
Содержание
- Векторный поиск в Manticore: детали
- Что такое эмбеддинги (и почему они важны)?
- Как работает векторный поиск?
- Начало работы: настройка векторного поиска
- Продвинутые функции поиска
- Применения в реальном мире
- Как ускорить векторный поиск: советы по производительности
- Как защитить векторные данные: варианты резервного копирования
- Как обеспечить доступность поисковой системы: репликация
- Векторный поиск в действии: живые демонстрации
- Запуск векторного поиска в продакшн
- Заключение: будущее векторного поиска
1. Векторный поиск в Manticore: детали
Если вы следите за нашим блогом, вы уже знаете, что Manticore Search предлагает мощные возможности векторного поиска. В этом посте мы выйдем за рамки основ, чтобы показать, как всё работает за кулисами — и как вы можете извлечь из этого максимум.
Прежде чем перейти к техническим деталям, небольшое объявление: 6 июня 2025, команда Manticore спонсирует Vector Search Conference 2025

Мы проведём два доклада, посвящённые реальному векторному поиску:
- Скорость встречает точность: как векторная квантизация ускоряет поиск — Сергей Николаев
- Время RAG: более умные ответы с Retrieval-Augmented Generation — Дмитрий Кузьменков
Если вы работаете с семантическим поиском, рекомендациями или Retrieval-Augmented Generation (RAG), это событие, которое вы не захотите пропустить
Итак, возвращаемся к теме.
Векторный поиск Manticore построен поверх нашей Колонковой библиотеки и позволяет вам:
- Находить контент со схожим смыслом, даже если слова различаются
- Создавать рекомендательные системы, которые ощущаются персональными
- Группировать похожие элементы вместе без ручной разметки
- Предоставлять результаты поиска, гораздо более релевантные, чем простое совпадение по ключевым словам
Внутри Manticore использует высокоэффективный алгоритм HNSW (Hierarchical Navigable Small World) для векторного поиска. Он разработан для быстрого нахождения самых релевантных результатов даже в больших наборах данных — как поиск ближайших соседей в огромном городе, но без необходимости карты.
Разберём, как эмбеддинги дают возможность всему этому работать, и как HNSW помогает превратить эти эмбеддинги в быстрые и точные результаты поиска.
2. Что такое эмбеддинги (и почему они важны)?
Чтобы понять векторный поиск, вам сначала нужно знать о эмбеддингах. Они являются основной идеей всего этого.
Подумайте об эмбеддингах как о способе преобразования вещей — слов, изображений или звуков — в список чисел, представляющих их смысл. Это метод, который помогает компьютерам “понимать” мир ближе к тому, как делаем это мы.
Как работают эмбеддинги?
Представьте огромную карту, где каждая точка соответствует чему‑то: слову, предложению, изображению и т.д. Чем ближе две точки, тем более похожи представляемые ими вещи. Именно это делают эмбеддинги — они преобразуют данные в векторы (просто последовательности чисел), которые:
- Размещают похожие вещи рядом друг с другом в этом многомерном пространстве
- Захватывают смысл данных
– Позволяет нам выполнять математические операции с идеями (вспомните известный пример из Word2Vec от исследователей Google: king – man + woman = queen ?)

Что можно превратить в векторы?
Почти всё. Некоторые распространённые примеры включают:
- Текст: отдельные слова, полные предложения или даже целые книги. Вектор для "beach" будет ближе к "shore", чем к "mountain".
- Изображения: фотографии путешествий, изображения товаров или мемы. Фотографии собак окажутся ближе друг к другу, чем к фотографиям машин.
- Аудио: речь, музыка или звуковые эффекты. Треки хэви‑металла группируются вместе, далеко от тихой фортепианной музыки.
Эти эмбеддинги являются отправной точкой. Как только они у вас есть, алгоритмы вроде HNSW помогают быстро искать по ним.
Как измерять схожесть?
Как только у нас есть эти векторы, нам нужен способ измерить их схожесть. Manticore Search поддерживает три метрики схожести:
- Евклидово расстояние (L2)
- Косинусное сходство
- Внутреннее произведение (скалярное произведение)
Однако важно отметить, что выбор метрики схожести не произвольный. Оптимальная метрика часто зависит от модели эмбеддингов, использованной для генерации векторов. Многие модели эмбеддингов обучаются с учётом конкретной меры схожести. Например, некоторые модели оптимизированы под косинусное сходство, в то время как другие могут быть разработаны для внутреннего произведения или евклидова расстояния. Использование иной меры схожести, отличной от той, на которой модель была обучена, может привести к субоптимальным результатам.
При настройке таблицы Manticore Search для векторного поиска вы указываете метрику схожести в процессе создания таблицы. Этот выбор должен соответствовать характеристикам вашей модели эмбеддингов, чтобы обеспечить точные и эффективные результаты поиска.
Ниже краткий обзор каждой метрики:
Евклидово расстояние (L2): измеряет прямолинейное расстояние между двумя векторами в пространстве. Оно чувствительно к величине векторов и подходит, когда имеют смысл абсолютные различия.
Косинусное сходство: измеряет косинус угла между двумя векторами, сосредотачивая внимание на их ориентации, а не на величине. Обычно используется в текстовом анализе, где направление вектора (представляющего концепцию) важнее его длины.
Скалярное произведение (Dot Product): вычисляет сумму произведений соответствующих элементов двух последовательностей чисел. Эффективно, когда важны как величина, так и направление векторов.
Как создаются эти векторы?
Чтобы использовать поиск по векторам, сначала необходимо преобразовать ваши данные в векторы — и здесь на помощь приходят модели встраивания. Эти модели берут необработанные данные, такие как текст, изображения или аудио, и превращают их в числовые представления, фиксирующие смысл, контекст или признаки.
Ниже перечислены некоторые широко используемые модели, генерирующие встраивания:
- Word2Vec: Одна из первых моделей векторного представления слов. Она продемонстрировала, что отношения между словами можно зафиксировать математически — например, «king» относится к «queen», как «man» относится к «woman».
- GloVe: Разработана Стэнфордом, эта модель также создает векторные представления слов, анализируя глобальную статистику совместной встречаемости слов. Она эффективна и по‑прежнему широко используется.
- FastText: От Facebook, эта модель улучшает Word2Vec, учитывая информацию о субсловах. Она может генерировать встраивания для ранее невиданных слов, разбивая их на части.
- BERT: Трансформер‑модель от Google, понимающая слова в контексте. Например, она различает «bank» в «river bank» и «bank account». Может создавать встраивания для предложений, абзацев или целых документов.
- MPNet / MiniLM / all-MiniLM-L6-v2: Это оптимизированные модели встраивания предложений из семейства SentenceTransformers, идеальные для задач, таких как семантический поиск, сопоставление FAQ и обнаружение дубликатов.
- OpenAI Embeddings (e.g.,
text-embedding-3-small): Это универсальные встраивания, используемые в приложениях, таких как поиск, кластеризация и классификация. - CLIP: Модель от OpenAI, понимающая как изображения, так и текст в одном пространстве. Покажите ей фото щенка, и она сопоставит его с текстом «cute dog».
- ResNet: Глубокая сверточная нейронная сеть, отлично преобразующая изображения в встраивания. Широко используется для визуального сходства и классификации изображений.
- VGG / EfficientNet / Vision Transformers (ViT): Другие мощные модели для изображений, широко применяемые для преобразования картинок в векторные встраивания.
- Whisper: Модель OpenAI для транскрибирования аудио в текст, который затем может быть вложен для задач, таких как голосовой поиск или классификация аудио.
Manticore Search работает со всеми этими моделями и не только. Он не привязывает вас к какой‑то конкретной модели — вы можете использовать любую, которая лучше всего подходит вашему проекту, будь то текст, изображения или аудио. Пока вы можете преобразовать данные в векторы, Manticore сможет их искать.
3. Как работает поиск по векторам?
Теперь, когда мы разобрали, что такое встраивания и как они отражают сходство, давайте посмотрим, как Manticore действительно осуществляет поиск по векторам. Реальная мощь скрывается за умным алгоритмом под названием HNSW — сокращённо от Hierarchical Navigable Small World.
Да, это звучит как что‑то из научно‑фантастического романа — и, честно говоря, так и есть. Но вместо того, чтобы вести космические корабли через червоточины, HNSW помогает нам быстро перемещаться по огромным коллекциям векторов.
HNSW: Алгоритм с ужасным названием

Поиск в огромном векторном индексе похож на поиск иголки в стоге сена — только в этом стоге миллионы соломок, и некоторые из них выглядят очень похожими на иголку. Если бы вам пришлось проверять каждую по отдельности, это заняло бы вечность.
Именно здесь на помощь приходит HNSW. Он строит умную структуру, позволяющую пропускать большую часть стога и быстро сосредотачиваться на лучших кандидатах.
Вот как это работает:
- Он создает несколько слоёв векторов — как многоэтажное здание или слоёный торт.
- Нижний слой содержит каждый отдельный вектор — ваш полный набор данных.
- Каждый высший слой содержит меньше векторов и более дальние связи.
- При поиске он начинается с верхнего слоя, который позволяет быстро перескакивать по данным.
- На каждом уровне он приближается к нужной области, уточняя поиск по мере спуска.
- К моменту, когда он достигает нижнего слоя, он уже находится в нужном районе.
Такой многослойный подход позволяет избежать сканирования всего набора данных. Вместо этого вы быстро приближаетесь — что делает поиск по векторам в Manticore сверхэффективным.
А как насчёт точности?
Есть небольшая компромисса. Поскольку HNSW пропускает большую часть данных при поиске, существует вероятность, что он не найдёт абсолютно лучший результат — а лишь очень хороший. В большинстве реальных сценариев это полностью приемлемо. Будь то семантический поиск, рекомендации товаров или кластеризация похожих документов, «очень близко» более чем достаточно.
Но если ваш случай использования требует 100 % точности — например, сопоставление ДНК‑последовательностей или проведение научных анализов — вам может потребоваться метод полного перебора. Он будет медленнее, но полностью точен.
Для всех остальных задач HNSW предоставляет лучшее из обоих миров: молниеносную скорость и высокую точность.
Структура алгоритма HNSW

Настройте под себя
Поиск по векторам в Manticore не только быстрый — он также гибкий. Вы можете настроить несколько ключевых параметров, чтобы лучше соответствовать вашему конкретному случаю, в зависимости от того, что для вас важнее: скорость, точность, расход памяти или время построения индекса.
Вот основные параметры, которые вы можете регулировать:
hnsw_m(по умолчанию: 16): Управляет количеством соединений, которые каждый вектор устанавливает с другими — как количество друзей у человека в социальной сети. Большее число соединений повышает точность поиска, но также увеличивает расход памяти и слегка замедляет запросы.hnsw_ef_construction(default: 200): Эта настройка влияет на то, насколько тщательно строится индекс. Более высокие значения дают лучшее качество (и, следовательно, лучшие результаты поиска), но также делают процесс индексации медленнее и более требовательным к памяти.
These two parameters let you find the right balance between:
- 🔍 Точность поиска — Насколько результаты близки к истинным ближайшим соседям
- ⚡ Скорость поиска — Как быстро возвращаются результаты
- 🧠 Использование памяти — Сколько ОЗУ потребляет индекс
- 🏗️ Время индексации — Сколько времени требуется для построения индекса
The default settings work well for most use cases, but here are some tips if you want to tweak:
- Want ultra-accurate results? Increase both
hnsw_mandhnsw_ef_construction - Tight on memory? Lower
hnsw_mto reduce connections - Need faster indexing? Lower
hnsw_ef_construction
Feel free to experiment — it's all about finding the sweet spot for your workload.
4. Начало работы: настройка векторного поиска
Understanding the theory is great — but now let's get hands‑on. Setting up vector search in Manticore is simple and flexible, and you can be up and running in just a few steps.
Что понадобится
To enable vector search, you'll need to define a table with at least one float_vector attribute. This is where your vectors — the actual embeddings — will be stored.
Ключевые настройки
When creating your table, there are three essential parameters you'll need to set:
knn_type: Установите значениеhnsw. (В настоящее время это единственный поддерживаемый вариант, так что выбирать нечего.)knn_dims: Определяет количество измерений ваших векторов. Значение зависит от используемой модели эмбеддингов:- BERT обычно использует 768
- CLIP часто использует 512
- Некоторые sentence transformers используют 384 или 1024
- Просто убедитесь, что он соответствует размеру векторов, которые вы будете вставлять
hnsw_similarity: Выберите метрику сходства, соответствующую способу обучения вашей модели эмбеддингов. Доступные варианты:L2(Евклидово расстояние): Используйте для геометрических данных, признаков изображений и любых случаев, где важна физическая дистанцияCOSINE: Лучший вариант для текстовых эмбеддингов, семантического поиска и когда важна направленность, а не величинаIP(Внутреннее произведение): Подходит для нормализованных векторов или сценариев, таких как рекомендации, где важны и размер, и направление
🔍 Совет: Большинство современных моделей текстовых эмбеддингов обучаются с учётом косинусного сходства. Если вы не уверены, проверьте документацию модели — или просто начните с
COSINEи экспериментируйте.
Once you've defined your table with these settings, you're ready to insert your vectors and start running lightning‑fast, similarity‑based searches.
Рабочий процесс векторного поиска

Рассмотрим реальный пример
Time to get hands‑on. Here's how you'd create a table to store image vectors in Manticore Search:
create table cool_images (
id int,
title text,
image_vector float_vector knn_type='hnsw' knn_dims='4' hnsw_similarity='l2'
);
Now let's add some data:
insert into cool_images values
(1, 'yellow bag', (0.653448,0.192478,0.017971,0.339821)),
(2, 'white bag', (-0.148894,0.748278,0.091892,-0.095406));
(Of course, your real vectors will probably have hundreds of dimensions — we're keeping it small here for clarity.)
Поддержка транзакций для векторных операций
Vector operations in Manticore are fully transactional, which means you can perform multiple operations in a row and make sure they either all succeed or none do. That's super useful when you're updating both vector and non‑vector fields and need to keep everything in sync.
Основы транзакций
- Transactions are supported for real‑time tables with vector attributes
- Each transaction is atomic - either all operations succeed or none do
- Transactions are integrated with binary logging for durability and consistency
- By default, each command is its own mini‑transaction (
autocommit = 1)
Что можно делать в транзакции
You can include the following operations in a transaction:
- INSERT: Добавить новые векторы
- REPLACE: Обновить существующие векторы
- DELETE: Удалить векторы
Vector fields don't support the UPDATE command. You can learn more about the difference between REPLACE and UPDATE here .
Как управлять транзакциями
You can control transactions in two ways:
- Автоматический режим (по умолчанию):
SET AUTOCOMMIT = 1
In this mode, each operation is automatically committed.
- Ручной режим:
SET AUTOCOMMIT = 0
This allows you to group multiple operations into a single transaction:
BEGIN;
INSERT INTO cool_images VALUES (3, 'red bag', (0.1, 0.2, 0.3, 0.4));
INSERT INTO cool_images VALUES (4, 'blue bag', (0.5, 0.6, 0.7, 0.8));
COMMIT;
Массовые операции
For bulk operations, you can use the /bulk endpoint which supports transactions for multiple vector operations:
POST /bulk
{
"insert": {"table": "cool_images", "id": 5, "doc": {"title": "green bag", "image_vector": [0.1, 0.2, 0.3, 0.4]}},
"insert": {"table": "cool_images", "id": 6, "doc": {"title": "purple bag", "image_vector": [0.5, 0.6, 0.7, 0.8]}}
}
Важные замечания
- Transactions are limited to a single real‑time table
- Vector operations in transactions are atomic and consistent
- Changes are not visible until explicitly committed
- The binary log ensures durability of vector operations
- Transactions are particularly useful when you need to maintain consistency between vector data and other attributes
Поиск похожих объектов
Now the cool part—searching for similar images:
Использование SQL:
select id, title, knn_dist()
from cool_images
where knn (image_vector, 5, (0.286569,-0.031816,0.066684,0.032926), 2000);
This gives us:
+------+------------+------------+
| id | title | knn_dist() |
+------+------------+------------+
| 1 | yellow bag | 0.28146550 |
| 2 | white bag | 0.81527930 |
+------+------------+------------+
The yellow bag is closer to our query vector (smaller distance value), so it's more similar to what we're looking for.
Использование HTTP API:
Manticore provides a RESTful HTTP API for vector search operations. The main endpoint for vector search is:
POST /search
The request body should be in JSON format with the following structure:
{
"table": "<table_name>",
"knn": {
"field": "<vector_field_name>",
"query_vector": [<vector_values>],
"k": <number_of_results>,
"ef": <search_accuracy>
}
}
Key parameters:
table: Имя таблицы, в которой производится поискknn.field: Имя векторного поля, по которому осуществляется поискknn.query_vector: Запросный вектор в виде массива значений floatknn.k: Количество ближайших соседей для возвратаknn.ef: (Опционально) Размер динамического списка, используемого во время поиска. Более высокие значения дают более точные, но более медленные результаты
Example request:
POST /search
{
"table": "products",
"knn": {
"field": "image_vector",
"query_vector": [0.1, 0.2, 0.3, 0.4],
"k": 5,
"ef": 2000
}
}
The response will be in JSON format:
{
"took": 6,
"timed_out": false,
"hits": {
"total": 2,
"total_relation": "eq",
"hits": [
{
"_id": 1,
"_score": 1,
"_knn_dist": 0.28146550,
"_source": {
"title": "yellow bag",
"image_vector": [0.653448, 0.192478, 0.017971, 0.339821]
}
},
{
"_id": 2,
"_score": 1,
"_knn_dist": 0.81527930,
"_source": {
"title": "white bag",
"image_vector": [-0.148894, 0.748278, 0.091892, -0.095406]
}
}
]
}
}
Ответ включает:
took: Время выполнения поиска в миллисекундахtimed_out: Было ли превышено время ожидания поискаhits.total: Общее количество найденных совпаденийhits.hits: Массив совпадающих документов, каждый из которых содержит:_id: Идентификатор документа_score: Оценка поиска (всегда 1 для KNN‑поиска)_knn_dist: Расстояние до векторa запроса_source: Исходные данные документа
Вы также можете комбинировать KNN‑поиск с дополнительными фильтрами:
POST /search
{
"table": "products",
"knn": {
"field": "image_vector",
"query_vector": [0.1, 0.2, 0.3, 0.4],
"k": 5,
"filter": {
"bool": {
"must": [
{ "match": {"_all": "white"} },
{ "range": { "id": { "lt": 10 } } }
]
}
}
}
}

5. Расширенные возможности поиска
Имея базовые настройки и конфигурацию, давайте изучим мощные возможности, которые векторный поиск предоставляет вашим приложениям. Эти функции выходят далеко за рамки традиционного поиска по ключевым словам.
Два способа поиска
Вы можете искать двумя основными способами:
- Direct Vector Search: Дайте мне вещи, похожие на этот вектор. Отлично подходит, когда у вас есть векторное представление того, что вам нужно (например, эмбеддинг изображения или текста).
-- Example: Find items similar to a specific vector SELECT id, knn_dist() FROM products WHERE knn(image_vector, 5, (0.286569,-0.031816,0.066684,0.032926)); - Similar Document Search: Дайте мне вещи, похожие на этот документ в моём индексе. Идеально для функций «показать похожее», когда пользователи могут кликнуть на понравившийся элемент и найти похожие товары.
-- Example: Find items similar to document with ID 1 SELECT id, knn_dist() FROM products WHERE knn(image_vector, 5, 1);
Оба метода возвращают результаты, отсортированные по схожести (расстоянию) к вашему запросу, при этом наиболее похожие элементы находятся в начале.
Тонкая настройка поиска
Две важные настройки определяют поведение вашего поиска:
kparameter: Сколько результатов вы хотите получить. Слишком мало — вы можете упустить хорошие совпадения. Слишком много — появятся нерелевантные результаты.efparameter: Насколько усердно алгоритм пытается найти лучшие совпадения. Более высокие значения дают более точные результаты, но требуют больше времени.
Результаты сортируются по близости
Все результаты поиска автоматически сортируются по тому, насколько они близки к вашему вектору запроса. Функция knn_dist() показывает фактическое значение расстояния для каждого результата, позволяя увидеть, насколько они похожи (или различны).
Например, если мы ищем изображения, похожие на вектор запроса:
select id, title, knn_dist()
from images
where knn (image_vector, 3, (0.1, 0.2, 0.3, 0.4));
Результаты будут автоматически отсортированы по расстоянию, начиная с самых близких:
+------+----------------+------------+
| id | title | knn_dist() |
+------+----------------+------------+
| 1 | sunset beach | 0.12345678 |
| 3 | ocean view | 0.23456789 |
| 2 | mountain lake | 0.34567890 |
+------+----------------+------------+
Обратите внимание, как значения knn_dist() увеличиваются по мере продвижения вниз списка — это показывает, что каждый последующий результат менее похож на наш вектор запроса.
Сочетание с обычным поиском
Настоящая магия происходит, когда вы комбинируете векторный поиск с традиционными фильтрами. Например, можно найти изображения, похожие на вектор, одновременно отфильтровав их по тексту:
select id, title, knn_dist()
from cool_images
where knn (image_vector, 5, (0.286569,-0.031816,0.066684,0.032926))
and match('white');
Это ищет изображения, похожие на наш вектор, но только если они содержат слово «white»:
+------+-----------+------------+
| id | title | knn_dist() |
+------+-----------+------------+
| 2 | white bag | 0.81527930 |
+------+-----------+------------+
Хотя желтая сумка была технически более похожа (по вектору), она не прошла текстовый фильтр, поэтому отображается только белая сумка.
6. Реальные примеры применения
Теперь, когда мы рассмотрели основные возможности, давайте посмотрим на реальные сценарии, где векторный поиск может преобразовать пользовательский опыт. Эти примеры помогут понять, как применять концепции в собственных проектах.
Умный поиск, понимающий ваш смысл

Когда‑то вы искали что‑то и думали: «Это не то, что я имел в виду!»? Умный поиск понимает смысл вашего запроса, а не только точные слова.
С помощью векторного поиска вы можете:
- Находить результаты, соответствующие тому, что вы ищете, даже если используются другие слова
- Искать по разным языкам (смысл переводится, а не отдельные слова)
- По‑настоящему понимать, что ищут пользователи
Пример из реального мира: База знаний, где клиенты находят нужную статью помощи, даже если используют терминологию, отличную от вашей документации.
Рекомендательные системы, которые имеют смысл

Мы все сталкивались с плохими рекомендациями: «Вы купили холодильник, хотите ещё один холодильник?». Векторный поиск помогает создавать рекомендации, которые имеют смысл:
- Находить товары, похожие на те, что понравились клиенту
- Сопоставлять предпочтения пользователя с предметами
- Рекомендовать товары из разных категорий на основе общих атрибутов
- Персонализировать результаты поиска в зависимости от истории просмотров
Пример из реального мира: Интернет‑магазин, который может порекомендовать синюю кожаную куртку после того, как вы посмотрели синюю кожаную сумку, потому что понимает стилистическую связь.
Поиск изображений, видящий как вы

Традиционный поиск изображений опирается на текстовые теги и метаданные. Векторный поиск позволяет:
- Находить изображения, визуально похожие друг на друга
- Загружать изображение и находить совпадающие (обратный поиск по изображению)
- Группировать похожие изображения без ручного тегирования
- Обнаруживать дубликаты или почти‑дубликаты
Пример из реального мира: Стоковый фотосайт, где дизайнеры могут находить визуально похожие изображения, загрузив референс‑изображение или эскиз концепции.
Поиск видео и звука за пределами тегов
Примените те же принципы к видео и аудио:
- Находить похожие видеоклипы по их содержимому
- Искать музыку по «звучит как это», а не только по жанровым тегам
- Находить моменты в видео с похожими визуальными элементами
- Обнаруживать дублирующие или похожие аудиотреки
Пример из реального мира: Платформа видеомонтажа, которая мгновенно находит все клипы с похожей визуальной композицией во всех ваших проектах.
Поиск на разных языках
Векторный поиск действительно раскрывает свой потенциал в многоязычных приложениях. С правильными эмбеддингами вы можете искать по разным языкам — без необходимости вручную переводить запросы или документы.
Как работает кросс‑языковой поиск
- Языково-независимые эмбеддинги
Современные многоязычные модели, такие как mBERT, XLM-R и LaBSE, обучаются размещать семантически похожий текст — даже на разных языках — близко друг к другу в одном векторном пространстве.
Это означает, что «apple» на английском и «manzana» на испанском оказываются рядом. Поэтому, когда вы ищете на одном языке, вы можете находить результаты, написанные на другом. - Простая настройка таблицы
create table multilingual_docs ( id bigint, content text, language string, content_vector float_vector knn_type='hnsw' knn_dims='768' hnsw_similarity='cosine' );- Храните документы на их оригинальном языке
- Генерируйте эмбеддинги с помощью многоязычной модели
- Поиск просто работает — независимо от того, на каком языке запрос или документ
- Поиск по разным языкам:
select id, content, language, knn_dist() from multilingual_docs where knn (content_vector, 5, (0.1, 0.2, ...));- Введите ваш запрос на любом поддерживаемом языке
- Результаты возвращаются на основе смысла, а не языка
- Не требуется перевод или определение языка
Применения в реальном мире
Многоязычный векторный поиск открывает широкий спектр глобальных сценариев использования, таких как:
- Глобальная электронная коммерция: Поиск и рекомендация товаров на разных языках, а также поддержка международных запросов клиентов
- Управление контентом: Поиск похожих документов, обнаружение дубликатов и создание многоязычных баз знаний
- Поддержка клиентов: Сопоставление вопросов и ответов на разных языках и интеллектуальная маршрутизация тикетов поддержки
- Социальные сети и сообщества: Открытие контента, трендов и пользователей за пределами языковых границ
С правильными многоязычными эмбеддингами вы можете создавать поисковые интерфейсы, которые ощущаются безшовными — независимо от того, на каком языке говорят ваши пользователи.
Советы по реализации
- Выберите правильную модель
Выбирайте многоязычные модели эмбеддингов, такие как LaBSE, XLM-R или mBERT, в зависимости от ваших языковых потребностей и задачи. Убедитесь, что выбранная модель поддерживает языки, которые вы ожидаете как в запросах, так и в документах. - Тщательно предобрабатывайте
Нормализуйте и очищайте входной текст последовательно для всех языков перед генерацией эмбеддингов. Даже небольшие различия в предобработке (например, пунктуация или регистр) могут влиять на качество векторов. - Сохраняйте информацию о языке
Храните полеlanguageв ваших данных. Хотя векторный поиск не требует его, оно может помочь в фильтрации, аналитике или улучшении пользовательского опыта. - Проектируйте для ясности
Отображайте информацию о языке в результатах поиска и позволяйте пользователям легко фильтровать или переключать языки — особенно если ваше приложение использует несколько языков.
С этими настройками вы будете готовы создавать поисковые функции, которые естественно работают с разными языками — без необходимости в слоях перевода.
7. Как ускорить векторный поиск: советы по производительности
Создание крутых функций — это здорово, но они должны работать эффективно в продакшене. Давайте разберёмся с вопросами производительности и стратегиями оптимизации, которые обеспечат плавную работу вашего векторного поиска.
Понимание RAM vs. Disk хранилища
В Manticore векторный поиск работает по‑разному в зависимости от того, хранятся ли ваши векторы в RAM‑чанках или в дисковых чанках:
- Дисковые чанки:
- Каждый дисковый чанк поддерживает собственный независимый HNSW‑индекс
- Для KNN‑запросов, охватывающих несколько дисковых чанков, индекс каждого чанка ищется отдельно
- Это может влиять на точность поиска, поскольку граф HNSW каждого чанка ограничен векторами внутри этого чанка
- При поиске по множеству дисковых чанков производительность запросов может снижаться
- Для таблиц с векторными атрибутами Manticore автоматически задаёт более низкое значение optimize_cutoff (количество физических ядер CPU, делённое на 2) для повышения производительности векторного поиска
- RAM‑чанк:
- Использует более прямой подход к поиску векторов
- Может обеспечивать более быстрые результаты для недавно добавленных данных
- По мере роста RAM‑чанка производительность векторного поиска может постепенно ухудшаться
- Каждый RAM‑чанк в конечном итоге превращается в дисковый чанк, когда достигает предела размера, определённого
rt_mem_limit(по умолчанию 128M), или когда вы явно конвертируете его с помощьюFLUSH RAMCHUNK
Для оптимальной производительности векторного поиска учитывайте:
- Использование пакетных вставок для минимизации фрагментации сегментов RAM‑чанка
- Использование функции auto-optimize в Manticore, которая автоматически объединяет дисковые чанки для поддержания оптимальной производительности
- Настройка
optimize_cutoffв зависимости от вашей конкретной нагрузки и ресурсов CPU - Использование настроек
diskchunk_flush_write_timeoutиdiskchunk_flush_search_timeoutдля управления поведением авто‑сброса
Производительность векторного поиска по дисковым чанкам зависит от количества чанков и их распределения. Меньшее количество дисковых чанков обычно обеспечивает лучшую производительность KNN‑поиска, чем множество небольших чанков.
Понимание параметра ef
Параметр ef позволяет балансировать скорость и точность:
- Что он делает:
- Более высокие значения дают более точные результаты, но требуют больше времени
- Более низкие значения работают быстрее, но могут упустить некоторые хорошие совпадения
- Поиск оптимального значения:
- Начните с значения по умолчанию (200)
- Увеличьте, если точность критична
- Уменьшите, если важна скорость
- Протестируйте на реальных данных!
8. Как сохранить ваши векторные данные в безопасности: варианты резервного копирования
По мере роста вашей реализации векторного поиска обеспечение безопасности данных становится критически важным. Давайте рассмотрим стратегии резервного копирования, специально разработанные для векторных данных в Manticore.
Физическое резервное копирование
Физические резервные копии особенно подходят для векторных данных, потому что:
- Скорость: Они напрямую копируют файлы с необработанными векторными данными, что критично для больших наборов векторов
- Последовательность: Они гарантируют, что все векторные данные и индексы HNSW сохраняются вместе
- Низкая нагрузка на систему: Не требуют дополнительной обработки векторных данных
Вы можете использовать любой из вариантов:
- Инструмент командной строки
manticore-backup:
manticore-backup --backup-dir=/path/to/backup --tables=your_vector_table
- Команду SQL BACKUP:
BACKUP TABLE your_vector_table TO /path/to/backup
Логическое резервное копирование
Логические резервные копии могут быть полезны для векторных данных, когда вам требуется:
- Переносимость: Перемещение векторных данных между различными системами
- Избирательное восстановление: Восстановление конкретных векторных атрибутов или измерений
- Миграция версий: Переход между разными версиями Manticore. Более новые версии обычно поддерживают обратную совместимость, поэтому при обновлении, скорее всего, вам не понадобится использовать дамп данных. Однако при переходе на более старую версию использование дампа может быть полезным.
Вы можете использовать mysqldump для логических резервных копий векторных данных:
mysqldump -h0 -P9306 -e "SELECT * FROM your_vector_table" > vector_backup.sql
Лучшие практики резервного копирования векторных данных
Как и при любом другом типе резервного копирования, существуют хорошие практики, которым следует придерживаться при резервном копировании ваших векторных данных.
- Регулярные резервные копии:
- Настраивайте регулярные резервные копии, особенно после крупных обновлений ваших векторных данных
- Учитывайте размер ваших векторных данных при решении, как часто выполнять резервное копирование
- Место хранения резервных копий:
- Сохраняйте резервные копии в месте, где достаточно места для больших векторных данных
- Используйте сжатие, если ваши векторные данные очень большие
- Тестирование:
- Регулярно проверяйте свои резервные копии, чтобы убедиться, что их можно восстановить
- После восстановления проверьте, что векторный поиск работает корректно
- Контроль версий:
- Ведите учет версии Manticore, которую вы используете
- Убедитесь, что ваши резервные копии будут работать с этой версией, если понадобится восстановление
- Мониторинг:
- Следите за размером резервных копий и временем их создания
- Настраивайте оповещения на случай неудачных резервных копий
9. Обеспечение доступности поисковой системы: Репликация
Помимо резервных копий, высокая доступность важна для производственных систем. Давайте рассмотрим, как функции репликации Manticore работают с векторным поиском, чтобы ваша система оставалась доступной и согласованной.
Репликация с несколькими мастерами
Manticore поддерживает библиотеку Galera для репликации и предлагает несколько ключевых возможностей:
- Истинный Multi-Master: Операции чтения и записи могут выполняться на любом узле в любой момент
- Практически синхронный: Нет отставания реплик и потери данных после сбоев узла
- Горячий резерв: Нулевой простой в сценариях переключения
- Тесно связанный: Все узлы поддерживают одинаковое состояние без расхождений данных
- Автоматическое предоставление узлов: Для новых узлов не требуется ручное резервное копирование/восстановление
- Репликация на основе сертификации: Обеспечивает согласованность данных в кластере
Настройка репликации для векторного поиска
Чтобы включить репликацию для векторного поиска:
- Требования к конфигурации:
- Параметр
data_dirустановлен по умолчанию в конфигурации searchd - Директива
listenс доступным IP-адресом является необязательной — репликация будет работать без неё - При желании задайте уникальные значения
server_idдля каждого узла
- Параметр
- Создание репликационного кластера:
CREATE CLUSTER vector_cluster - Добавление векторных таблиц в кластер:
ALTER CLUSTER vector_cluster ADD vector_table - Подключение узлов к кластеру:
JOIN CLUSTER vector_cluster AT 'host:port'
При работе с векторными данными в реплицированной среде:
- Операции записи:
- Все изменения векторов (INSERT, REPLACE, DELETE, TRUNCATE) должны использовать синтаксис
cluster_name:table_name - Изменения автоматически распространяются на все реплики
- Операции с векторами поддерживают согласованность в кластере
- Все изменения векторов (INSERT, REPLACE, DELETE, TRUNCATE) должны использовать синтаксис
- Поддержка транзакций:
- Операции с векторами атомарны в кластере
- Изменения не видны до явного подтверждения
- Бинарный журнал обеспечивает надёжность операций с векторами
Ограничения и соображения
- Репликация поддерживается для таблиц реального времени с векторными атрибутами
- Нативные бинарные файлы Windows не поддерживают репликацию (используйте WSL)
- macOS имеет ограниченную поддержку репликации (рекомендовано только для разработки)
- Каждая таблица может принадлежать только одному кластеру
10. Векторный поиск в действии: живые демонстрации
Теория и конфигурация важны, но видеть значит верить. Давайте рассмотрим несколько реальных демонстраций, показывающих возможности векторного поиска Manticore в действии.
Поиск по GitHub Issue
Наш демо‑поиск по GitHub Issue позволяет искать по GitHub Issue, понимая смысл слов. В отличие от встроенного поиска GitHub, который только сопоставляет ключевые слова, наш демо‑пример понимает, что вы ищете.
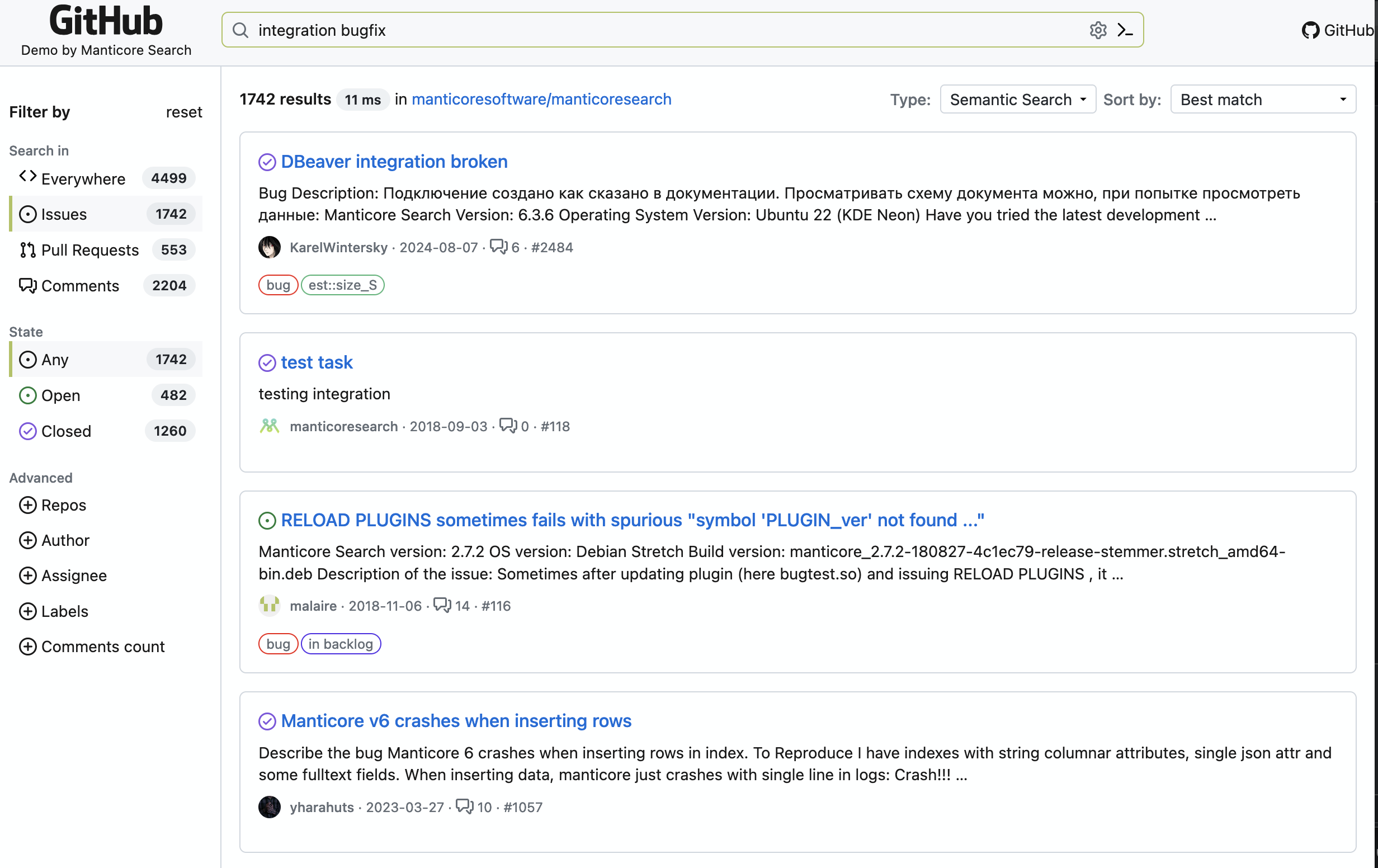
Этот демо‑пример построен на векторных возможностях Manticore Search и полностью открыт. Вы можете изучить исходный код на GitHub , чтобы увидеть, как мы его реализовали.
Попробуйте искать по концепциям, а не только по ключевым словам — поиск понимает, что вы ищете, даже если точные слова не совпадают!
Как работает демо‑пример поиска по GitHub Issue
Демо‑пример поиска по GitHub Issue использует мощную модель встраивания, чтобы преобразовать как GitHub Issue, так и ваши поисковые запросы в семантические векторные представления. Это позволяет системе находить Issue, концептуально схожие с вашим запросом, даже если они используют другую терминологию.
Ключевые возможности:
- Умный поиск по тысячам GitHub Issue
- Реальное время фильтрации по репозиторию, меткам и др.
- Удобный интерфейс с подсветкой синтаксиса
- Быстрый отклик благодаря алгоритму HNSW от Manticore
Этот подход значительно улучшает качество поиска по сравнению с традиционным поиском по ключевым словам, помогая разработчикам находить решения своих проблем более эффективно.
Демонстрация поиска по изображениям
Наш демо‑пример поиска по изображениям демонстрирует, как векторный поиск может обеспечить поиск визуального сходства. Загрузите любое изображение, и система найдет визуально похожие изображения, основываясь на содержимом картинки, а не только на тегах или метаданных.
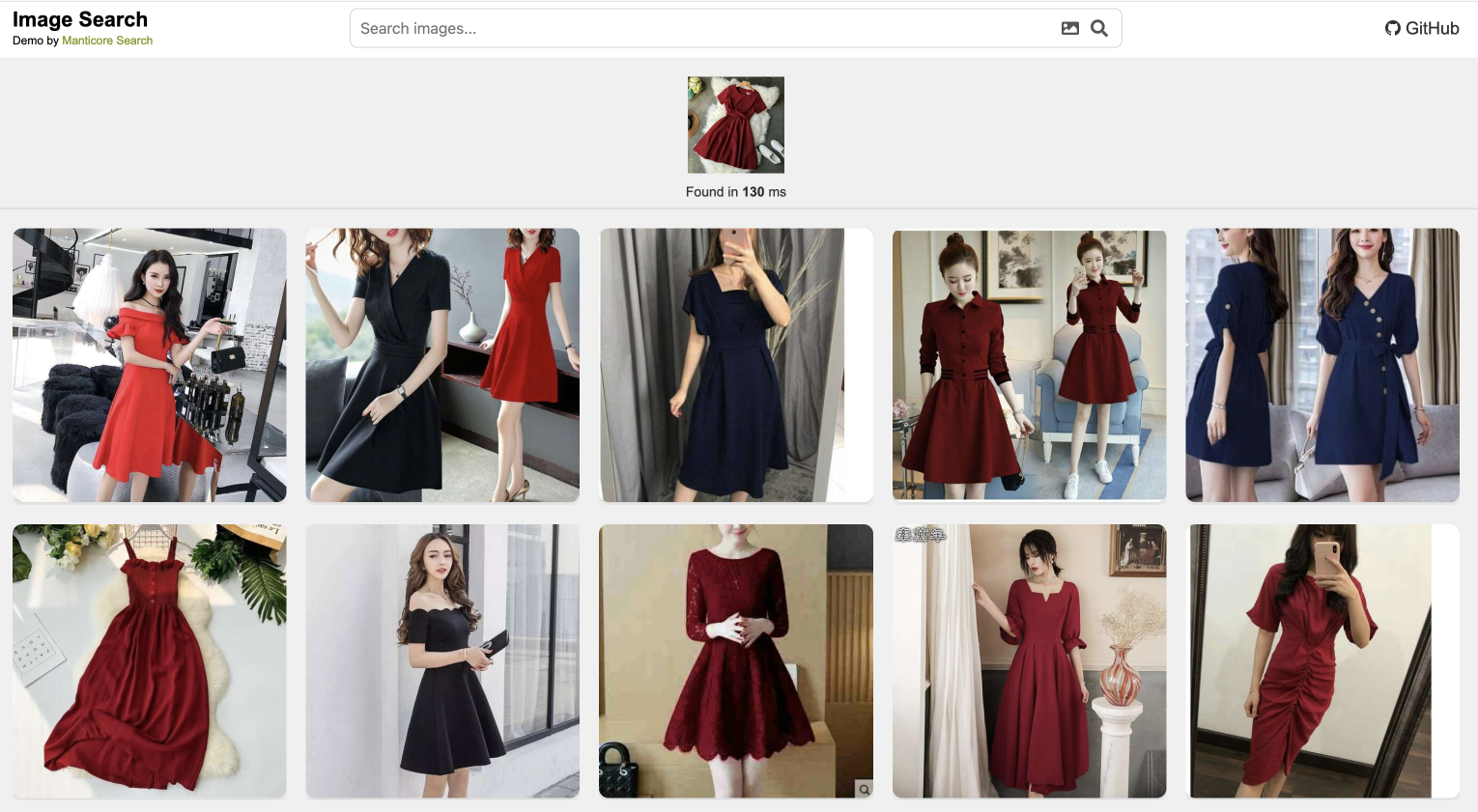
Этот демо‑пример использует модель машинного обучения для преобразования изображений в векторы, а затем использует KNN‑поиск Manticore для нахождения похожих изображений. Исходный код доступен в нашем репозитории manticore-image-search .
Как работает демо‑пример поиска по изображениям
Демонстрация поиска изображений использует предварительно обученную модель зрения для извлечения значимых признаков из изображений и представления их в виде высокоразмерных векторов. Когда вы загружаете изображение или выбираете его из галереи:
- Изображение обрабатывается моделью зрения для создания векторного признака
- Векторный поиск Manticore находит ближайших соседей к этому вектору
- Возвращаются наиболее похожие изображения, ранжированные по их оценке схожести
- Всё это происходит за миллисекунды, обеспечивая плавный пользовательский опыт
Демонстрация обрабатывает разнообразные типы изображений и может находить сходства на основе содержания, стиля, цветовых паттернов и даже абстрактных концепций, присутствующих в изображениях.
Create Your Own Demo
Обе демонстрации являются отличными отправными точками для создания собственных приложений векторного поиска. Если вас интересует:
- Поиск умных документов
- Системы поиска изображений или видео
- Рекомендательные движки
- Классификация контента
Вы можете использовать ту же архитектуру и адаптировать её под ваш конкретный случай. Исходный код обеих демонстраций предоставляет практические примеры того, как:
- Генерировать эмбеддинги для ваших данных
- Структурировать ваши таблицы Manticore для векторного поиска
- Реализовать эффективные API поиска
- Создавать удобные пользовательские интерфейсы
Эти демонстрации показывают, как векторный поиск может применяться к реальным задачам с впечатляющими результатами. Они также полностью открыты, так что вы можете учиться у них или даже развернуть свою собственную версию!
Настраивая эти параметры, вы можете сделать векторный поиск молниеносным для ваших конкретных нужд. Помните, правильная конфигурация зависит от ваших данных, вашего оборудования и от того, чего вы хотите достичь. Не бойтесь экспериментировать!
11. Running Vector Search in Production
После изучения всех этих функций и возможностей пришло время обсудить, что требуется для развертывания векторного поиска в производственной среде. Давайте рассмотрим критические факторы, которые обеспечат надёжность, масштабируемость и оптимальную производительность вашей реализации.
What You Need: Infrastructure Requirements
- Аппаратные соображения:
- CPU: Векторные операции требуют интенсивного использования процессора
- Modern multi-core processors recommended
- Consider CPU cache size for vector operations
- Monitor CPU utilization during peak loads
- Память:
- HNSW indexes require significant RAM
- Планируйте 2-3× объём ваших векторных данных
- Consider memory fragmentation over time
- Хранилище:
- Fast SSDs recommended for disk chunks
- Consider RAID configurations for reliability
- Планируйте требования к резервному хранилищу
- CPU: Векторные операции требуют интенсивного использования процессора
- Сетевые настройки:
- High bandwidth for replication
- Low latency for distributed setups
- Proper firewall rules for cluster communication
- Load balancer configuration for high availability
12. Conclusion: The Future of Vector Search
Векторный поиск представляет собой фундаментальный сдвиг в том, как мы подходим к поиску и сопоставлению схожести в современных приложениях. В ходе этого глубокого погружения мы изучили, как Manticore Search реализует эту мощную технологию, от базовых концепций эмбеддингов до готовых к производству стратегий развертывания.
Ключевые выводы нашего исследования:
- Мощные возможности: Векторный поиск позволяет понять смысл слов, выходя за рамки традиционного сопоставления по ключевым словам, чтобы находить действительно релевантные результаты, основанные на значении и контексте.
- Гибкая реализация: Векторный поиск Manticore может применяться к различным сценариям, от текстового поиска до сопоставления изображений, рекомендаций и многоязычных приложений.
- Готовность к продакшену: Благодаря таким функциям, как репликация, варианты резервного копирования и оптимизация производительности, векторный поиск Manticore готов к корпоративному развертыванию.
- Лёгкость начала работы: Несмотря на свои сложные возможности, векторный поиск в Manticore доступен и может быть реализован с минимальной конфигурацией.
Смотря в будущее, векторный поиск будет продолжать развиваться и становиться ещё более неотъемлемой частью современных приложений. Способность понимать и сопоставлять контент на основе смысла, а не только ключевых слов, трансформирует взаимодействие пользователей с данными. Независимо от того, создаёте ли вы поисковый движок, рекомендательную систему или платформу для обнаружения контента, векторный поиск предоставляет основу для создания более интеллектуальных и удобных приложений.
Чтобы начать использовать векторный поиск в своих проектах, ознакомьтесь с нашим репозиторием на GitHub и присоединяйтесь к нашему сообществу . Мы рады увидеть, что вы создадите с возможностями векторного поиска Manticore!
Помните: лучший способ понять мощь векторного поиска — попробовать его самостоятельно. Начните с наших демонстраций и экспериментируйте со своими случаями использования. Возможности безграничны, и мы готовы помочь вам их исследовать.