# Replication: cluster creation, joining, updating table settings
Replication: creating a cluster, connecting a node, changing table settings and applying them to old documents
### 关于我
() values ()`。不要忘记在客户端中更新此命令。
让我们在新创建的节点中添加另一条记录:
```
insert into pet_shop:products (name, info, price, avl) values ('Aquarium ship', 'Decorative ship model for aquarium', 6, 1);
```
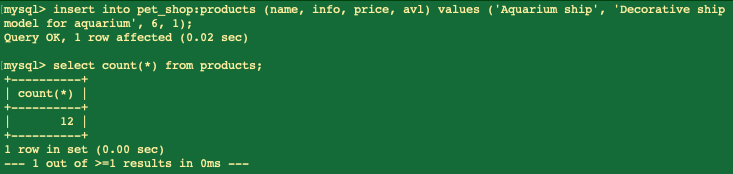
根据结果,记录已添加,但另一个节点呢?

这里一切也正常!
让我们尝试更新数据:
```
mysql> update products set price = 8.0 where id = 3317338896206921730;
ERROR 1064 (42000): table products: table 'products' is a part of cluster 'pet_shop', use 'pet_shop:products'
```
对于更新、更改和特别是删除记录,我们现在也需要在表名中指定集群名称:
```
update pet_shop:products set price = 8 where id = 3317338896206921730;
Query OK, 1 row affected (0.01 sec)
```
因此,数据现在在节点之间自动且无需太多复杂性地传输,除了写入命令的小改动。
#### 更改复制表的设置
如果我们需要更改表配置或删除它,例如更新词形文件,会怎样呢?在[上一篇文章](/blog/mike-replace-update-wordforms/)中,我们必须删除并重新创建表,导致用户在一段时间内无法获得服务器响应。在那个例子中,更新设置所需的时间非常短,因为表很小。但使用更大的数据集,例如包含数百万或数十亿条记录的表,更新和索引可能需要很长时间,通常以小时为单位。为了确保基于Manticore的应用程序服务不间断,有[分布式表](https://manual.manticoresearch.com/Creating_a_table/Creating_a_distributed_table/Creating_a_distributed_table),但我们将在另一篇文章中讨论这一点。
目前,我们有一个跨多个节点的复制数据库,其中包含`products`表。我们可以通过使用集群名称前缀来更改此表的配置,但即使使用前缀也无法删除它。要更改复制表的设置,首先需要将其从集群中分离:`ALTER CLUSTER DROP
`。这将仅从集群中删除表,而不是从数据库中删除。在表从集群中分离后,应用程序将无法更新数据,因为它引用了集群(例如,`insert into pet_shop:products ...`),而表不再在其中(应用程序应处理这种情况)。现在我们可以删除或重新配置表。
例如,让我们更新表配置:从词干提取器切换到词形还原器。以下是步骤:
* 将表从集群中分离。
* 将表中的形态学从词干提取器更改为词形还原器。
* 将数据重新加载到表中。
* 在集群中恢复表。
* 在第二个节点上检查。
从集群中分离表:
```
ALTER CLUSTER pet_shop DROP products;
```
现在,集群中所有节点上的表都已与之断开连接,其模式和设置可以修改。我们的工作逻辑意味着在一个节点上执行一些技术操作,而另一个节点则为用户提供`select`查询。作为一种保护措施,添加新记录将不再可能,因为应用程序使用`:
`格式的命令,而此表不再在集群中。
```
update pet_shop:products set price = 9 where id = 3317338896206921730;
ERROR 1064 (42000): table products: table 'products' is not in any cluster, use just 'products'
```
在我们从集群中分离表后,尝试执行`select`查询:
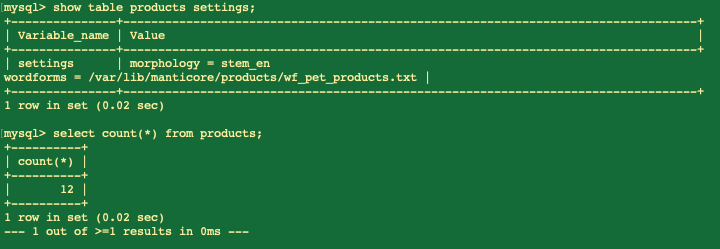
正如我们所见,查询已处理,数据已提供,最终用户应该感到满意。
现在,让我们将形态学从词干提取器更改为词形还原器,重新索引记录,并重新连接一切。在[上一篇文章](/blog/mike-replace-update-wordforms/)中,我们通过一些粗略的方法替换了词形文件和词干提取器。在这里,我们将使用更文明的工具。所有替换词形文件或更改表中使用的形态学的操作都可以通过一个命令完成:`ALTER TABLE
