
搜索系统通常从很简单开始:一台服务器上一张表。直到发生两种情况之一才会暴露问题。要么单个查询已经无法吃满你为它付费的全部 CPU,要么单台服务器已经不够了,无论是容量、吞吐量,还是最简单的事实:服务器可能会故障并带走你的数据。
Manticore Search 内置的自动分片自 27.1.5 版本起可用,它通过把一张表拆成多个更小的物理部分(分片),这些分片可以并行检索并放在不同节点上,解决了这两个问题:
- 在单节点上,分片把并发写入分散到彼此独立的部分上,并让每一部分保持足够小,从而维持高性能。
- 在集群中,分片把数据分布到多个节点上,更重要的是,会自动复制每个分片,并在节点故障和恢复时保持该复制因子不变。
第二部分才是大多数人使用分片的真正原因:高可用。你只需要声明想要多少个分片,以及每个分片要有多少份副本,Manticore 会负责放置、复制和重新均衡。你不需要自己写故障切换脚本。
下面会讲这两种用法、不会淹没在内部细节里的工作机制、你会用到的命令,以及当前限制。
简短术语表
关键术语:
| 术语 | 含义 |
|---|---|
| Shard | 表的一个物理部分,也就是 Manticore 为你创建并管理的真实表。shards='4' 的表会有四个这样的部分。 |
| Replica | 另一台节点上的某个分片副本。Replica 是数据在节点故障后仍能存活的方式。 |
| Replication factor (RF) | 每个分片有多少台节点保存副本。rf='2' 表示每个分片都存在于两台节点上。 |
| Distributed table | 你实际查询的表。它使用你给定的名字,并透明地把查询分发到所有分片。 |
| Cluster | 一个 Manticore 复制集群,也就是数据在其间复制的一组节点。 |
| Master | 当前负责协调分片操作(放置、重新均衡)的节点,由系统自动选举。 |
| Rebalancing | 当节点集合发生变化时,自动移动或复制分片的过程。 |
如何创建分片表
Manticore 中的分片完全由 CREATE TABLE 上两个简单选项驱动:
CREATE TABLE products (id bigint, title text, price float) shards='4' rf='2'
shards='N'- 把表拆成N个物理部分。rf='M'- 在集群中保留每个部分的M份副本(复制因子)。
在常见场景下,你只需要写这一条 CREATE TABLE。不需要单独的“把它变成分布式表”的步骤,不需要像旧式手工分片方案那样手写 agent= 列表,也不需要在每台节点上分别创建表。Manticore 会创建物理分片、放置它们、建立复制,并在每台节点上创建一个名为 products 的分布式表,因此应用可以在集群中的任意节点上使用相同的表名。
用例 A:单节点上的分片
先看只有一台服务器的情况,也许它是台很大、很多核的机器,而且还没有集群。在这个场景里,分片不是为了存储持久性,而是为了更高效地利用这台机器。如果所有写入都进入一张实时表,并发 INSERT 会争用同一组内部表锁。随着表变大,RAM-chunk 合并
会更重,可能拖慢数据摄取。把这张表拆成多个彼此独立的分片,可以在两个方面都受益:写入分散到各个分片上,每个部分保持更小。此时还谈不上高可用,因为那需要不止一台节点,所以这纯粹是性能优化。
最简单的形式不包含集群,并且 rf='1':
CREATE TABLE logs (id bigint, message text, ts timestamp) shards='8' rf='1'
这会在这台节点上创建 8 个物理分片,以及一个指向它们全部的分布式表 logs。这在单机上如何提升效果?
- 更多并发摄取。 每个分片都是一张独立的实时表,所以并发写入会分散到多个分片上,而不是在一张表的锁上串行化。这正是下面的基准测试 直接衡量到的收益。
- 更小的部分保持高性能。 实时表会周期性合并内部 RAM chunk。拆分成分片后,每个分片的 chunk 更小,因此这些合并消耗更少资源,也更不容易拖慢插入。
- 查询并行化(在单机上通常收益不大)。 分布式表会通过服务器的工作线程池并行搜索各个分片,因此单个查询可以用到多个核心,而不只是一个核心,受
searchd.threads和物理核心数量限制。不过在单节点上,这和伪分片 有重叠,收益通常不大(约 5–12%)——见下面的读取基准测试 。
如果你以前用过 Manticore 的伪分片 ,目标可能很熟悉——让一个查询用上所有核心——但机制不同。伪分片会在查询时自动并行化单个物理表。显式分片会创建你可控的真实分片:你决定数量,它们是彼此独立、便于理解的表,而且更关键的是,同一张分片表以后还可以跨节点分布,而不用改变应用与它交互的方式。
这两者是互补的,但并不会自动叠加出免费收益。物理分片,也就是由多个本地表组成的分布式表,已经能让工作线程忙起来,所以如果你已经显式分片了,再在上面开启
pseudo_sharding通常收益很小,甚至可能稍微损失一点吞吐量。用manticore-load两种方式都测一下:在开启和关闭pseudo_sharding的情况下分别跑你的负载,如果它在显式分片之上没有带来额外收益,就把它关掉。
在单节点上,复制因子必须是 1:只有一台节点,没有地方放第二份副本。这也是单节点分片的边界条件,它带来的是并行性,不是持久性。要想要持久性,你需要不止一台节点。
用例 B:多节点分片与自动复制
这才是分片真正要解决的问题。先从一个包含多台节点的复制集群开始(如何创建请看设置复制
),然后在这个集群里用 cluster: 前缀并设置大于 1 的 RF 创建表:
CREATE TABLE mycluster:products (id bigint, title text, price float) shards='4' rf='2'
Manticore 会替你做这些事:
- 创建四个分片。
- 以平衡的方式把它们分布到集群节点上。
- 为每个分片在不同节点上创建第二份副本,因为
rf='2'。 - 为每个分片与其副本建立复制。
- 在每台节点上创建一个分布式表
products,因此任意节点都可以提供读取和接受写入。
从应用的角度看,没有任何变化,你仍然可以 INSERT INTO products … 和 SELECT … FROM products。读取会被分发到各个分片并合并结果;写入会被路由到某个分片。但现在每个分片都存在于两台节点上,这才是你关心的属性:任意一台节点都可以故障,而表仍然完全可用且不会丢数据。
复制因子会随着你的持久性需求和节点数量而扩展:
| RF | 每个分片的副本数 | 可承受 | 典型用途 |
|---|---|---|---|
| 1 | 1 | 什么都扛不住 - 节点丢失就会丢失它的分片 | 单节点并行、开发/测试、可重建的数据 |
| 2 | 2 | 一台节点故障 | 常见的生产选择 |
| 3+ | 3 份或更多 | 多个同时故障 | 关键业务、故障频繁的环境 |
限制很简单:你不能要求比节点数更多的副本。 rf='3' 至少需要集群里有三台节点。Manticore 会在你创建表时检查这一点,并在集群太小时告诉你。
-- 6 shards, 3 copies each, across a 3+ node cluster
CREATE TABLE mycluster:events (id bigint, body text) shards='6' rf='3'
把这些串起来:多节点演示
假设你有一个名为 mycluster 的三节点复制集群(如果还没有,设置复制
会演示 CREATE CLUSTER 和 JOIN CLUSTER)。从任意节点创建一个分片且复制的表:
CREATE TABLE mycluster:products (id bigint, title text, price float) shards='4' rf='2'
Manticore 会创建四个分片,把每个分片的两份副本放到三台节点上,并在每台节点上创建一个分布式表 products。检查其放置情况:
SHOW SHARDING STATUS products;
-- illustrative output (abbreviated columns)
+-------+-------+--------+----+-----------+
| shard | node | status | rf | rf_status |
+-------+-------+--------+----+-----------+
| 0 | node1 | active | 2 | ok |
| 0 | node2 | active | 2 | ok |
| 1 | node2 | active | 2 | ok |
| 1 | node3 | active | 2 | ok |
| 2 | node1 | active | 2 | ok |
| 2 | node3 | active | 2 | ok |
| 3 | node1 | active | 2 | ok |
| 3 | node2 | active | 2 | ok |
+-------+-------+--------+----+-----------+
每个分片都出现在两台不同的节点上,这就是 rf=2,并且每个 rf_status 都是 ok。(完整结果还包含 table、cluster 和 replication_cluster 列。)现在像使用任何其他表一样使用它,任意节点都可以:
INSERT INTO products (id, title, price) VALUES (1, 'Wireless mouse', 19.99);
SELECT * FROM products WHERE MATCH('mouse');
写入会被路由到某个分片,并复制到该分片的另一份副本;读取会分发到全部四个分片并合并结果。你的应用从来不需要指定某个分片名。
维持复制因子
设置 rf='2' 很简单。任何分布式系统里真正困难的是随着时间维持这个条件,也就是机器故障和恢复,以及你增加容量的时候。不过你现在不用再担心这些了。Manticore Search 会自动完成这项工作。
Manticore 的做法是让集群选举出一个负责协调循环的 master 节点。它监控集群拓扑,也就是哪些节点存活,并对变化做出响应:
节点故障
此时它的分片副本数少于 RF 要求。master 会检测到缺失的节点,并尝试重建丢失的副本。如果故障后集群仍至少有 rf 个活跃节点,它会把新的副本放到那些尚未持有它们的活跃节点上,从而恢复复制因子。只要每个分片至少还有一份副本可用,查询就能继续工作。
继续上面的演示 - 如果 node3 宕机,SHOW SHARDING STATUS products 会把受影响的分片显示为 degraded(一份副本离线,一份仍在线):
-- illustrative: node3 is down
+-------+-------+----------+----+-----------+
| shard | node | status | rf | rf_status |
+-------+-------+----------+----+-----------+
| 1 | node2 | active | 2 | degraded |
| 1 | node3 | inactive | 2 | degraded |
| 2 | node1 | active | 2 | degraded |
| 2 | node3 | inactive | 2 | degraded |
| ... | ... | ... | | ... |
+-------+-------+----------+----+-----------+
此时仍有两台活跃节点(node1、node2)且 rf=2,所以 master 会在缺少这些分片副本的活跃节点上创建分片 1 和 2 的缺失副本。在新副本构建期间,它会显示为 pending;一旦复制追上进度,就会变成 active,rf_status 也会恢复为 ok。
一个重要的注意事项:只有在有地方放新副本时,Manticore 才能恢复 RF。 如果活跃节点数降到 rf 以下,所请求的 RF 暂时无法满足:受影响的分片会保持 degraded,仅保留存活的副本,直到有节点返回或你添加新节点。Manticore 不会把同一分片的另一份副本创建在同一台节点上,也不会悄悄假装 RF 已满足。如果某个分片没有任何存活副本,它的状态会变成 broken;下面会讲这种情况。对于 rf='1',故障节点上的分片就直接丢失了,因为本来就没有第二份副本。
节点加入
新容量应该被利用起来。master 会重新均衡,让新节点承担一部分负载。具体方式取决于 RF:
- RF = 1: 分片必须被移动(因为只有一份副本,不能简单复制)。Manticore 会通过一个临时的内部集群安全地移动它们:先把数据复制到新节点,只有之后才从旧节点移除,所以分片始终都有一份可用副本。
- RF ≥ 2: 分片会先通过集群现有复制机制复制到新节点,然后再重新均衡分布。不会有高风险的数据迁移,因为总有另一份副本存在。
某个分片的所有副本都离线
如果持有某个分片的所有节点同时丢失,该分片的 rf_status 会变成 broken,因为已经没有可用副本来提供服务或作为复制源。表的其他部分仍然可以工作;当其某个节点返回时,损坏的分片就会恢复。RF 会降低这种情况发生的概率:在 rf='2' 时,需要两个“正确的”节点同时故障;在 rf='3' 时,需要三个。
所有这些都通过一个内部的、有顺序的、可回滚的操作队列完成,因此一次重新均衡操作要么完成,要么被干净地回滚,即使 master 节点在操作中途自身宕机,新的 master 也会清理半完成的工作。对你这个运维者来说,重点是:你只设置一次 RF,集群会努力保持它一直成立。
底层机制简述
使用分片并不需要了解这些,但知道背后在发生什么会更有帮助。
- 物理分片是真实表。 一张有四个分片的表,底下由四张真实表支撑,这些表由 Manticore 为你创建并管理。通常你不会直接碰它们。
- 你的应用与分布式表
交互。 Manticore 会在每台节点上创建一个名为
products的表。在它的内部定义里,本地分片会直接列出,而其他节点上的分片则通过agent连接。这就是SELECT … FROM products能透明命中所有数据的原因。 - 协调状态存在于集群中。 Manticore 会跟踪自己的内部元数据,包括分片放置、协调状态和待处理操作队列,因此它始终知道谁持有什么,以及还有哪些工作未完成。在多节点环境里,这些状态会在集群间复制,所以每台节点看到的是同一份视图。
- master 驱动变更。 放置、复制建立和重新均衡都由 master 计算,并以带回滚说明的有序命令入队,然后在各节点上执行。
- 复制复用了 Manticore 的集群机制。 Manticore 已经用于集群的那套成熟复制机制,会用来保持分片副本同步。
从架构上看:
CREATE TABLE ... shards='4' rf='2'
│
▼
┌────────────────┐
│ Manticore │ computes placement,
│ elected master │ enqueues ordered ops
└────────┬───────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ node1 │ │ node2 │ │ node3 │
│ s0 s2 s3 │◄───►│ s0 s1 s3 │◄───►│ s1 s2 │ (each shard on 2 nodes = rf 2)
└──────────┘ └──────────┘ └──────────┘
distributed table "products" exists on every node
(same placement as the SHOW SHARDING STATUS output above)
运维分片表
你期望能正常工作的都能正常工作,而且还有几条专门针对分片的可见性命令。
查看表结构。 DESC 和 SHOW CREATE TABLE 可以作用于逻辑表;Manticore 会通过底层分片解析它们:
DESC products;
SHOW CREATE TABLE products;
查看每个分片在哪里,以及 RF 是否健康。 这是故障和重新均衡期间你要重点关注的命令:
SHOW SHARDING STATUS products;
+-------+-------+--------+----+-----------+
| shard | node | status | rf | rf_status |
+-------+-------+--------+----+-----------+
| 0 | node1 | active | 2 | ok |
| 0 | node2 | active | 2 | ok |
| ... | ... | ... | | ... |
+-------+-------+--------+----+-----------+
它会为每个分片副本输出一行,包含这些列:
| 列 | 含义 |
|---|---|
table | 逻辑表名 |
shard | 分片编号 |
node | 持有该副本的节点 |
status | active、inactive(节点离线)或 pending(正在创建) |
cluster | 该表所属的复制集群 |
replication_cluster | 保持该分片副本同步的内部集群 |
rf | 该分片当前拥有的副本数 |
rf_status | ok(RF 满足要求)、degraded(部分副本离线但至少有一份在线)或 broken(没有副本在线) |
rf_status 是一眼可见的健康信号:全部是 ok 表示集群正在满足你要求的复制因子;degraded 表示系统还能工作但处于暴露状态;broken 表示某个分片已不可用。
找到协调者:
SHOW SHARDING MASTER;
干净地删除它。 删除分片表的方式和删除普通表完全一样 - DROP TABLE 会删除该表以及它在整个集群中的所有分片:
DROP TABLE products;
通过改变集群来扩容。 由于重新均衡是自动的,扩展分片表的方式就是向集群添加节点(添加新节点 )。master 会发现新节点并自动把负载重新均衡过去,而不需要对表本身做任何操作。
如何选择分片数和复制因子
这里有一些经验法则:
- 为了更快写入而分片: 少量分片通常就足够了,而且应该远低于核心数——在下面的基准测试 里,一台 16 核 / 32 线程机器在 4–8 个分片 时达到峰值,而到 32 个分片时反而比完全不分片更慢。从小开始(4–8),先测量,只有你的实际数据证明有必要时再增加。更多分片通常没什么帮助,反而会增加每个分片的开销。
- 为了分发而分片: 在多节点场景下,你希望分片数量足以让它们在节点间均匀分布,并且为增长留出空间,因此最好是节点数的倍数。不要过度增加:每个分片都是真实表,带着自己的开销。(Manticore 将分片数上限设为 3000。)
- 为了持久性而选择 RF:
rf='2'是标准生产选择,它能在 2 倍存储开销下承受任意一台节点故障。只有在你确实需要承受同时故障,或有严格可用性要求时,才使用rf='3',并记住它会带来 3 倍存储和更多复制流量。 - RF=1 只适合性能或一次性数据。 它没有容错能力。可在单节点上用于并行,或者在集群中仅当你有外部方式重建丢失数据时使用。
基准测试:分片真的能加快插入吗?
只有真正有价值的功能才值得用,所以我们做了测量。我们想要诚实回答的问题是:在相同负载下,分片能否加快数据摄取 - 如果能,什么时候有效? 方法很简单:把每一次分片运行都和同一个基线对比,也就是不分片的普通表。
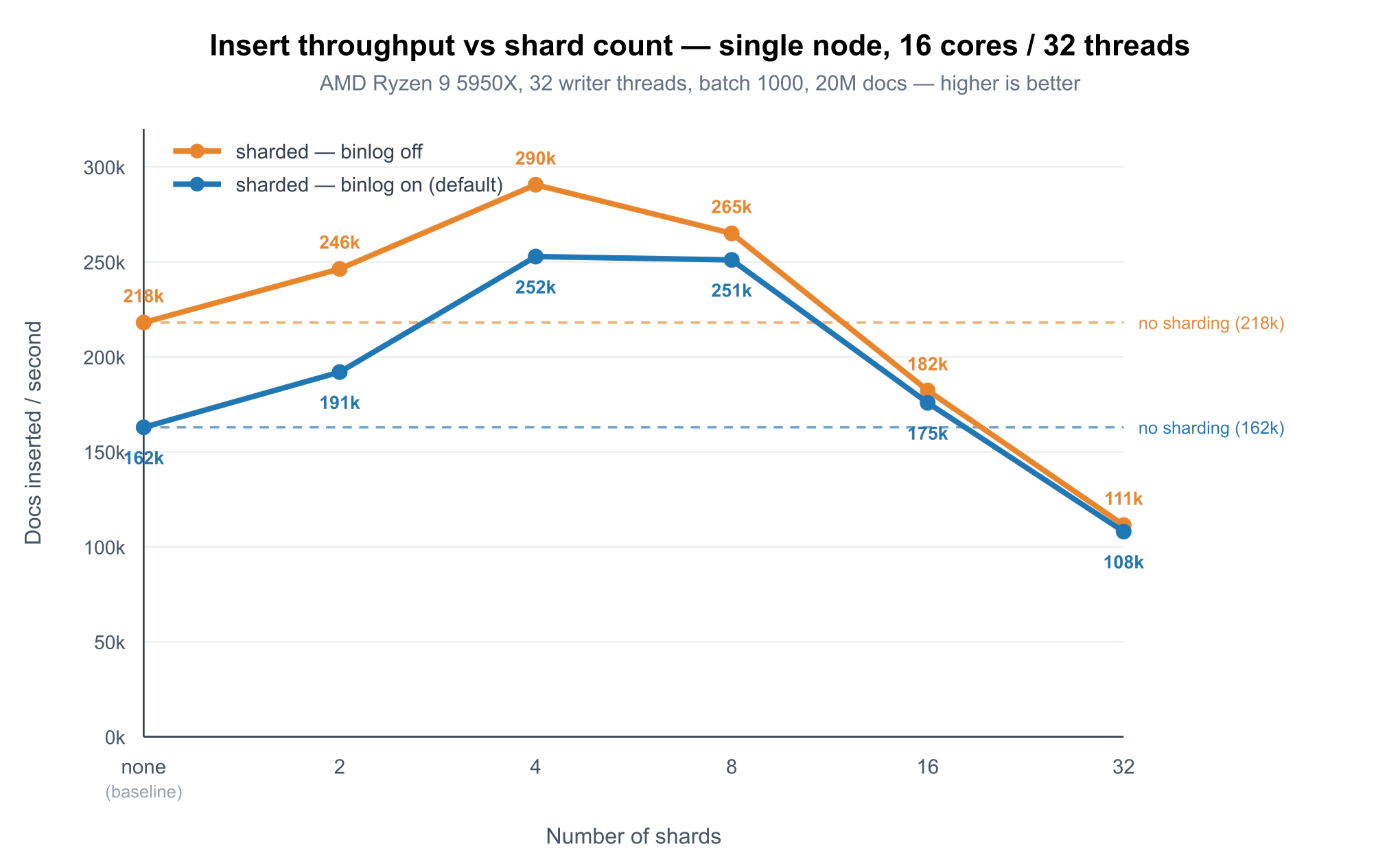
简而言之: 在一台 16 核机器上配 32 个并发写入者时,分片最高把插入吞吐量提升了约 1.5 倍 - 从约 163k 提升到约 253k docs/s - 但前提是分片数量保持较小。最佳结果出现在 4–8 个分片;到了 32 个分片时,吞吐量已经低于未分片基线。二进制日志大约消耗了 25% 的写入性能,而跨两台真实机器的 rf=2 复制又多消耗了约 30%,这对于持久性来说是合理代价,但并非没有成本。
环境。 一台没有其他明显 CPU 负载的专用服务器 - AMD Ryzen 9 5950X(16 核 / 32 线程)、128 GB RAM。所有测试都在一个运行了包含分片特性的近期开发版的单个 Docker 容器里完成。Manticore 使用默认设置 - 没有性能调优:只配置了监听端口、数据目录和二进制日志路径;线程池、RT 内存限制和二进制日志行为都保持默认。负载来自 manticore-load
。每次运行都会把相同文档 - (id bigint, name text, type int),其中 name 是 10–100 个随机单词 - 以 1000 条一批写入一张实时表。不同运行之间只改变分片数、复制因子和二进制日志;“不分片”基线是一张普通 RT 表。我们把完整的单节点分片扫描跑了两次 - 一次开启二进制日志(默认),一次关闭 - 每次插入 20,000,000 条文档,并发写入者为 32。
# the exact shape of every insert run (shards/rf vary)
manticore-load --batch-size=1000 --threads=32 --total=20000000 \
--init="create table test(id bigint, name text, type int) shards='8' rf='1'" \
--load="insert into test(id,name,type) values(<increment>,'<text/10/100>',<int/1/100>)"
单节点:吞吐量与分片数

每秒插入文档数,2000 万条文档,32 个写入者 - 两种二进制日志模式:
| 分片数 | 二进制日志开启(默认) | 二进制日志关闭 |
|---|---|---|
| none (baseline) | 162,920 | 218,079 |
| 2 | 191,976 | 246,288 |
| 4 | 252,807 | 290,665 |
| 8 | 251,008 | 265,015 |
| 16 | 175,848 | 182,288 |
| 32 | 108,006 | 111,381 |
图表把完整扫描画了两次 - 二进制日志开启(蓝色,默认)和关闭(橙色)。有三点特别明显:
- 并发插入有真正的提升。 在 32 个写入者下,拆分表后吞吐量在峰值时提升了 约 1.5 倍 - 默认(二进制日志开启)曲线从 163k 提到 253k docs/s。每个分片都是独立的实时表,所以把写入分散到多个分片上能显著减少单张 RT 表在高并发下遇到的锁争用,并让插入利用更多核心。
- 最佳范围很小 - 4–8 个分片。 收益在这里达到峰值,随后很快下降。到 16 个分片时只比基线略好,而到 32 个分片时吞吐量已经低于未分片表(0.66×) - 超过这个范围后,每个分片和协调开销会压过额外并行带来的收益。更多分片绝对不是更好。两条曲线的形状相同,最佳范围也相同 - 二进制日志并不会改变这一点。
- 持久性的成本在你最快的时候最明显。 关闭二进制日志(橙色)会抬高整条曲线,但差距在高吞吐区最大 - 4 个分片时 253k → 291k - 而当分片数过高时几乎消失(32 个分片时 108k vs 111k),此时瓶颈是协调开销,而不是持久性。二进制日志的影响我们会在下面单独测量。
有一点需要明确说明:这种加速来自并发写入。单个严格串行的写入者无法利用并行分片,因此不会有加速,反而会多一点分布式层开销。分片真正适合的是多个客户端或消费者同时写入的情况,这也是现实中的摄取管道通常会遇到的。
持久性的代价:二进制日志
Manticore 的二进制日志让插入具有崩溃安全性(在非正常关闭后可以重放未刷盘的事务)。它默认开启。你已经能从上面的图里看到它的成本 - 橙色(二进制日志关闭)曲线高于蓝色曲线。只保留 binlog_path 变化,在普通未分片基线上隔离它的影响:

关闭二进制日志后,基线吞吐量从 162k 提升到 218k docs/s - 所以崩溃安全插入大约要付出 25% 的成本。这就是在硬故障时不丢失未刷盘写入的代价;除非你能从源数据重建,并且希望在批量导入期间获得额外速度,否则生产环境应保持开启。
复制对写入的成本
跨机器的持久性同样不是免费的 - 而且这也是唯一一个必须在真实、独立硬件上做的测试。所以和上面的单节点基准不同,我们把两个复制测试跑在了两台不同的物理机器上:两台 4 核 / 7 GB 的云主机组成一个 Manticore 集群。这样 rf=1 和 rf=2 就不会争用同样的核心或内存 - 这是单机根本无法提供的公平比较。
rf=1 在一台机器上保留一份副本;rf=2 则在两台机器上都保留完整副本,因此每次插入都会在确认前通过网络同步复制。相同的 100 万条文档负载,4 个写入线程:

复制大约消耗了30% 的插入吞吐量(112k → 78k docs/s) - 这就是在 ack 之前把每次写入复制到第二台机器上的代价。一个数字就能说明 rf 的权衡:写得稍慢一些,换来整台机器故障后仍能存活。
分片和复制会加速读取吗?
读取很容易测错,所以先说方法。一个非常简单的查询 - 取 20 行,不做排序 - 执行时间远低于 1 毫秒,因此它的成本全是固定开销;一个跳转到 agent 的分布式表在这里看起来会慢约 3 倍(这里约 7,700 vs 2,400 q/s),纯粹是因为网络往返远大于几乎为零的工作量。这不是真实查询。一个更贴近现实的全文检索查询(匹配并排序少量词项,约 10–30 ms)才会告诉你真相:分发开销会缩小到几个百分点,因为真正的工作开始主导固定成本。下面的数字都使用了 2 节点集群上的真实查询,并从单个入口节点发起读取。
# realistic read — what the numbers below use: full-text match-and-rank, ~10–30 ms each
manticore-load --threads=4 --total=5000 \
--load="select id from <table> where match('<text/1/5> <text/1/5>')"
# trivial read — sub-ms, all fixed overhead, exaggerates distributed cost ~3x
manticore-load --threads=4 --total=20000 \
--load="select id from <table> limit 20 option ranker=none"
<table> 是以下三者之一:普通 RT 表(不分片),一个跨本地分片的 type='distributed' 表(单节点分片 - local='s0' local='s1' …),或一个 shards='4' rf='1'/rf='2' 的分片表。每次读取都只发往一台节点 - 我们从不把两台节点当成两个独立客户端分别查询。

- 跨节点分片能加快读取。 一个跨两台机器分布的 4 分片
rf=1表,吞吐量达到 约 516 q/s,而单个未分片节点约 315 - 大约 1.6 倍 - 因为每个查询会同时利用两台节点的核心。 - 复制不会拖慢读取。
rf=2(每个分片在两台节点上都有副本)大约 410 q/s,略低于rf=1。原因不是负载粘在一台节点上(它会在副本之间分散),而是rf=2时每个分片都要通过 agent/mirror 路径访问 - 即使是恰好本地的副本也是如此 - 而这条路径会带来上面提到的几个百分点开销;相比之下,rf=1会在进程内直接读取本机上的分片。无论哪种方式,读取都明显快于单节点,而且数据现在可以在机器故障下继续存活。 - 在一台机器上,分片对读取的提升很小。 把一张表拆成 2–4 个分片,在单节点上只会增加约 5–12% 的收益(查询并行化),而且还得有空闲核心才行 - 更重的查询收益更明显(约 12%,而轻查询约 3%),但满载机器基本看不出差异。真正的读取扩展来自增加机器,而不是在一台机器上继续加分片。
方法说明:读取和复制测试运行在另一对云主机上 - 每台 4 vCPU / 7 GB RAM,两台不同的物理机器 - 它们组成一个 2 节点 Manticore 集群,使用相同的近期开发版和默认设置,数据量为 150 万条文档。这是一套与上面用于插入扫描的 16 核 / 32 线程服务器不同、且弱得多的环境,所以结论只能在各自测试内部比较,不要跨测试直接对比。核心数较少也解释了为什么这里单节点分片的读取收益较小 - 可供查询并行化的空闲核心不多。
结论
- 在单机上,分片能带来 约 1.5 倍的并发插入加速(这里 20M 负载下为 163k → 253k docs/s)。
- 在这颗 16 核 / 32 线程 CPU 上,最佳范围是 4–8 个分片。分片太多会变慢:到 32 个分片时,吞吐量已经低于未分片基线。分片数应与核心数和写入并发匹配,而不是追求一个漂亮的大整数。
- 二进制日志会消耗约 25% 的写入吞吐量(并且当分片数过高时差距会缩小到接近零),而**
rf=2复制会消耗约 30%** 的写入吞吐量(在两台独立机器上测得) - 这分别是为崩溃安全和节点故障存活付出的合理代价。 - 对于真实的全文检索查询,在 2 节点集群上分片可把读取提升到单节点的 约 1.6 倍,而
rf=2能在保持读取高性能的同时承受节点丢失。简单的 id 查询会把分布式开销夸大约 3 倍 - 评测读取时一定要使用真实查询。 - 绝对数值取决于硬件和文档形态;能迁移到其他环境的是这些曲线的形状 - 所以在确定分片数之前,先对自己的负载做基准测试。
限制与注意事项
有些边界条件需要提前知道:
rf是必填项。 分片版CREATE TABLE必须指定rf=。如果省略,CREATE TABLE会失败。- 大于 1 的
rf需要集群。 你不能在单机上创建多副本分片表,因为没有地方放副本。多副本表必须使用cluster:name形式。 - 已经在集群中的节点上不能创建本地分片表。 如果某个节点属于复制集群,请在该集群内部创建表(
CREATE TABLE cluster:name …),而不是作为本地表创建,否则分片元数据不会被正确跟踪。Manticore 会检测到这一点并提醒你。 - 每张表最多 3000 个分片。
- RF=1 没有容错。 丢失某个节点,它的分片就没了。这是设计权衡,不是 bug - 这就是你选择
rf='1'时接受的代价。 - 至少需要 RF 台节点。
rf='M'要求集群中至少有M台节点;否则创建会失败。 - 创建是同步的,直到超时为止。
CREATE TABLE会等待分发完成(默认 30 秒)。如果分片数非常大,可以用timeout='N'(秒)把它调高,例如shards='3000' rf='3' timeout='60'。
这意味着什么
Manticore 中的分片用一个刻意简洁的接口覆盖了很宽的场景。在单机上使用 shards='N' rf='1' 时,分片会把并发写入分散到彼此独立的部分上,并让每一部分保持足够小。在集群内部使用 shards='N' rf='M' 时,它会给你一张分布式、可复制的表,能够在节点故障时继续存活,并在集群变化时自动重新均衡,而你不需要写一行故障切换逻辑。同一份表定义可以从一台节点扩展到多台节点,而你的应用始终用同样的方式与它交互。实际上,这意味着你可以先在单节点上提升写入吞吐量,之后再平滑迁移到一个具备容错能力的集群,而无需修改应用。
想更深入了解分片所依赖的基础构件:
如果你有关于分片的问题,或者有想让我们做基准测试的负载,告诉我们 。