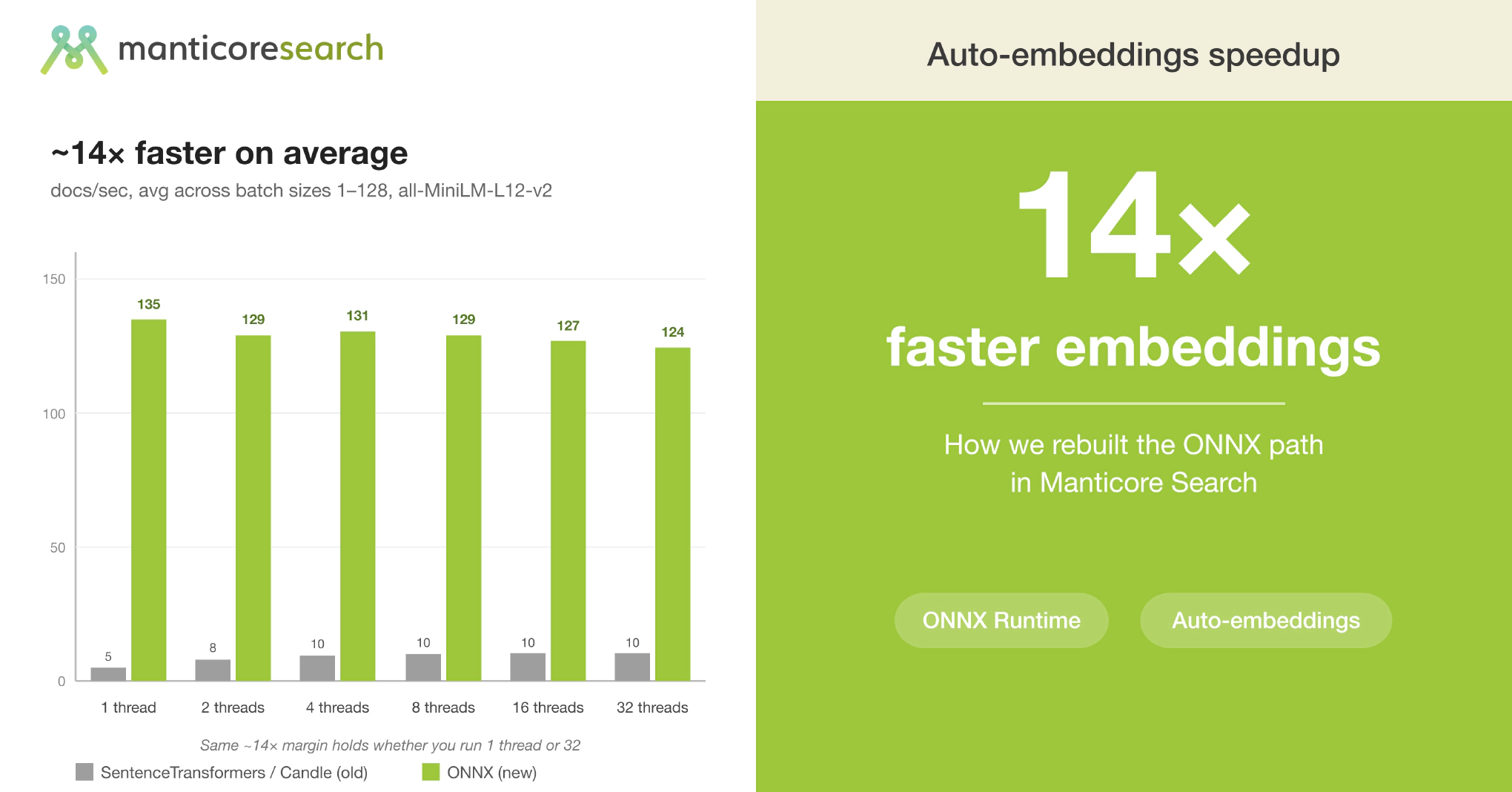

当我们发布 Auto Embeddings 时,这个功能可以把任意文本列自动转换成向量,而且无需单独运行模型服务。最常见的反馈就是速度。之前的路径是先通过 SentenceTransformers,再建立在 Candle 之上,Candle 是 Hugging Face 的纯 Rust ML 推理运行时,它把大量 CPU 性能白白浪费了:无论我们怎么喂数据,大多数负载都只能跑到每秒十几篇文档的低位区间,而且并发调用还会在单个模型会话上串行化。
所以我们花了几周时间重构 Manticore 运行 ONNX 模型的方式。新的 ONNX Runtime 后端已随 Manticore Search 27.1.5
发布。ONNX(Open Neural Network Exchange)是一种可移植的模型格式,大多数流行的开源 embedding 模型,比如 MiniLM、BGE、E5 以及其他同类模型,早已发布为这种格式。结果就是,这个后端在相同硬件上(平均来看是廉价的 16 核 / 32 线程服务器)、相同模型、相同权重、并在完整的 threads × batch 工作负载网格上求平均后,比之前的 SentenceTransformers/Candle 路径平均快约 14 倍,而且无论你运行 1 个客户端线程还是 32 个,这个优势都成立。旧路径在整个网格中一直停留在 5–11 docs/sec 区间;新路径则处在 70–230 docs/sec 区间。
这篇文章就是这次工程实践的记录:我们尝试了什么、哪些结果出人意料、哪些方案被我们舍弃了,以及最终设计长什么样。
TL;DR
- 平均比之前的 SentenceTransformers/Candle 路径快约 14×,这是在同一台机器(16 核 / 32 线程)、相同模型、相同权重下,跨完整
threads × batch工作负载网格(1 / 2 / 4 / 8 / 16 / 32 线程 × 批大小 1…128)得到的平均结果。 - 随 Manticore Search 27.1.5
发布的新 ONNX 路径,现在已成为任何带有
.onnx文件的 HuggingFace 模型的默认高速路径。 - 在
all-MiniLM-L12-v2上,旧的 Candle 路径在我们尝试的每一种配置下都稳定在 5–11 docs/sec。新的 ONNX 路径则落在 70–230 docs/sec 区间里,而且 无论你跑 1 个客户端线程还是 32 个,这个约 14× 的差距都成立。 - 我们测试机上的单次插入延迟:单客户端时约 14 ms,在 8 路并发负载下约 56 ms,都远低于 Candle 当时的 200+ ms。
- 想要最高的批量导入吞吐量? 用 单个客户端线程 配合 较大的批大小(32–128)。新的后端会在调用内部并行化,所以客户端侧再做多路分发只会叠加协调开销。我们这台机器上的峰值是 1 线程 + batch=64 时 233 docs/sec。
- 最关键的两个变化:把
intra_op_spinning关掉,以及放弃在 worker 内部对文档做批处理。 - 没有面向用户的 API 变更。已经指向支持 ONNX 的
MODEL_NAME的表会自动走新路径。把现有表切换到另一个模型并不是一行命令就能完成的事 - Manticore 不允许直接修改FLOAT_VECTOR字段上的MODEL_NAME- 但你也不必重建整张表:你可以在旁边新增一个使用新模型的列,重新生成它的嵌入,然后删除旧列。
为什么这很重要
在自动嵌入模式下,数据库会在每次 INSERT 时自己运行模型。这意味着嵌入速度 就是 INSERT 速度 - 你的导入吞吐量完全取决于嵌入步骤能跑多快。
旧的 SentenceTransformers/Candle 路径把性能留在了桌面上。并发会撞上锁竞争,批量调用会因为填充开销而进入平台期,而在两次调用之间,运行时又会以一种阻止下一次调用接上上一次工作的位置暂停线程。最直观的症状很简单:无论你怎么折腾,top 都会显示整台机器远未满载。整个扫描范围 - 单行 INSERT、128 行批量 INSERT、1 个客户端线程、32 个客户端线程 - 都停在 5–11 docs/sec,因为你怎么喂它都榨不出更多 CPU。
新的 ONNX 路径把下限抬高了一个数量级,而且还给用户提供了有意义的性能调优空间。现在单线程、单行 INSERT 已经能达到 72 docs/sec - 这本身就比旧 Candle 上限高了约 7×。再加上并发或批大小后,它会提升到 130–230 docs/sec 区间,而整个网格的最高点是在 单客户端线程、--batch-size=64 时的 233 docs/sec。在整个 threads × batch 矩阵上取平均后,新路径大约是旧路径的 14×。
为什么选 ONNX,而不是 Candle
Manticore 的嵌入库已经支持几种后端有一段时间了。Candle 路径在正确性和易发布性方面都很不错。但对于 MiniLM 和 BGE 这类小型 encoder 模型的生产级推理,ONNX Runtime 很难被超越:
- ONNX Runtime(或 ORT - 微软官方的、经过手工调优的 ONNX 模型 C++ 推理引擎)会做图融合、常量折叠和 kernel 自动调优。
- HuggingFace 上大多数流行的嵌入模型已经在它们的
onnx/目录里发布了预融合的model.onnx。磁盘上的文件本身就已经是 ORT 想要的形态。
在相同的 all-MiniLM-L12-v2 权重、CPU 上,ONNX 路径相较 Candle 路径有明显提升。质量相同,但每篇文档需要做的工作少得多。
ORT 会用一组我们有明确取舍的配置来创建 session:
let session = ort::session::Session::builder()?
.with_optimization_level(GraphOptimizationLevel::Level3)?
.with_intra_threads(0)? // let ORT pick (= all cores)
.with_intra_op_spinning(false)? // do NOT busy-wait between calls
.with_flush_to_zero()? // kill denormals on attention softmax
.with_approximate_gelu()? // ~10% faster activation, no quality loss
.commit_from_file(&onnx_path)?;
其中大多数都没什么争议,属于“当然应该打开”的开关。只有一个不是:intra_op_spinning(false)。后面我们会回到它 - 它是整个分支里最大的提升,而且严格来说这甚至不算 ORT 的设置,更像是负载形态的决策。
并发模型 - 大多数读者会觉得新鲜的部分
如果你对 Rust 开发者说“让 ONNX 跑快一点”,又不给其他约束,他们通常会走两种模式中的一种。我们都试过了。对这个负载来说,它们都不对。
模式 1:一个共享的 Session,外面套一个 Mutex(Mutex 是一种锁,同一时间只允许一个线程访问 session)。这很容易推理,也很容易写对。但在并发下吞吐量会崩掉,因为每个调用都会在锁上串行化。做 CLI 工具还行,给一个要同时服务很多 INSERT 的数据库就很糟糕。
模式 2:session 池,每个 CPU 一个 Session。 不再有锁竞争,但冷启动时间会成倍增加,内存占用也会成倍增加,而且小输入为了落到某个 session 上还要额外付出分发成本。我们在一个开发分支里做出了一个可工作的版本,但它始终差那么一点没能真正跑起来。
真正解锁这个设计的,是大多数 Rust ONNX 封装都会搞错的一点:在 Linux 和 macOS 上,ORT 的 C Run() API 是线程安全的。 你可以让很多并发调用者共享同一个 Session,而不需要任何加锁。C++ 那一侧已经会把需要串行化的部分串行化了;Rust API 只是用借用检查器规则把它包起来,而这些规则并不符合底层库实际上允许的行为。
所以我们把 session 包装成了一个带平台感知的小类型:
#[cfg(not(target_os = "windows"))]
struct SessionWrapper {
inner: std::cell::UnsafeCell<ort::session::Session>,
}
#[cfg(not(target_os = "windows"))]
unsafe impl Sync for SessionWrapper {}
#[cfg(not(target_os = "windows"))]
unsafe impl Send for SessionWrapper {}
impl SessionWrapper {
fn with_session<R>(&self, f: impl FnOnce(&mut Session) -> R) -> R {
f(unsafe { &mut *self.inner.get() })
}
}
是的,这里用了 unsafe。我们把借用检查器从链路里拿掉了,因为底层库已经文档化说明,在我们使用的访问模式下它是安全的。这是一个有意为之、带一句话理由的 unsafe,不是埋雷。
在 Windows 上,ORT 的线程模型存在已知问题,所以我们用 Mutex 把 Run() 串行化。重要的是,这把锁持有的是 整个 closure,而不只是 run() 调用本身 - 这正是我们在 Windows 上看到的竞态的修复方式:一个线程的 SessionOutputs 还在被读取时,另一个线程已经开始了新的 run()。是按 closure 加锁,不是按调用加锁。
自适应并行 - 我们走过的弯路
这部分工作花的时间最长,因为每一本教科书都会说“要让 ONNX 跑快,就把输入做成批”。所以我们最初的尝试也照着教科书来。
我们一次对 8、16、32 篇文档做分词,把它们填充到 max_len,然后每个 worker 线程跑一次前向推理。结果吞吐量反而比把同样的文本一条条送进同一个 session 还低。我们又跑了一遍。结果一样。我们花了一阵子试图推翻这个结论,最后才接受它。被回滚的提交 980b24b "Revert: perf(model): batch inference in worker threads",就是我们停止硬拗、开始围绕 profiler 提示重建的那个时刻。
这个意外背后有两个原因。
填充成本。 一个长度混合的文本批次,会把每一行都填到最长那一行的长度。然后模型做的工作量就与 batch_size * max_len * hidden_dim 成正比,而不管这个批次里真正有多少内容。真实文本输入的长度变化非常大:一个包含 8 句随机句子的典型批次,可能只有 1 个 60 token 的长尾样本,其余 7 行都只有 8 token。模型的大部分周期都在拿填充 token 去乘 attention weight。对于单文档批次,模型只会按照该文档实际 token 数量来工作。按每篇文档计算,在输入长度方差真实存在时,“不做批处理”反而比“做批处理”更便宜。
自旋。 ORT 的 intra-op 线程池默认会在调度间隙里 自旋 - 线程在一个紧循环里烧 CPU,等待下一块工作。对于一个 session 调用里的一大批任务,这几乎看不出来:线程一直在做真实工作。但在很多并发的小调用场景里,这会变成灾难:每个 worker 的 intra-op 线程池在调用之间都会把 CPU 钉在 100%,而且没有多余 CPU 留给别的事情。我们在 top 里看到了完全一样的模式:每个核心都 100%,但关闭自旋后吞吐量反而更低。这听起来不合理,直到你记起系统的其他部分也需要 CPU 时间 - tokenizer、HNSW 构建、以及 searchd 的其他工作。打开 with_intra_op_spinning(false) 只是改一行代码,却立刻同时提高了吞吐量并降低了 CPU 使用率。
所以最终形态和教科书式配方正好相反:
- 一个共享 session,不要池。
- 一次推理调用只处理一篇文档,worker 内部不做批处理。
- 很多并发调用者,按 CPU 数量扩展。
- 调用之间不自旋 - 像个有礼貌的公民一样把 CPU 让出来。
fn predict_pipelined(&self, texts: &[&str]) -> Result<Vec<Vec<f32>>, _> {
let bs = batch_size();
// Small input — single tokenize + infer, no thread overhead.
// This is the path a 1-doc INSERT takes.
if texts.len() <= bs {
return Self::tokenize_and_infer(&self.session, &self.tokenizer, texts, ...);
}
// Large input — split across workers, each running 1-doc-at-a-time
// through the SHARED session. This deliberately mimics the
// many-concurrent-callers pattern that ORT is happiest with.
let num_workers = (texts.len() / bs).min(available_cpus()).max(1);
let docs_per_worker = texts.len().div_ceil(num_workers);
std::thread::scope(|s| {
for worker_texts in texts.chunks(docs_per_worker) {
s.spawn(move || {
for text in worker_texts {
Self::tokenize_and_infer(&session, &tokenizer,
std::slice::from_ref(text), ...)?;
}
Ok(())
});
}
});
// ...
}
这种双分支设计是刻意为之的。一个 1 行 INSERT 进来时,texts.len() == 1,也就是 <= bs,所以它会走快路径,零线程创建、零通道发送、零协调开销。而一个带成千上万行的 bulk REPLACE INTO 会走并行分支,从而拿到吞吐量收益。便宜的场景保持便宜,昂贵的场景保持并行。
我们还在启动时一次性开启了并行分词(TOKENIZERS_PARALLELISM=true),并在进入 BPE 之前先按字符数预截断输入,这样一大块 100KB 的文本不会在模型看到它之前就先把 tokenizer 的一个 CPU 核心卡上一秒。
数据
所有运行都在我们的标准基准机上完成,使用 all-MiniLM-L12-v2-onnx,每轮 1000 篇文档。由 manticore-load
生成:
manticore-load --quiet --drop --batch-size=1 --threads=8 --total=1000 \
--init="CREATE TABLE t (
f text,
v FLOAT_VECTOR KNN_TYPE='hnsw' HNSW_SIMILARITY='l2'
MODEL_NAME='onnx-models/all-MiniLM-L12-v2-onnx' FROM=''
)" \
--load="INSERT INTO t(f) VALUES('<text/10/100>')"
同样的命令,使用 --batch-size=2、8、32、128,全部在 8 线程下运行:
--batch-size | docs/sec | 平均调用延迟 (ms) | 单文档延迟 (ms) |
|---|---|---|---|
| 1 | 143 | 55.9 | 55.9 |
| 2 | 113 | 141.6 | 70.8 |
| 8 | 91 | 703.3 | 87.9 |
| 32 | 146 | 1753.4 | 54.8 |
| 128 | 147 | 6966.0 | 54.4 |
和同样 8 线程下的 Candle 相比 - 旧路径在所有批大小下都稳定在 10 docs/sec - 这意味着根据你选择的批次大小不同,吞吐量提升了 9× 到 15×。其中“平均调用延迟”这一列表示一次完整 INSERT 语句返回所需的时间,而不是单篇文档;如果除以批大小,单文档成本会落在 55–90 ms 区间。
如果把表切换到 1 个客户端线程 - 结果证明这才是批量加载的最优配置 - 数据还会继续上升:批大小为 1 / 2 / 8 / 32 / 64 / 128 时分别是 72 / 76 / 93 / 175 / 233 / 222 docs/sec。整个网格的峰值是 1 线程 × batch=64 时的 233 docs/sec,单文档延迟约 4.3 ms。
如何喂数据才能获得最高吞吐量
如果你要批量导入大量数据,并且想要最高的 docs/sec,做法很直接:从 单个客户端线程 发送大的 INSERT ... VALUES (..), (..), ... 语句(批大小 32–128),不要从很多线程发很多小 INSERT。新的后端已经在 调用内部 做了并行化(见上面的 predict_pipelined 代码),所以客户端侧再做多路分发,只会在 ORT 已经在做的事情之上叠加协调开销 - 这就是为什么 1 线程 × batch=64(233 docs/sec)会明显胜过 8 线程 × batch=128(147 docs/sec)。
如果你的负载天然就是一次一行 - 比如 Web 请求、队列消费者、MCP 服务器 - 直接用 INSERT INTO 就行。单线程 / 单行的 72 docs/sec 下限已经比旧 Candle 路径快了约 7×,而且延迟低到你已经不需要再围绕这一层去优化了。
全网格的前后对比
为了把前后差异讲得更具体一些,我们还在同一台机器、相同权重下,把旧 Candle/trans 路径也按完整的 threads × batch 网格扫了一遍:

每个 X 轴刻度都是 backend threads/batch-size。左半部分(trans …)是旧的 Candle 路径 - 无论线程数多少、批大小多大,docs/sec 都始终停在 5–11 之间,而 CPU 已经被钉满。右半部分(onnx …)是新路径 - 在整个扫描范围内,docs/sec 都高出一个数量级。新路径内部:在小批次下,增加客户端线程有帮助(1T/batch=1 = 72 → 8T/batch=1 = 143);在大批次下,单个客户端线程反而更强(1T/batch=64 = 233 是全局峰值)。

同样的扫描,但把效率(docs/sec / CPU 百分比)和 docs/sec 放在一起看。Candle(trans)那边,两条线都贴着底部走 - 机器在烧 CPU,却没有产出文档。ONNX(onnx)那边,在 1–2 线程、配合中等批大小时效率最高,每消耗 1% CPU 能换来最多的嵌入,而且即使把线程数一路加到 32,它也依然远高于旧路径。
接下来做什么
还有几项工作排在这之后:
- GPU 路径。 目前的 ONNX 配置还是纯 CPU。
_use_gpu参数已经透传进来了,但还没有接到 ORT 的 CUDA execution provider 上。 - Windows 性能对齐。 目前因为一个 ORT 线程 bug,我们在 Windows 上还是串行化运行。等这个 bug 在上游修好后,Windows 也应该能获得 Linux/macOS 已经拥有的共享 session 行为。
- 让更多架构走 ONNX 路径。 现在 ONNX 只用于 BERT 家族 encoder。T5、causal-LM 和量化 GGUF 模型目前仍然走 Candle。
试试看
如果你现有的表已经指向一个支持 ONNX 的模型,那么在升级到 Manticore Search 27.1.5 或更高版本后,新路径就会接管处理,不需要改 schema,也不需要重新导入数据。你应该只会看到 INSERT 变得更快。
如果你还没用 ONNX 模型 - 或者你想换成更小 / 更快的模型来充分利用新后端 - 需要注意的是,你不能在现有字段上直接切换模型。Manticore 不支持修改现有 FLOAT_VECTOR 字段上的 MODEL_NAME,所以原地迁移不是选项。根据你的环境里哪个方案更顺手,你有两条实用路径可以选:
方案 A - 导出、修改、重新导入。 即使你已经没有原始源数据了,你也可以把现有表 mysqldump 到一个 SQL 文件里,编辑这个 dump 中的 CREATE TABLE,把 MODEL_NAME 指向你想要的 ONNX 优化模型,然后把 dump 回放到一张新表里。Manticore 会在导入时通过新路径为每一行重新生成嵌入。
方案 B - 在旁边新增一列,重建,然后删除旧列。 如果你更想停留在 SQL 里、避免 dump 往返,可以在同一张表上添加一个指向 ONNX 模型的新 FLOAT_VECTOR 列,然后从源文本对该列触发一次性重新生成嵌入:
ALTER TABLE t ADD COLUMN v_new FLOAT_VECTOR KNN_TYPE='hnsw'
HNSW_SIMILARITY='l2'
MODEL_NAME='Xenova/all-MiniLM-L6-v2'
FROM='text_field';
ALTER TABLE t REBUILD EMBEDDINGS v_new;
-- once you've cut over reads to v_new, drop the old column
ALTER TABLE t DROP COLUMN v_old;
具体语法和约束请参见文档中的 Rebuilding embeddings 一节。
如果是全新表,这些都不重要 - 直接从一开始就选择一个优化过的 ONNX MODEL_NAME 就行。
适合挑选 ONNX 就绪嵌入模型的好地方是 Hugging Face 上的 Xenova 集合
- 这些模型已经预先转换为 ONNX,可以直接放进 MODEL_NAME='...'。你可以按 feature-extraction 任务筛选,以缩小到嵌入类模型。下面是几个合理的起点:
Xenova/all-MiniLM-L6-v2- 小而快,384 维,默认首选。Xenova/all-MiniLM-L12-v2- 这篇文章里我们基准测试的模型,384 维,质量更进一步。Xenova/bge-small-en-v1.5- 英文检索能力强,384 维。Xenova/multilingual-e5-small- 多语言覆盖,384 维。
如果你还完全没用自动嵌入,最初的公告 会从头带你看 SQL。
📚 KNN search 文档
💬 Slack 社区
- 我们很想看看新路径在你的数据上表现如何。