
现代搜索引擎不仅仅匹配关键词。当你搜索 "cozy mystery set in Paris"(巴黎的温馨悬疑小说)并得到 "atmospheric detective novel in France"(法国的氛围侦探小说)这样的结果时,这是向量搜索在起作用:文档和查询被转换为数字列表,称为嵌入(embeddings),搜索引擎会找到与查询数字最接近的文档。
Manticore Search 原生支持这一功能。在底层,它使用一种称为 HNSW 的数据结构:一种连接附近向量的图,因此可以快速找到最近邻,而无需扫描每个文档。这使得向量搜索足够快,可以在毫秒内处理数百万个文档。
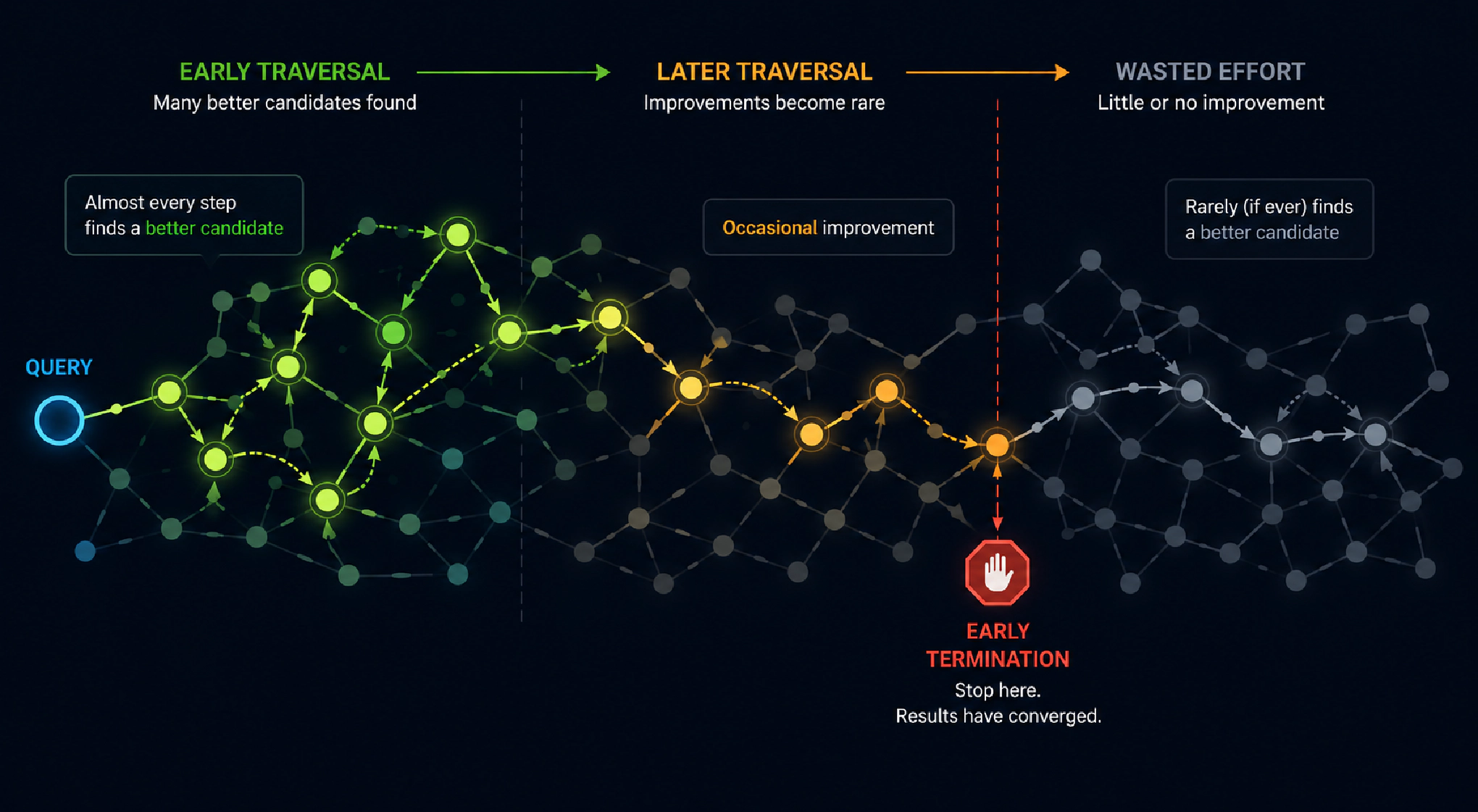
但 HNSW 存在一种低效的情况。在遍历的早期阶段,几乎所有距离计算都会找到比结果集中现有候选者更好的候选者。
随着搜索的进行,这些改进变得稀少,但算法仍会遍历图直到耗尽探索预算。到那时,结果集通常已经收敛,剩余的工作对结果的改进微乎其微。早期终止通过检测这一时刻并提前停止来解决这个问题。
当 k 增大时,这种效果会更加明显,其中 k 是查询要求 Manticore 返回的最近邻数量。返回更多邻居需要更多的图探索,而其中大部分额外工作发生在结果集已经稳定之后。这也使早期终止更有价值,因为它可以削减更多不必要的工作。
这一点在 向量量化
中更加明显。量化通过压缩存储的向量来节省内存,这会略微降低搜索精度。为了恢复精度,Manticore 使用 过采样
:它获取三倍于请求的候选者,然后使用原始全精度向量重新评分。在默认的三倍过采样下,HNSW 每个查询会探索更多候选者。较大的 k 值通常来自这种候选者扩展:应用程序可能会向向量索引请求数百或数千个候选者,然后重新评分、重新排序或过滤以得到更小的最终结果集,从而提高召回率和精度。这会增加延迟,而早期终止可以帮助部分弥补这一问题。
这种浪费是可以衡量的。在 100 万向量数据集上的基准测试显示,当 k=60(这是默认三倍过采样下的默认结果限制)时,早期终止将距离计算减少到完整搜索的约 65%。当 k=1000 时,计算量下降到 30%。当 k=10000 时,仅剩 20%。搜索在探索预算耗尽之前很久就已收敛,而节省的资源随着 k 的增大而增加。
早期终止使 Manticore 能够检测到这种收敛并停止。该算法设计了一个特定的精度目标:与完整 HNSW 搜索相比,结果集的精度损失不超过 2-4%。
它是如何工作的
该算法跟踪一个简单的信号:发现率——即实际改进结果集的距离计算比例。
每次计算新节点的距离时,会发生以下两种情况之一:要么它足够好以进入堆——保存当前最佳候选邻居的优先队列——要么它比所有已有的候选者都差并被丢弃。进入堆计为一次“发现”。在搜索的早期阶段,发现很频繁——堆正在填充,大多数候选者都有用。随着搜索的进行,堆被优质结果填满后,发现变得稀少。大多数新的距离计算只是确认算法已经找到了最佳候选者。
Manticore 监控这一转变。在每次邻居扩展轮次之后,它计算发现率:
discovery_rate = new_candidates_collected / distances_computed
如果这一比率连续多轮低于阈值,搜索就会停止。
这个想法很简单:如果算法持续计算距离但结果没有改进,说明搜索已经收敛。
阈值:基于分位数的自适应
这自然引出了下一个明显的问题:什么阈值应被视为“低”?固定阈值效果不佳——不同数据集以及同一数据集的不同区域具有截然不同的发现率分布。“低”的定义取决于上下文。
Manticore 使用基于分位数的自适应阈值。它不是将发现率与固定数值比较,而是持续估计最近几轮的低分位数(20 分位数,或 L2 距离的 14 分位数),并将其作为基准。这使方法保持轻量,同时允许其适应不同数据集和图的不同区域。
换句话说,阈值会适应局部搜索模式。如果算法进入图的稀疏区域,阈值会降低以避免过早停止。如果进入更丰富的区域,阈值则会上升。
耐心:在停止前需要多少次差的轮次
尽管如此,仅凭阈值仍不足以判断收敛。单轮低发现率不足以宣布收敛,这可能只是搜索找到更好路径前的暂时下降。Manticore 使用一个“耐心计数器”,要求连续多次差的轮次后才会终止。
耐心值与控制搜索过程中保留候选数量的HNSW探索因子ef成反比。例如,耐心值在低ef值时从9下降到非常高的ef值时的6。较大的ef值意味着总轮数更多,因此即使耐心值较低,算法在决定停止前也已看到更多证据。每当一轮具有健康的发现率时,计数器会重置为零,因此一轮良好的表现会重启耐心窗口。这可防止算法在暂时的平台期停止,而该平台期可能导向图中的高产区域。
预热阶段
当堆仍在填充时,算法会忽略终止信号,这意味着收集的候选数量少于ef。在此阶段,发现率人为地很高,因为几乎所有内容都会进入堆,因此该信号无用。只有当堆已满且新候选必须替换现有候选时,才会开始早期终止。
基准结果
分位数阈值经过调整,以将精度损失控制在2-4%以内。它们分别针对L2和余弦/IP距离度量进行了调整,并在量化和非量化 数据上进行了验证。
以下基准在具有8个物理核心/16个逻辑核心的机器上,使用dbpedia-entities 数据集(1M向量,768维)运行:
- 此处的“精度”表示结果集中出现的真实k近邻的比例(固定k时,这等同于recall@k)。
- “精度比率”是启用早期终止(“ET”)的HNSW精度与未启用时的精度之比(1.0表示无精度损失)。
- “访问比率”是执行的距离计算次数与完整HNSW搜索相比的比例(越低越好)。
过采样和重新评分 被禁用,以隔离早期终止对原始HNSW遍历的影响。

图表中的绿色线(精度)在所有k值上几乎保持平坦,精度比率在整个基准中始终高于0.97。同时,橙色线(访问比率)急剧下降。在k=100时,距离计算几乎减半。在k=1000时,节省了70%。在k=10000时,节省了80%。
当k <= 10时,早期终止被禁用,因为搜索本身已经很便宜,节省的资源不足以弥补任何精度损失。随着k增大,节省的资源也增加,因为更大的结果集导致更多轮的邻居扩展,从而有更多机会检测收敛。
并发负载下的性能
上述基准显示,早期终止在保持精度的同时大幅减少了距离计算。但这对实际查询延迟意味着什么,尤其是在并发负载下?下图显示了在相同dbpedia数据集上,1、8和16个并发线程下的延迟比率(ET / 无ET):

在k=1000时,早期终止将距离计算减少了71%(比率0.29)。延迟改进取决于同时运行的线程数量:
- 1个线程: 快24%(比率0.76)
- 8个线程: 快45%(比率0.55)
- 16个线程: 快48%(比率0.52)
无论线程数量如何,距离计算的节省保持不变,但延迟收益从1到16个线程几乎翻倍。
主要原因是对CPU内存系统的压力降低。每次距离计算都会将向量数据和图链接加载到缓存中。当多个线程同时运行HNSW遍历时,它们会竞争共享缓存和内存带宽。减少每个查询的距离计算可降低内存流量,使每个线程的工作集更小,并减少查询之间的缓存抖动。因此,每个线程完成得更快,并且对其他线程的干扰更小。
单线程基准低估了早期终止的好处。在生产级并发负载下,延迟减少的百分比大约是单线程的两倍。
早期终止何时生效(何时不生效)
早期终止默认启用,适用于量化和非量化向量数据。当k <= 10时,它会自动禁用。
随着有效探索预算的增加,收益也会增加,有效探索预算是max(ef, k)。由于hnswlib内部使用此值作为保留的候选数量,较大的k意味着更多候选、更多轮次和更多检测收敛的机会。
量化向量通常与重新评分和过采样(默认启用)一起使用,以恢复量化导致的精度损失。过采样(默认3倍)会乘以传递给HNSW的有效k。例如,当过采样为3倍时,k=100的查询内部使用300个候选。更大的搜索预算为早期终止提供了更多空间来检测收敛并提前停止。由于早期终止的性能收益随k增加而增长,过采样将查询推入了节省最大的范围。
语法
早期终止默认启用。要禁用它:
SQL:
-- default: early termination enabled
SELECT id, knn_dist()
FROM products
WHERE knn(embedding, (0.12, 0.45, 0.78, 0.33));
-- explicitly disable early termination
SELECT id, knn_dist()
FROM products
WHERE knn(embedding, (0.12, 0.45, 0.78, 0.33), { early_termination=0 });
-- combine with other KNN options
SELECT id, knn_dist()
FROM products
WHERE knn(embedding, (0.12, 0.45, 0.78, 0.33), { ef=200, early_termination=0 });
JSON:
POST /search
{
"table": "products",
"knn": {
"field": "embedding",
"query": [0.12, 0.45, 0.78, 0.33],
"early_termination": false
}
}
何时禁用它
在以下几种情况下,您可能需要关闭早期终止:
- 最大精度至关重要。 早期终止以牺牲少量召回率换取速度。如果您的应用需要HNSW在给定
ef下能提供的最佳召回率,请禁用它。 - 小k值(<= 30)。 算法在
k <= 10时自动禁用,但即使k在11到30之间,性能收益也较为有限。如果您在该范围内注意到任何召回率差异,禁用早期终止对延迟影响很小。 - 基准HNSW召回率。 如果您正在测量HNSW召回率,可能需要确定性行为而非自适应捷径。禁用早期终止以获得干净的基准线。
它与其他KNN优化的关系
提前终止是 Manticore 应用于 KNN 搜索的几种优化措施之一。它独立于其他优化措施并可以与它们叠加使用: