# Manticore Search: 3 years after forking from Sphinx
2017年5月,我们对Sphinxsearch 2.3.2进行了分叉,我们称之为[Manticore Search](https://github.com/manticoresoftware/manticoresearch)。下面您将看到关于Manticore Search作为Sphinx分叉的简要报告,以及我们自那时以来取得的成就。
# 为什么我们要分叉Sphinx?
---
首先,为什么要进行分叉?2016年底,Sphinxsearch的开发工作被暂停了。使用Sphinx的用户以及一些支持该项目开发的客户对此感到担忧,因为:
- 错误长时间得不到修复
- 长期承诺的新功能没有实现
- 与Sphinx团队的沟通中断
几个月后情况没有改变,2017年6月中旬,一群积极且有经验的Sphinx用户和支持客户聚集在一起,决定尝试以Manticore Search的名义将产品作为分叉继续维护。我们成功地重新聚集了之前在不同公司工作的Sphinx原团队成员,吸引了投资,并在短时间内恢复了该项目的全面开发。
# 我们的目标是什么?
---
该分叉旨在实现三个目标:
1. 代码支持总体:修复错误,开发小型和大型新功能
2. 支持Sphinx和Manticore用户
3. 比之前更积极地开发产品。不幸的是,到那时Elasticsearch在许多方面已经超越了Sphinx。
诸如以下问题:
- 没有复制功能
- 没有自动生成ID
- 没有JSON接口
- 没有创建/删除索引的即时方法
- 没有文档存储
- 不成熟的实时索引
- 专注于全文搜索而非一般搜索
使Sphinx成为一个高度专业化的解决方案,在许多情况下需要手动调整。许多用户到那时已经迁移到了Elasticsearch。这是令人遗憾的,因为Sphinx中的基本数据结构和算法在性能方面在许多情况下实际上优于Elasticsearch。而且SQL,即使在现在,其在Sphinx中的发展也比Elasticsearch好得多,这吸引了许多用户。
除了支持现有的Sphinx用户,Manticore的总体目标是实现上述及其他功能,使Manticore Search在大多数使用场景中成为Elasticsearch的真正替代品。
# 我们已经完成了什么
---
## 更加活跃的开发
如果您查看[github提交统计](https://github.com/manticoresoftware/manticoresearch/graphs/contributors),可以看到自从分叉发生(2017年中)后,开发速度大幅提高:
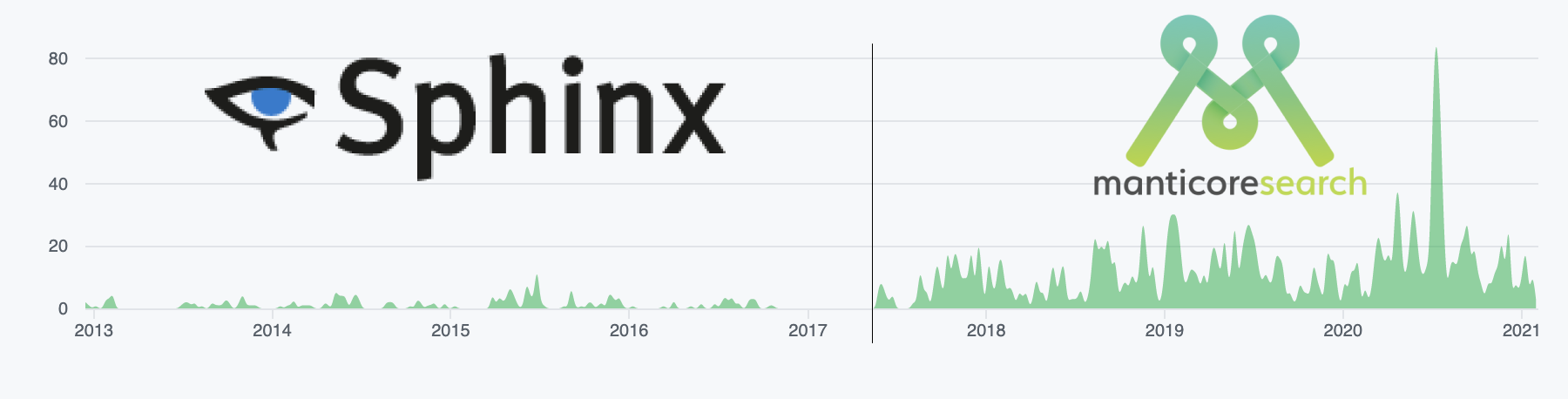
到2021年3月的三年半时间里,我们发布了39个新版本。2020年,我们每两个月发布一个新版本。
## 复制功能
许多用户多年来一直在等待Sphinx的复制功能。Manticore中我们实现的第一个重大功能就是复制。和Manticore中的其他功能一样,我们努力使其尽可能易于使用。例如,要连接到集群,您只需运行如下命令:
```sql
JOIN CLUSTER posts at 'neighbour-server';
```
这将使集群中的索引在当前节点上出现。
Manticore的复制功能是:
- 同步的
- 基于Galera库,该库也用于MariaDB和Percona XtraDB。
## 自动生成ID
没有[自动生成ID](https://manual.manticoresearch.com/Adding_documents_to_an_index/Adding_documents_to_a_real-time_index#Auto-ID),Sphinx/Manticore通常被视为另一个数据库(mysql、postgres等)的扩展,因为必须有某种东西来生成ID。我们基于UUID_SHORT算法实现了自动生成ID。每个服务器每秒最多可保证1600万个插入的唯一性,这在所有情况下都应足够。
```sql
mysql> create table idx(doc text);
Query OK, 0 rows affected (0.01 sec)
mysql> insert into idx(doc) values('abc def');
Query OK, 1 row affected (0.00 sec)
mysql> select * from idx;
+---------------------+---------+
| id | doc |
+---------------------+---------+
| 1514145039905718278 | abc def |
+---------------------+---------+
1 row in set (0.00 sec)
mysql> insert into idx(doc) values('def ghi');
Query OK, 1 row affected (0.00 sec)
mysql> select * from idx;
+---------------------+---------+
| id | doc |
+---------------------+---------+
| 1514145039905718278 | abc def |
| 1514145039905718279 | def ghi |
+---------------------+---------+
2 rows in set (0.00 sec)
```
## 文档存储
在Sphinx 2.3.2及更早版本中,您只能将文档的原始文本保存在字符串属性中,这些属性(像所有属性一样)为了最佳性能必须存储在内存中。许多用户这样做,导致不必要的RAM浪费,这既昂贵又可能在大量数据时引发意外的性能问题。在Manticore中,我们[已经实现](https://play.manticoresearch.com/docstore/)了一种新的数据类型`text`,它结合了全文索引和磁盘上的值存储(惰性读取,即值在查询的最后阶段获取)。"stored"字段的值无法过滤,也不能排序或分组。它们只是以压缩形式存储在磁盘上,因此无需将它们存储在mysql/hbase/postgres等数据库中(除非确实需要)。这被证明是一个非常有用且常用的功能。从那时起,Manticore现在只需自身即可实现搜索应用。
## 实时索引
在Sphinx 2.3.2及更早版本中,许多用户在使用实时索引时遇到了困难,因为这常常导致崩溃和其他副作用。我们已经修复了大部分已知的错误和设计缺陷,并且仍在进行一些优化(主要是与自动OPTIMIZE和读/写/合并隔离相关)。但可以肯定地说,实时索引现在可以安全地用于生产环境,这实际上就是许多用户所做的。我们添加的一些功能包括:
- 多线程:在单个实时索引的多个磁盘块中进行搜索是并行完成的
- 优化改进:默认情况下,块合并不是合并到1个,而是合并到服务器上的核心数\*2(可以通过[cutoff](https://manual.manticoresearch.com/Securing_and_compacting_an_index/Compacting_an_index#Number-of-optimized-disk-chunks)选项进行调整)。
我们正在开发自动OPTIMIZE功能,这样用户就无需担心压缩问题。
## charset_table = cjk, non_cjk
以前,如果您想支持除英语或俄语以外的语言,通常需要在 `charset_table` 中维护大型数组。这很不方便。我们通过将您可能需要的一切放入内部 `charset_table` 数组中,简化了这一过程,这些数组名为 `non_cjk`(用于大多数语言)和 `cjk`(用于中文、韩语和日语)。`non_cjk` 数组是 `charset_table` 的默认数组。现在您可以在英语、俄语和例如土耳其语中搜索而不会遇到问题:
```sql
mysql> create table idx(doc text);
Query OK, 0 rows affected (0.01 sec)
mysql> insert into idx(doc) values('abc абв öğrenim');
Query OK, 1 row affected (0.00 sec)
mysql> select * from idx where match('abc');
+---------------------+----------------------+
| id | doc |
+---------------------+----------------------+
| 1514145039905718280 | abc абв öğrenim |
+---------------------+----------------------+
1 row in set (0.00 sec)
mysql> select * from idx where match('абв');
+---------------------+----------------------+
| id | doc |
+---------------------+----------------------+
| 1514145039905718280 | abc абв öğrenim |
+---------------------+----------------------+
1 row in set (0.00 sec)
mysql> select * from idx where match('ogrenim');
+---------------------+----------------------+
| id | doc |
+---------------------+----------------------+
| 1514145039905718280 | abc абв öğrenim |
+---------------------+----------------------+
1 row in set (0.00 sec)
```
## 官方 Docker 镜像
我们发布了并维护 Manticore Search 的官方 [docker 镜像](https://github.com/manticoresoftware/docker)。只要安装了 docker,您现在可以在任何地方几秒钟内运行 Manticore。
```sql
➜ ~ docker run --name manticore --rm -d manticoresearch/manticore && docker exec -it manticore mysql && docker stop manticore
525aa92aa0bcef3e6f745ddeb11fc95040858d19cde4c9118b47f0f414324a79
mysql> create table idx(f text);
mysql> desc idx;
+-------+--------+----------------+
| Field | Type | Properties |
+-------+--------+----------------+
| id | bigint | |
| f | text | indexed stored |
+-------+--------+----------------+
```
此外,`manticore:dev` 标签始终指向 Manticore Search 的最新开发版本。
## 包管理仓库
所有新版本和最新的开发版本都可以在 找到。
从那里您还可以 [通过 YUM 和 APT 轻松安装 Manticore](https://manticoresearch.com/downloads/)。我们还支持 Homebrew 并维护 Windows 的构建版本。
## NLP:自然语言处理
在 NLP 方面,我们进行了以下改进:
- 使用 [ICU 库](https://github.com/unicode-org/icu) 的中文分词
- 大多数语言的默认停用词开箱即用:
```sql
mysql> create table idx(doc text) stopwords='en';
Query OK, 0 rows affected (0.05 sec)
mysql> call keywords('to be or not to be that is the question', 'idx');
+------+-----------+------------+
| qpos | tokenized | normalized |
+------+-----------+------------+
| 10 | question | question |
+------+-----------+------------+
1 row in set (0.01 sec)
```
- 支持 [更多语言](https://manual.manticoresearch.com/Creating_a_table/NLP_and_tokenization/Supported_languages) 的 Snowball 2.0
- 更简单的语法高亮:
```sql
mysql> insert into idx(doc) values('Polly wants a cracker');
Query OK, 1 row affected (0.09 sec)
mysql> select highlight() from idx where match('polly cracker');
+-------------------------------------+
| highlight() |
+-------------------------------------+
| Polly wants a cracker |
+-------------------------------------+
1 row in set (0.10 sec)
```
## 新的多任务模式
为了多任务处理,Manticore 现在使用协程。除了代码变得更简单可靠之外,现在不再需要为不同索引使用不同的 `dist_threads` 值以使搜索并行化。现在有一个全局设置 `threads`,默认值等于服务器上的核心数。在大多数情况下,您根本不需要调整它以获得最佳性能。
## WHERE 中的 OR 支持
在 Sphinx 2/3 中,您无法轻松使用 `OR` 运算符按属性进行过滤,这是一个很大的限制。我们在 Manticore 中修复了这个问题:
```bash
mysql> select i, s from t where i = 1 or s = 'abc';
+------+------+
| i | s |
+------+------+
| 1 | abc |
| 1 | def |
| 2 | abc |
+------+------+
3 rows in set (0.00 sec)
Sphinx 3:
mysql> select * from t where i = 1 or s = 'abc';
ERROR 1064 (42000): sphinxql: syntax error, unexpected OR, expecting $end near 'or s = 'abc''
```
## 通过 HTTP 支持 JSON 协议
SQL 很酷。我们喜欢 SQL。在 Sphinx / Manticore 中,所有查询语法都可以通过 SQL 完成。但在某些情况下,最佳解决方案是使用 JSON 接口,例如在 Elasticsearch 中。SQL 适合查询设计,而 JSON 在需要将复杂查询集成到应用程序中时表现优异。
此外,HTTP 允许做很多有趣的事情:使用外部 HTTP 负载均衡器和代理,这使得实现身份验证、RBAC 等变得非常容易。
## 更多语言的新客户端
即使使用 JSON over HTTP 也比使用特定编程语言的客户端更简单。我们为 [php](https://github.com/manticoresoftware/manticoresearch-php)、[python](https://github.com/manticoresoftware/manticoresearch-python)、[java](https://github.com/manticoresoftware/manticoresearch-java)、[javascript](https://github.com/manticoresoftware/manticoresearch-javascript)、[elixir](https://github.com/manticoresoftware/manticoresearch-elixir)、[go](https://github.com/manticoresoftware/go-sdk) 实现了新的客户端。其中大多数基于新的 JSON 接口,它们的代码是自动生成的,使我们能够更快地为客户端添加新功能。
## HTTPS 支持
安全很重要。我们提供了 [HTTPS 支持](https://play.manticoresearch.com/https/)。尽管仍然不建议将 Manticore Search 实例暴露在互联网上,因为没有内置的身份验证,但现在通过局域网将查询和结果从客户端传输到 Manticore Search 更加安全。MySQL 接口的 SSL 也得到支持。
## FEDERATED 支持
除了 SphinxSE(一个内置的 MySQL 引擎,允许您更紧密地将 Sphinx/Manticore 与 MySQL 集成)[您现在还可以使用](https://manticoresearch.com/blog/from-sphinxse-to-federated/) MySQL 的 FEDERATED 引擎,该引擎在 MySQL 和 MariaDB 中可用。
## ProxySQL 支持
ProxySQL 也 [得到支持](https://manticoresearch.com/blog/using-proxysql-to-route-inserts-in-a-distributed-realtime-index/),您可以使用它来实现一些非常有趣的功能,扩展 Manticore Search 的能力。
## RT 模式
我们做出的主要更改之一是通过 CREATE/ALTER/DROP 表的方式与 Manticore 进行交互。正如您从上面的 SQL 示例中看到的,您不再需要在配置中定义索引。与其他数据库一样,您现在可以在不编辑配置、重启实例、删除实时索引文件等麻烦的情况下,随时在 Manticore 中创建、修改和删除索引。数据模式现在完全与服务器设置分离。这就是默认模式。我们称之为 `RT 模式`。
但声明式模式(我们称之为 `Plain 模式`)仍然得到支持。我们认为它不是过时的,也没有计划将其删除。就像您可以使用 YAML 文件或特定命令与 Kubernetes 通信一样,您也可以以类似方式与 Manticore 通信:
- 您可以在配置中描述一切,从而受益于易于配置移植和更快的索引部署的可能性,
- 或者您可以随时创建索引,这使它更容易集成到您的应用程序中
混合使用模式是不可行的,也不在计划中。
## Percolate 索引
常规的搜索方式是存储我们想要搜索的文档,并对它们执行查询。然而,有时我们希望将查询应用于传入的新文档以触发匹配。在某些场景中这是需要的。例如,监控系统不仅收集数据,还希望在不同事件发生时通知用户。这可能包括某个指标达到阈值或监控数据中出现特定值。另一个类似的案例是新闻聚合。你可以通知用户任何最新的新闻,但用户可能只想被通知某些类别或主题。更进一步,他们可能只对某些“关键词”感兴趣。所有这些在Manticore中都可以通过使用`percolate索引`实现。
```sql
mysql> create table t(f text, j json) type='percolate';
mysql> insert into t(query,filters) values('abc', 'j.a=1');
mysql> call pq('t', '[{"f": "abc def", "j": {"a": 1}}, {"f": "abc ghi"}, {"j": {"a": 1}}]', 1 as query);
+---------------------+-------+------+---------+
| id | query | tags | filters |
+---------------------+-------+------+---------+
| 8215503050178035714 | abc | | j.a=1 |
+---------------------+-------+------+---------+
```
比Elasticsearch更快[https://manticoresearch.com/blog/percolate-queries-manticoresearch-vs-elasticsearch/](https://manticoresearch.com/blog/percolate-queries-manticoresearch-vs-elasticsearch/)。
## 新用户友好的文档 - https://manual.manticoresearch.com
对于Manticore Search的关键功能,大多数支持的客户端都有示例。搜索手册当然使用Manticore Search作为后端。除此之外:
- 搜索结果中的智能高亮显示
- HTTP示例可以一键复制为带有参数的curl命令
- 此外,我们特别注册了短域名`mnt.cr`,因此你可以通过浏览器的`CTRL-T/CMD-T`快速找到你需要的信息,例如 [mnt.cr/proximity](https://mnt.cr/proximity) , [mnt.cr/quorum](https://mnt.cr/quorum) , [mnt.cr/percolate](https://mnt.cr/percolate)。
## 交互式课程 - https://play.manticoresearch.com
为了使用户更容易上手Manticore Search,我们创建了交互式课程平台 以及课程本身,你可以直接在浏览器中学习,无需安装任何东西。只需几秒钟,你就可以看到 [Manticore Search复制功能如何工作](https://play.manticoresearch.com/replication) 或如何 [高亮搜索结果](https://play.manticoresearch.com/highlighting/)。
## GitHub作为错误跟踪器
我们使用 [GitHub](https://github.com/manticoresoftware/manticoresearch/issues/) 作为公共的错误/任务跟踪器。
# Sphinx 3
---
Sphinx 3.0.1于2017年12月发布。直到2018年10月之前又发布了三个版本,2020年7月还有一个版本(3.3.1,截至2021年3月的最后一个版本)。许多有趣的功能出现,包括二级索引和一些机器学习能力。那么问题来了?为什么人们需要Manticore?其中一个原因是,不幸的是,Sphinx 3的第一个版本和最后一个版本目前都不是开源的:
- 一方面Sphinx 3的代码不可用
- 另一方面在[开源的更广泛意义上](https://opensource.com/resources/what-open-source)。在下载页面上[提到](http://sphinxsearch.com/downloads/),Sphinx现在采用“延迟FOSS”许可证。这个许可证具体是什么以及在哪里可以找到并未披露。不清楚:
- 是否仍然是GPLv2(即“延迟FOSS”意味着延迟GPLv2),因为代码可能基于Sphinx 2,而Sphinx 2是GPLv2(像Manticore一样)。但源代码在哪里?
- 或者它不是GPLv2,因为二进制文件没有附带许可证,而且不清楚代码是否甚至基于Sphinx 2?GPLv2的限制是否适用?是否可以随意分发Sphinx 3的二进制文件,因为没有许可证文本?
- 自2020年7月以来没有发布任何版本。[有很多错误](https://sphinxsearch.com/bugs/),包括重大崩溃。何时会修复?
有很多问题但没有答案。所有这些使得使用Sphinx 3对于关心法律问题和项目稳定性的公司和个人来说非常有风险。没有多少公司有能力将员工的时间投入到看起来冻结且许可证不明确的项目中。
总的来说,Sphinx 3现在可以被视为一个专有解决方案,仅适用于有非常具体目标的有限用户群体。开源世界失去Sphinx是一件遗憾的事。我们只能希望未来有所改变。
# 有基准测试吗?
---
有!让我们测试由HackerNews的1M+评论和数值属性组成的[数据集](https://zenodo.org/record/45901/files/hacker_news_comments.csv?download=1)。
更多关于测试的信息:
- 从数据集构建的普通索引。索引文件的大小约为1千兆字节
- 一组各种查询(132个请求),从全文搜索到过滤和分组
- 在裸金属服务器上运行的docker,具有不同的内存限制
- 我们使用PHP脚本通过mysqli客户端的SQL来发出查询
- 在每个新查询之前,清除所有缓存(包括操作系统缓存)并重启docker,然后运行5次尝试,最低响应时间进入统计。
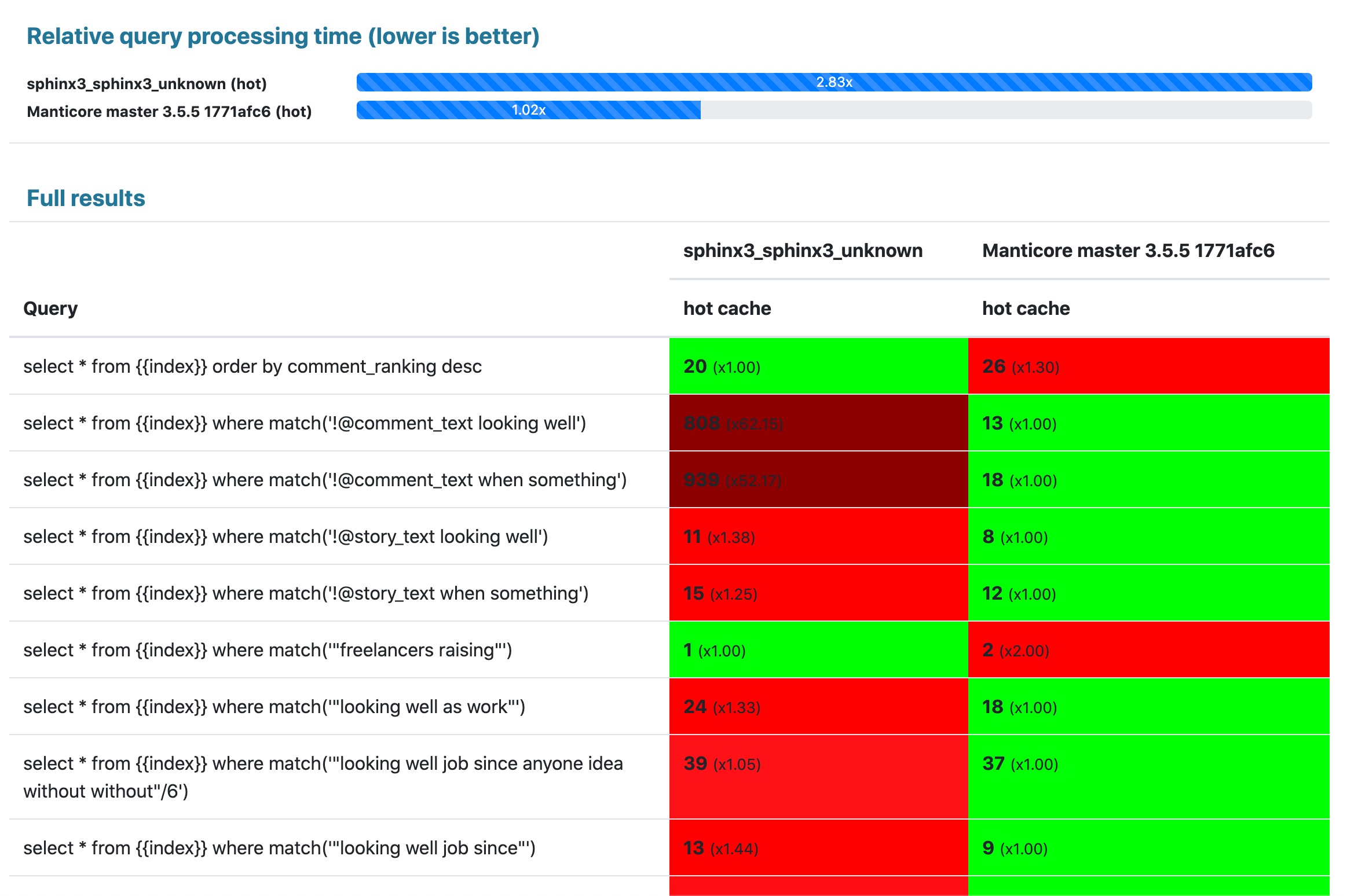
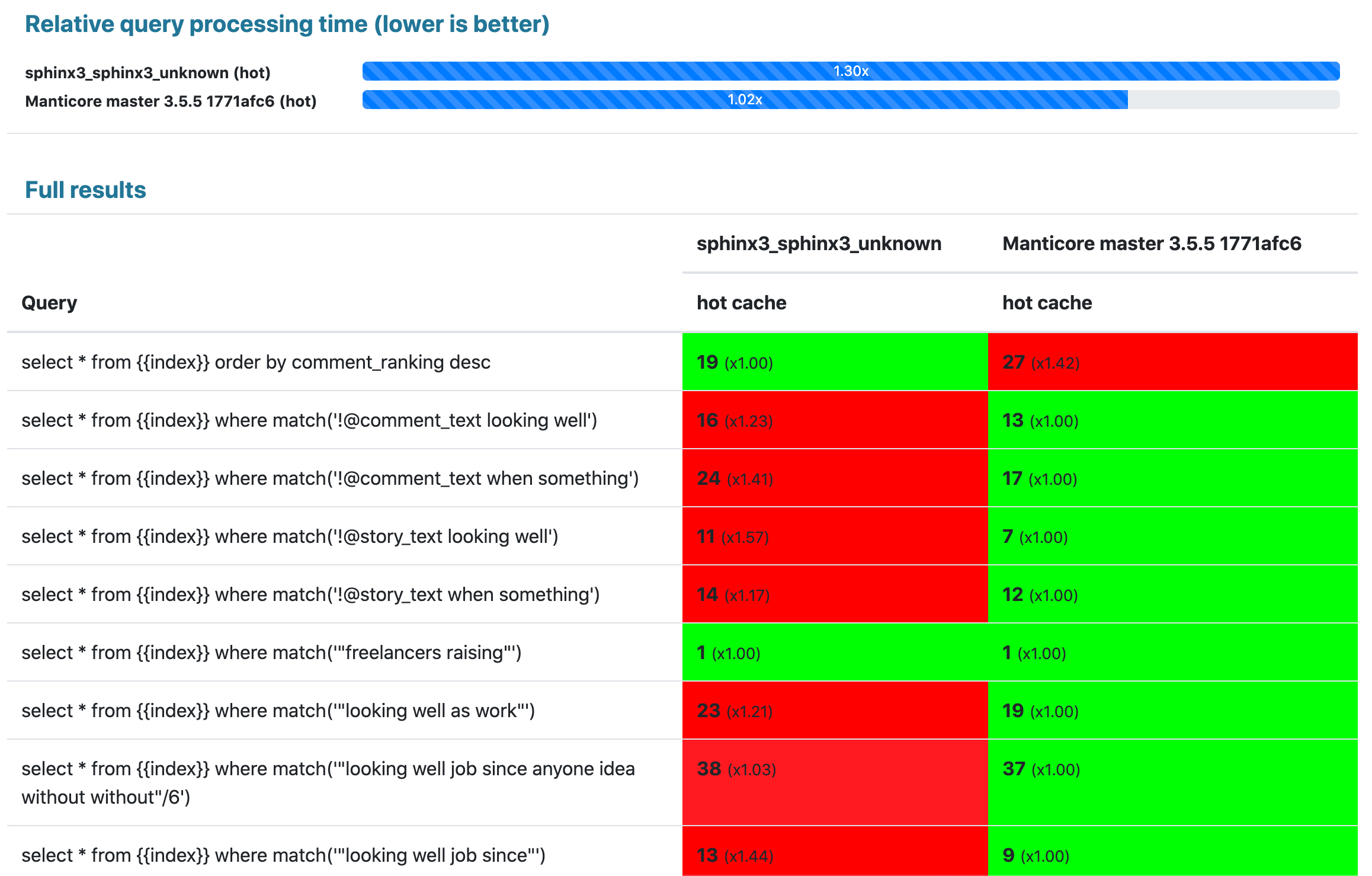
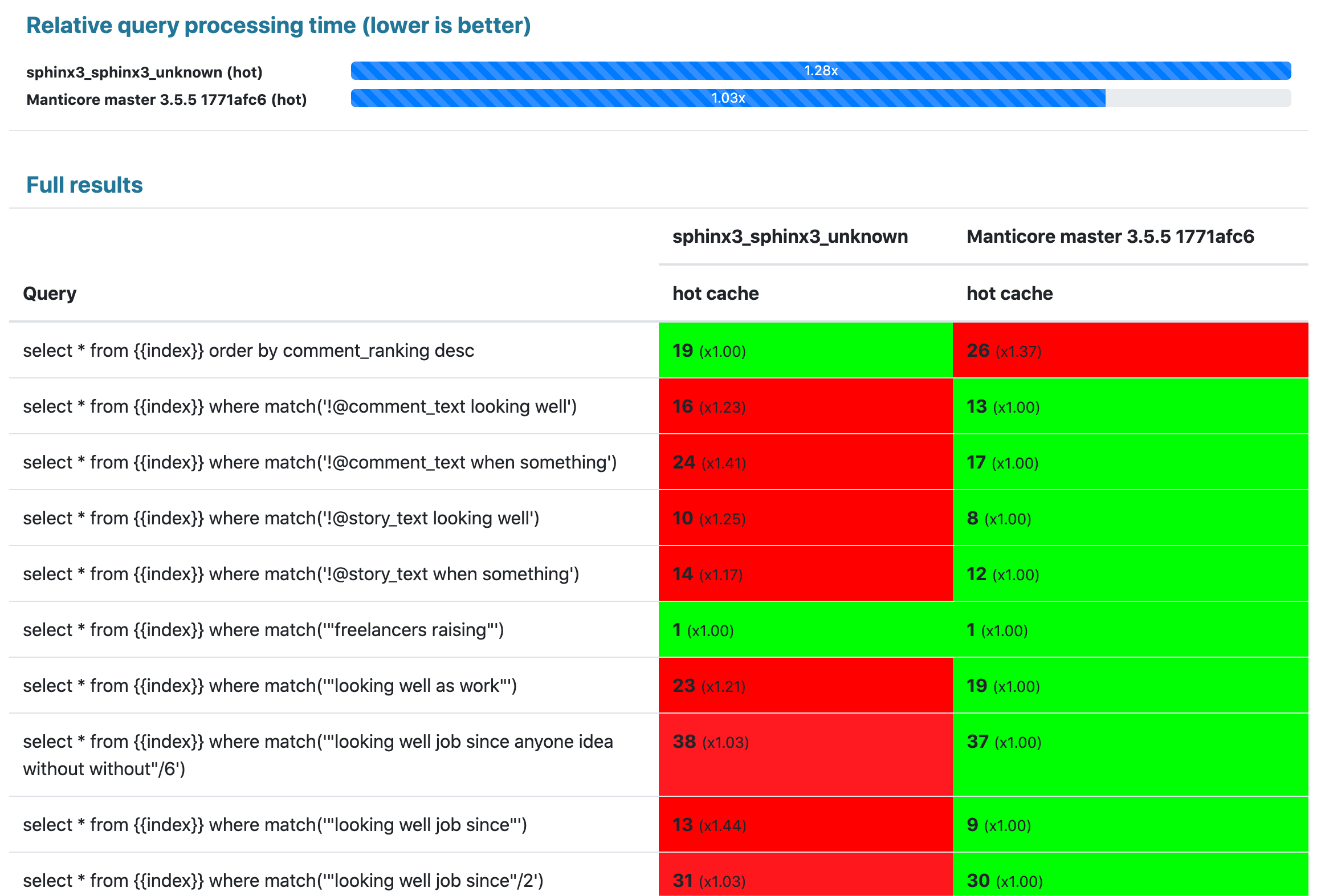
## 结果:
100兆字节限制:
500兆字节限制:
1000兆字节限制:
# Manticore Search的未来
---
因此,我们已经有了一个在清晰的开源许可证GPLv2下积极开发的产品,具有复制功能、自动ID、正常工作的实时索引、JSON接口、良好的文档、交互式课程等。接下来是什么?我们的路线图是:
## 新Manticore引擎
自2020年初以来,我们一直在开发一个列式存储和处理库,默认索引(与Clickhouse等相比)。对于Manticore和Sphinx用户,这将解决以下问题:
- 需要大量RAM才能在大量文档和属性中快速搜索
- 分组性能不佳
- 当部分属性无法放入RAM时,过滤性能不佳
我们已经有了一个[测试版](https://github.com/manticoresoftware/columnar/),以下是将 Manticore Columnar Library + Manticore Search 与 Elasticsearch 在相同数据集上进行比较的一些初步结果(不包括全文查询,即主要是分组查询):

还有很多工作要做。该库采用更宽松的开源许可证 Apache 2.0 发布,可以在 Manticore Search 以及其他项目(如果他们喜欢的话,甚至可以在 Sphinx 中)中使用。
## 自动优化
我们意识到手动调用 `OPTIMIZE` 对于实时索引压缩来说非常不方便。我们正在努力解决这个问题,并希望将其包含在下一个版本中。在 [twitter](https://twitter.com/manticoresearch) 上关注我们,以免错过这个功能。
## 与 Kibana 的集成
由于用户现在可以使用新的 Manticore 引擎进行更多分析,因此能够轻松地对其进行可视化将非常不错。Grafana 很棒,但可能对于全文搜索来说使用起来有点复杂。Kibana 也很不错,很多人知道并使用它。我们已经有了 Manticore Search 与 Kibana 集成的 alpha 版本。它目前尚未公开,但一旦我们完成错误修复并将其视为 beta 版本,它将被开源。
## 与 Logstash 的集成
Manticore Search 已经具有 JSON 协议。我们计划改进 PUT 和 POST 方法,使其与 Elasticsearch 兼容,用于 INSERT/REPLACE 查询。此外,我们计划实现根据插入的第一个文档动态创建索引的功能。所有这些都将允许您从 Logstash、Fluentd、Beats 等工具将数据写入 Manticore Search,而不是 Elasticsearch。
## 自动分片
这是另一个正在进行的项目。我们已经了解了将要面临的困难以及大致的解决方法。我们计划在第二季度进行。
## Logstash 的替代方案
Logstash 要求用户花费大量时间才能开始从新的 **自定义** 日志类型中导入数据。如果您添加任何新行,解析规则将需要更新。在过去的几个月里,我们一直在开发一个系统,几乎可以完全解决这个问题。它将允许您几乎无需帮助地解析日志,并提供一个友好的用户界面来命名字段并进行最终的微调。
如果您喜欢我们所做的,请通过以下方式关注我们:
- [GitHub](https://github.com/manticoresoftware/manticoresearch)
- [论坛](https://forum.manticoresearch.com/)
- [公共 Slack 聊天室](https://slack.manticoresearch.com/)
- [Telegram 聊天室(英文)](https://t.me/manticoresearch_en)
- [Telegram 聊天室(俄文)](https://t.me/manticore_chat)
- [Twitter](https://twitter.com/manticoresearch)
- [VK](https://vk.com/manticoresearch)
- [Facebook](https://www.facebook.com/manticoresearch)