 276 | American History X |
| 268 | America Is Still the Place |
| 279 | American Outlaws |
| 275 | American Hero |
| 278 | American Ninja 2: The Confrontation |
| 270 | American Desi |
+------+-------------------------------------+
20 rows in set (0.00 sec)
我们还需要考虑重复项。这在我们想要在没有唯一值的字段上进行自动补全时更为重要。例如,让我们尝试通过演员名称进行自动补全:
MySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ');
+--------------------+
| actor_1_name |
+--------------------+
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| Don Johnson |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| R. Brandon Johnson |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
+--------------------+
20 rows in set (0.09 sec)
我们可以看到很多重复项。可以通过在该字段上进行分组来解决这个问题——假设我们将其作为字符串属性:
MySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name; [AMySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name;
+------------------------+
| actor_1_name |
+------------------------+
| Johnny Depp |
| Dwayne Johnson |
| Don Johnson |
| R. Brandon Johnson |
| Johnny Pacar |
| Kenny Johnston |
| Johnny Cannizzaro |
| Nicole Randall Johnson |
| Johnny Lewis |
| Richard Johnson |
| Bill Johnson |
| Eric Johnson |
| John Belushi |
| John Cothran |
| John Ratzenberger |
| John Cameron Mitchell |
| John Saxon |
| John Gatins |
| John Boyega |
| John Michael Higgins |
+------------------------+
20 rows in set (0.10 sec)
高亮显示
自动补全查询可以返回包含高亮显示的结果。虽然也可以在应用程序端执行高亮显示,但 Manticore Search 的高亮显示更强大,因为它会遵循搜索查询(相同的分词设置, 查询中的 AND、OR 和 NOT 等 )。以之前的示例为例,我们只需要使用 'SNIPPET' 函数:
MySQL [(none)]> SELECT SNIPPET(actor_1_name,' john*') FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+--------------------------------+
| snippet(actor_1_name,' john*') |
+--------------------------------+
| <b>Johnny</b> Depp |
| Dwayne <b>Johnson</b> |
| <b>Johnny</b> Pacar |
| Don <b>Johnson</b> |
| <b>Johnny</b> Cannizzaro |
| <b>Johnny</b> Lewis |
| Eric <b>Johnson</b> |
| Nicole Randall <b>Johnson</b> |
| Kenny <b>Johnston</b> |
| R. Brandon <b>Johnson</b> |
| Bill <b>Johnson</b> |
| Richard <b>Johnson</b> |
| <b>John</b> Ratzenberger |
| <b>John</b> Belushi |
| <b>John</b> Cameron Mitchell |
| <b>John</b> Cothran |
| Olivia Newton-<b>John</b> |
| <b>John</b> Michael Higgins |
| <b>John</b> Witherspoon |
| <b>John</b> Amos |
+--------------------------------+
20 rows in set (0.00 sec)
有关高亮显示的更多信息,请参阅 此教程 。
除了使用前缀和后缀之外,Manticore 还有其他实现自动补全的方法:使用 CALL KEYWORDS ,开启或关闭 bigram_index ,使用 CALL QSUGGEST / CALL SUGGEST 。但本文中展示的方法似乎是最容易上手的。如果你想尝试 Manticore Search,可以使用我们的 docker image ,它包含一个单行命令,可以在几秒钟内在任何服务器上运行 Manticore。