
Конференция FOSDEM, прошедшая 3 февраля 2024 года, представила доклад о Manticore Vector Search от Peter Zaitsev , соучредителя Manticore, и Sergey Nikolaev , генерального директора Manticore. Это событие продемонстрировало новейшее о векторном поиске в базах данных. Для более детального ознакомления запись выступления Зайцева доступна выше. Ниже вы можете увидеть более подробное резюме темы в виде статьи.
Введение
За последние два‑три года ландшафт баз данных претерпел несколько ключевых изменений:
- Появилась новая категория «векторных баз данных», включающая открытые платформы, такие как Milvus (2019), Vespa (2020), Weaviate (2021) и Qdrant (2022), а также облачные решения, например Pinecone, представленный в 2019 году. Эти базы данных предназначены для векторного поиска, сосредотачиваясь на использовании различных моделей машинного обучения. Однако им могут не хватать традиционных возможностей баз данных, таких как транзакции, аналитика, репликация данных и т.п.
- Elasticsearch добавил возможности векторного поиска в 2019 году.
- Затем, с 2022 по 2023 год, устоявшиеся базы данных, включая Redis, OpenSearch, Cassandra, ClickHouse, Oracle, MongoDB и Manticore Search, а также облачные сервисы Azure, Amazon AWS и Cloudflare, начали предлагать функциональность векторного поиска.
- Другие известные базы данных, такие как MariaDB, находятся в процессе интеграции возможностей векторного поиска*.
- Для пользователей PostgreSQL существует расширение «pgvector», реализующее эту функциональность с 2021 года.
- Хотя MySQL не объявил планы по внедрению нативного векторного поиска, доступны проприетарные расширения от провайдеров, таких как PlanetScale и AlibabaCloud.

Векторное пространство и векторное сходство
Давайте обсудим, почему так много баз данных недавно внедрили функциональность векторного поиска и что это вообще такое.
Начнём с наглядного примера. Рассмотрим два цвета: красный с RGB‑кодом (255, 0, 0) и оранжевый с RGB‑кодом (255, 200, 152). Чтобы сравнить их, построим их на трехмерном графике, где каждая точка представляет отдельный цвет, а оси соответствуют красному, зеленому и синему компонентам цветов. Затем мы проведём векторы от начала координат к точкам, представляющим наши цвета. В результате получаем два вектора: один — представляющий красный, другой — оранжевый.
Если мы хотим найти сходство между этими двумя цветами, один из подходов — просто измерить угол между векторами. Этот угол может варьироваться от 0 до 90 градусов, а если нормировать его, взяв косинус, он будет изменяться от 0 до 1. Однако этот метод не учитывает величину векторов, что означает, что косинус даст одинаковое значение для цветов A, A1, A2, хотя они представляют разные оттенки.
Чтобы решить эту проблему, мы можем использовать формулу косинусного сходства, которая учитывает длины векторов — скалярное произведение векторов, делённое на произведение их модулей.
Эта концепция является сутью векторного поиска. Её легко представить на примере цветов, но теперь представьте, что вместо трёх цветовых осей у нас пространство со стотнями или тысячами измерений, где каждая ось представляет конкретную характеристику объекта. Хотя сложно изобразить это на слайде или полностью визуализировать, математически это выполнимо, и принцип остаётся тем же: у вас есть векторы в многомерном пространстве, и вы вычисляете их сходство.

Существует несколько других формул для вычисления векторного сходства: например, сходство по скалярному произведению и евклидово расстояние, но, как говорится в документации OpenAI API, разница между ними обычно не имеет большого значения.
Скриншот: https://platform.openai.com/docs/guides/embeddings/which-distance-function-should-i-use
Векторные признаки: разреженные векторы
Итак, объект может иметь различные признаки. Цвет с компонентами Красный, Зеленый и Синий — самый простой пример. В реальной жизни всё обычно гораздо сложнее.
В текстовом поиске, например, мы можем представлять документы в виде высокоразмерных векторов. Это приводит к концепции «мешка слов». Эта модель преобразует текст в векторы, где каждое измерение соответствует уникальному слову, а значение может быть бинарным индикатором наличия слова, счётчиком вхождений или весом слова, основанным на его частоте и обратной частоте документов (TF‑IDF), отражающим, насколько слово важно для документа в коллекции. Такие векторы называют разреженными, поскольку большинство значений равно нулю, так как в большинстве документов мало слов.
Говоря о полнотекстовом поиске в библиотеках и поисковых системах, таких как Lucene , Elasticsearch и Manticore Search , разреженные векторы ускоряют поиск. По сути, можно создать специальный тип индекса, который игнорирует документы без искомого термина. Таким образом, не требуется проверять каждый документ при каждом поиске. Разреженные векторы также легко понять, их можно, в определённом смысле, декомпозировать. Каждое измерение соответствует конкретному чёткому признаку, поэтому мы можем проследить от векторного представления обратно к исходному тексту. Эта концепция существует уже около 50 лет.

Изображение:
https://www.researchgate.net/figure/Figure4DocumentrepresentationintheVectorSpaceModel22_fig1_312471174
Векторные признаки: плотные векторы
Традиционные методы поиска текста, такие как TF-IDF , которые существуют уже десятилетия, создают разреженные векторные представления слов, зависящие от частоты термина. Основная проблема? Они обычно игнорируют контекст, в котором используются слова. Например, термин «apple» может быть связан как с фруктом, так и с технологической компанией без различия, что может привести к их одинаковому ранжированию в поиске.
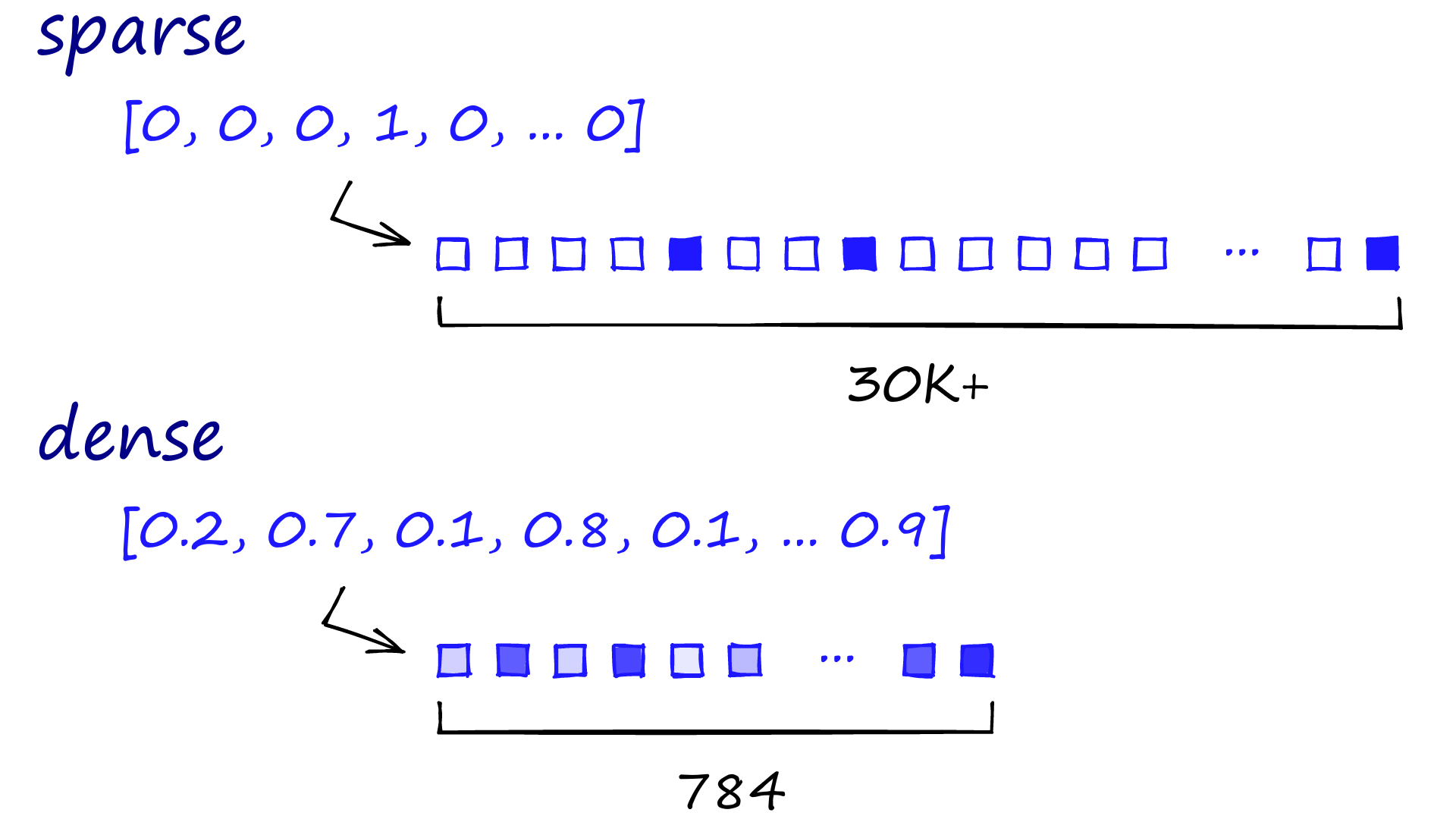
Но рассмотрим эту аналогию: в векторном пространстве, какие два объекта будут находиться ближе друг к другу: кот и собака, или кот и автомобиль? Традиционные методы, генерирующие разреженные векторы — как тот, что показан в верхней части изображения ниже, — могут испытывать трудности с предоставлением осмысленного ответа. Разреженные векторы часто имеют высокую размерность, при этом большинство значений равно нулю, представляя отсутствие большинства слов в данном документе или контексте.
Затем наступила революция глубокого обучения, представив контекстные встраивания. Это плотные векторные представления, как показано в нижней части изображения. В отличие от разреженных векторов, которые могут иметь десятки тысяч измерений, плотные векторы имеют меньшую размерность (например, 784 измерения на изображении), но заполнены непрерывными значениями, захватывающими тонкие семантические отношения. Это означает, что одно и то же слово может иметь разные векторные представления в зависимости от контекста, а разные слова могут иметь похожие векторы, если они разделяют контексты. Такие технологии, как BERT и GPT , используют эти плотные векторы для захвата сложных языковых особенностей, включая семантические отношения, различение синонимов и антонимов, а также понимание иронии и сленга — задачи, которые были довольно сложными для предыдущих методов.
Более того, глубокое обучение выходит за пределы текста, позволяя обрабатывать сложные данные, такие как изображения, аудио и видео. Их также можно преобразовать в плотные векторные представления для задач классификации, распознавания и генерации. Появление глубокого обучения совпало с взрывным ростом доступных данных и вычислительных мощностей, что позволило обучать сложные модели, раскрывающие более глубокие и тонкие закономерности в данных.

Изображение:
https://cdn.sanity.io/images/vr8gru94/production/96a71c0c08ba669c5a5a3af564cbffee81af9c6d-1920x1080.png
Встраивания
Векторы, которые предоставляют такие модели, называются «встраиваниями». Важно понять, что в отличие от ранее показанных разреженных векторов, где каждый элемент может представлять явную характеристику, например слово, присутствующее в документе, каждый элемент встраивания также представляет конкретную характеристику, но в большинстве случаев мы даже не знаем, что это за характеристика.
Например,
Джей Алмар сделал интересный эксперимент
и использовал модель GloVe для векторизации Википедии, а затем визуализировал значения некоторых слов разными цветами. Мы видим здесь, что:
- Последовательная красная линия появляется в разных словах, указывая на сходство по одному измерению, хотя конкретный атрибут, который она представляет, остаётся неидентифицированным.
- Термины вроде «woman» и «girl» или «man» и «boy» демонстрируют сходства по нескольким измерениям, что подразумевает их взаимосвязь.
- Интересно, что «boy» и «girl» имеют сходства, отличные от «woman» и «man», намекая на подлежащую тему молодёжи.
- За исключением одного случая с термином «water», все проанализированные слова относятся к людям, а «water» служит для различения концептуальных категорий.
- Отдельные сходства между «king» и «queen», отличные от остальных терминов, могут указывать на абстрактное представление монархии.

Изображение:
https://jalammar.github.io/illustrated-word2vec/
Таким образом, плотные векторные встраивания, созданные с помощью глубокого обучения, захватывают огромное количество информации в компактной форме. В отличие от разреженных векторов, каждое измерение плотного встраивания обычно ненулевое и несёт некоторую семантическую значимость. Эта богатство имеет свою цену — с плотными встраиваниями, поскольку каждое измерение плотно заполнено значениями, мы не можем просто пропускать документы, не содержащие определённый термин. Вместо этого мы сталкиваемся с вычислительной интенсивностью сравнения векторного запроса со всеми векторными представлениями документов в наборе данных. Это грубый подход, естественно требующий больших ресурсов.
Тем не менее, были разработаны специализированные индексы, адаптированные для плотных векторов. Такие индексы, как KD-деревья, Ball‑деревья или более современные подходы, такие как HNSW (Hierarchical Navigable Small World) графы, довольно умны, но иногда им приходится делать догадки, чтобы быть быстрыми. Эти догадки могут означать, что они не всегда дают ответ на 100 % правильно.

{kind=link}
{kind=link}
K-nearest neighbours
Векторный поиск на самом деле является обобщающим термином, который включает различные задачи, такие как кластеризация, классификация и другие. Но обычно первой функцией, которую база данных добавляет для векторного поиска, является поиск «K‑ближайших соседей» (KNN) или его близкий родственник — «Приблизительный поиск ближайших соседей» (ANN). Это привлекательно, потому что позволяет базам данных находить документы, наиболее похожие на вектор данного документа, что дает им мощные возможности поисковой системы, которых ранее не было.
Традиционные поисковые движки, такие как Lucene, Elasticsearch, SOLR и Manticore Search, обрабатывают различные задачи обработки естественного языка — такие как морфология, синонимы, стоп‑слова и исключения — всё это направлено на поиск документов, соответствующих заданному запросу. KNN достигает аналогичной цели, но другими средствами — просто сравнивая векторы, связанные с документами в таблице, которые обычно предоставляются внешней моделью машинного обучения.
Давайте посмотрим, как выглядит типичный векторный поиск в базах данных, используя в качестве примера
Manticore Search
.
First, we create a table with a column titled image_vector:
create table test ( title text, image_vector float_vector knn_type='hnsw' knn_dims='4' hnsw_similarity='l2' );
Этот вектор имеет
тип float
, что важно, потому что базы данных, не поддерживающие этот тип данных, должны сначала добавить его, так как плотные векторы обычно хранятся в массивах float. На этом этапе вы также обычно настраиваете поле, указывая размерность вектора, тип индекса вектора и его свойства. Например, мы указываем, что хотим использовать индекс HNSW, вектор будет иметь размерность 5, а функция сходства будет l2, что является евклидовым расстоянием.
Then, we insert a few records into the table:
insert into test values ( 1, 'yellow bag', (0.653448,0.192478,0.017971,0.339821) ), ( 2, 'white bag', (-0.148894,0.748278,0.091892,-0.095406) );
Каждая запись имеет заголовок и соответствующий вектор, который в реальном сценарии может быть результатом работы глубокой обучающей модели, кодирующей некоторую форму высокоразмерных данных, таких как изображение или звук, эмбеддинг из текста или что‑то другое из API OpenAI. Эта операция сохраняет данные в базе и может вызвать перестройку или корректировку индекса.
Next, we perform a vector search by utilizing the KNN function :
select id, knn_dist() from test where knn ( image_vector, 5, (0.286569,-0.031816,0.066684,0.032926) );
+------+------------+
| id | knn_dist() |
+------+------------+
| 1 | 0.28146550 |
| 2 | 0.81527930 |
+------+------------+
2 rows in set (0.00 sec)
Здесь мы делаем запрос к базе данных, чтобы найти векторы, ближайшие к нашему заданному входному вектору. Числа в скобках определяют конкретный вектор, для которого мы ищем ближайших соседей. Этот шаг критически важен для любой базы данных, стремящейся реализовать возможности векторного поиска. На этом этапе база может либо использовать специфические методы индексации, такие как HNSW, либо выполнить перебор, сравнивая запросный вектор со всеми векторами в таблице, чтобы найти самые близкие совпадения.
The results returned show the titles of the nearest vectors to our input vector and their respective distances from the query. Lower distance values indicate closer matches to the search query.

Embedding computation
Большинство баз данных и поисковых движков до сих пор полагаются на внешние эмбеддинги. Это означает, что при вставке документа вы должны заранее получить его эмбеддинг из внешнего источника и включить его в остальные поля документа. То же самое относится к поиску похожих документов: если поиск выполняется по пользовательскому запросу, а не по существующему документу, вам необходимо использовать модель машинного обучения для вычисления эмбеддинга, который затем передаётся в базу данных. Этот процесс может привести к проблемам совместимости, необходимости управлять дополнительными слоями обработки данных и потенциальной неэффективности поиска. Операционная сложность такого подхода также выше, чем необходимо. Вместе с базой данных вам может потребоваться поддерживать отдельный сервис для генерации эмбеддингов.
Некоторые поисковые движки, такие как Opensearch, Elasticsearch и Typesense, теперь упрощают задачу, автоматически создавая эмбеддинги. Они могут даже использовать инструменты других компаний, например OpenAI, для этого. Я считаю, что мы скоро увидим больше подобных решений. Всё больше баз данных начнут самостоятельно генерировать эмбеддинги, что действительно может изменить то, как мы ищем и анализируем данные. Это изменение означает, что базы данных будут делать больше, чем просто хранить данные; они начнут их понимать. Используя машинное обучение и ИИ, такие базы станут умнее, смогут предсказывать и адаптироваться, а также обрабатывать данные более продвинутыми способами.
Hybrid search approaches
Некоторые поисковые движки приняли метод, известный как гибридный поиск, который сочетает традиционный поиск по ключевым словам с продвинутыми нейронными сетями. Гибридные модели поиска превосходят в ситуациях, требующих как точных совпадений по ключевым словам, предоставляемых традиционными методами, так и более широкого распознавания контекста, предлагаемого векторным поиском. Такой сбалансированный подход может повысить точность результатов поиска. Например, Vespa измерила точность своего гибридного поиска , сравнив его с классическим ранжированием BM25 и моделью ColBERT по отдельности. В их подходе классический BM25 использовался как модель ранжирования первой фазы, а гибридный скор рассчитывался только для топ‑K документов согласно модели BM25. Было обнаружено, что гибридный режим превзошёл каждый из них в большинстве тестов.
Еще более простой метод — Reciprocal Rank Fusion (RRF), техника, объединяющая ранжирование из разных поисковых алгоритмов. RRF вычисляет оценку для каждого элемента на основе его ранга в каждом списке, где более высокие ранги получают лучшие оценки. Оценка определяется формулой 1 / (rank + k), где 'rank' — позиция элемента в списке, а 'k' — константа, используемая для регулирования влияния более низких рангов. Суммируя эти модифицированные обратные ранги из каждого источника, RRF подчеркивает согласие между различными системами. Этот метод сочетает сильные стороны различных алгоритмов, приводя к более надежным и всесторонним результатам поиска.

Таблица:
https://blog.vespa.ai/improving-zero-shot-ranking-with-vespa-part-two/
Формула:
https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf
Заключение
Векторный поиск — это больше, чем просто концепция или узкоспециализированная функция поисковых систем; это практический инструмент, меняющий то, как мы извлекаем данные. В последние годы область баз данных претерпела значительные изменения: появились новые векторно-ориентированные базы данных, а устоявшиеся добавили функции векторного поиска. Это отражает сильную потребность в более продвинутых поисковых функциях, которую может удовлетворить векторный поиск. Продвинутые методы индексации, такие как HNSW, сделали векторный поиск быстрее.
Смотря в будущее, мы ожидаем, что базы данных будут делать больше, чем просто поддерживать векторный поиск; они, вероятно, будут самостоятельно создавать эмбеддинги. Это сделает базы данных проще в использовании и мощнее, превратив их из простых хранилищ в интеллектуальные системы, способные понимать и анализировать данные. Короче говоря, векторный поиск представляет собой значительный сдвиг в управлении и извлечении данных, отмечая захватывающее развитие в этой области.