大家好,
2025 年对 Manticore Search 来说是非常注重实践的一年。有很多“嗯,为什么这个在生产环境中这么慢”的时刻,有很多不那么炫酷的修复,以及持续推动引擎做更多事情,而不会让您的技术栈变成科学实验。
我们发布的“大功能”
- 向量搜索:索引选择、过滤、混合式设置,这些内容你只有在构建完一个之后才能学到( 阅读 )
- 自动嵌入:插入文本,获取向量,使用
knn()查询……无需额外嵌入流水线( 阅读 ) - 向量量化(及相关升级):更便宜的存储,更快的查询,需要时更多调节选项( 阅读 )
- 模糊搜索:实际产品搜索,即使有拼写错误也不会崩溃( 阅读 )
- 自动补全:简单启用,足够好用到可以发布( 阅读 )
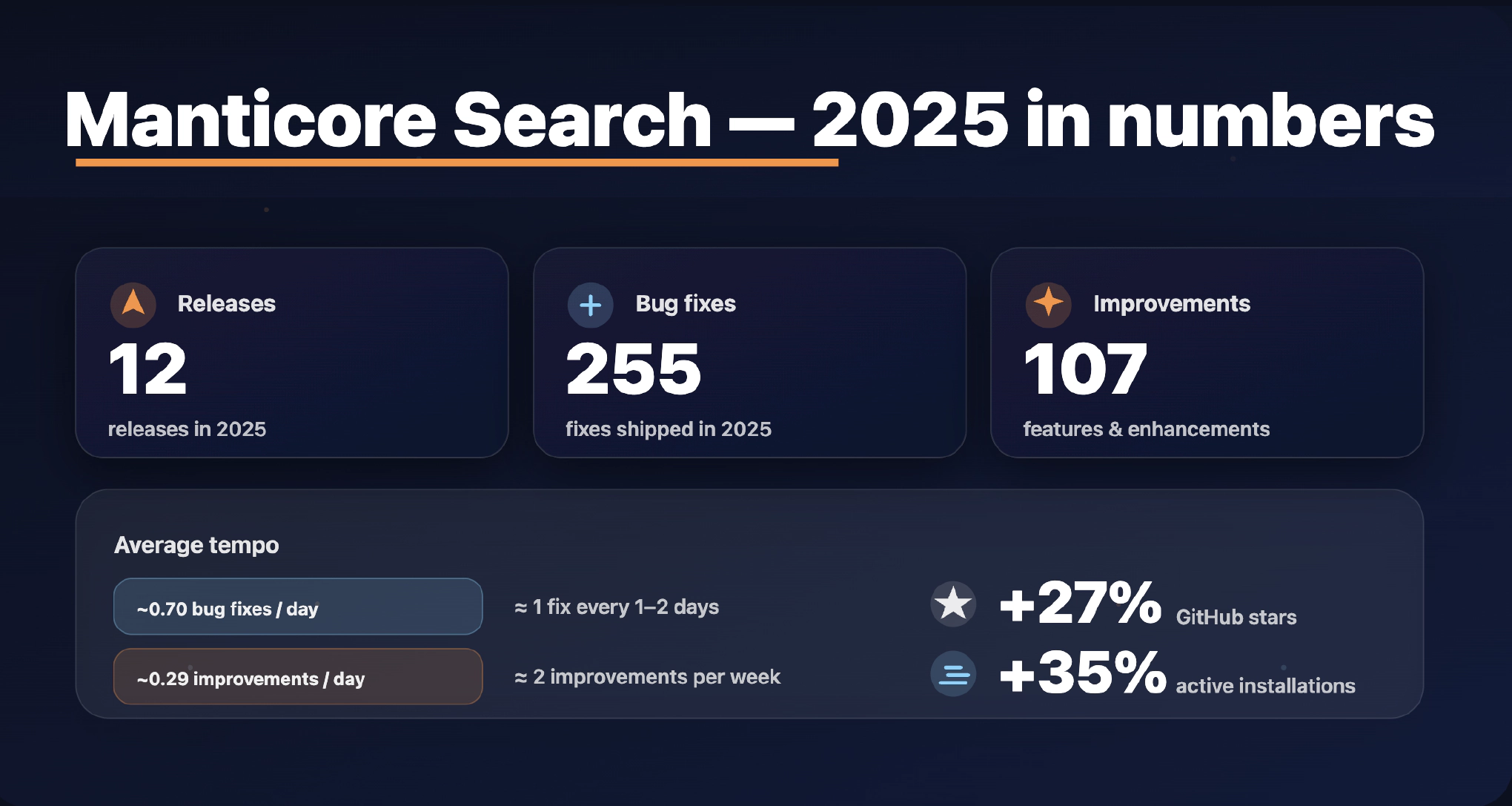
成绩单:
如果你喜欢“节奏”统计数据(我们有点喜欢):
- 每 1.4 天修复一个错误
- 每 3.4 天提供一个功能/改进
- 平均每天基本上有一个有意义的变更
真正重要的事情(对我们来说,也希望对你来说)
性能
- JSON 二级索引,用于更快的 JSON 重过滤(加上
secondary_index_block_cache,当你真的依赖它们时) - JOIN 批处理,对 JOIN 查询有显著加速
- 向量量化 (以及相关功能:重评分/过采样、存储更改)用于更便宜/更快的 向量搜索
- 自动 RT 磁盘块刷新——以及围绕它的更好可见性/日志记录——这样性能在负载下不会悄悄下降
易用性
- 自动嵌入生成 (那种“终于有了”的功能)
- 滚动分页 ,用于大结果集,无需奇怪的变通方法
- 模糊搜索 和 自动补全 ,只需简单启用
- 基于 Jieba 的 中文分词(因为没有正确分词,你会遇到“为什么这个不匹配”和“为什么它匹配了那个”)
- 内置
Prometheus 导出器
(以及
/metrics表现得像真正的 Prometheus 文本,而不是 JSON) - JSON HTTP API 中的 JOIN 支持
搜索质量与查询语言
- 显式的
|(OR) 在 PHRASE / PROXIMITY / QUORUM 内 ,这样高级查询不再感觉像变通方法 - boolean_simplify 默认启用(更干净的布尔查询,无需你去思考)
- HAVING 查询变得更友好:你可以直接获取总数,无需绕弯子
数据安全
LOCK TABLES支持,通过 mysqldump 实现更安全的逻辑备份- 复制升级:定期保存 seqno,集群加入时检查唯一的
server_id,SST 进度计量器
集成
- Kibana 集成 用于“发生了什么”的仪表板(以及 Kibana 演示中的真实性能故事: 阅读 )
- Kafka 数据摄入 ,用于将流数据导入 Manticore
- DBeaver 支持 用于基于 GUI 的工作流
其他内容
- 按表的使用统计和 计数器
JOIN ON与任意过滤表达式- 本地分布式表的 JOIN
2025 年我们发布的其他内容(如果你想深入了解,可以继续阅读)
- Manticore 负载模拟器 — 我们构建的用于基准测试/调优的工具,避免模糊的结果
- 使用 mysqldump 进行 Manticore Search 重新索引 — 重新索引 / 备份 / “如何在不引发停机恐慌的情况下安全移动数据”
- 关于 Manticore 的版本控制 — 我们的版本号含义以及升级时可预期的内容
- Manticore Search 与 Elasticsearch 对比:日志分析中 Kibana 仪表板渲染速度提升 3 倍 — Kibana 仪表板 + 日志分析,以及为什么渲染速度可能… 差异很大
- 理解 Manticore Search 中的分页 — 滚动分页、深度分页,以及当你有百万条结果时不应做的事情
- 将 Kafka 与 Manticore Search 集成:实时数据处理的逐步指南 — Kafka → Manticore 数据摄入,逐步操作
- 在短语、多数表决和邻近性中的 OR 运算符 — 小众功能,但一旦进入“高级查询”领域就会非常有用
❤️ 感谢所有对该项目进行星标、报告错误(尤其是那些烦人的错误)、分享反馈以及在生产环境中运行 Manticore Search 的人。如果你发送了帮助我们节省一天猜测时间的复现步骤:你就是最棒的。
— Manticore Search 团队