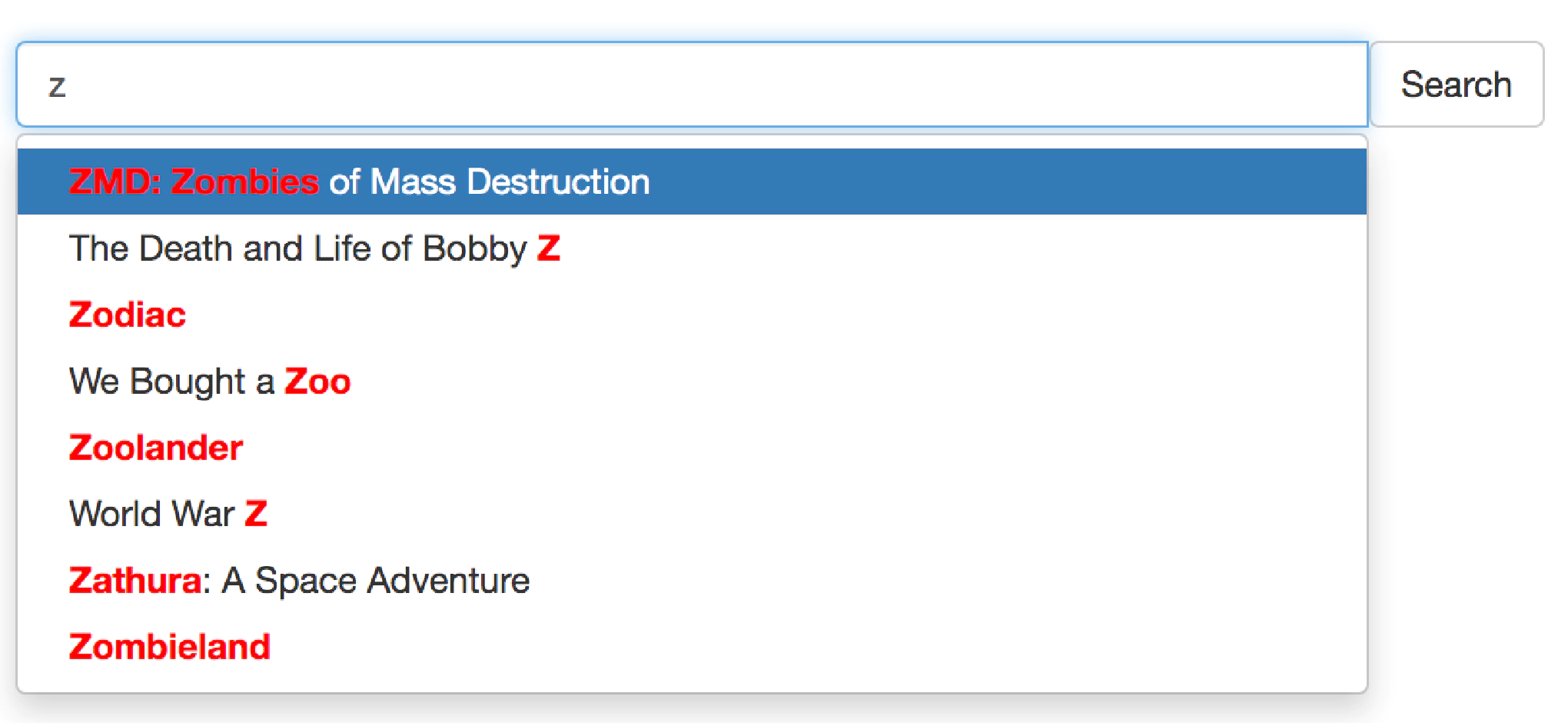
В этой статье описывается один из способов реализации автодополнения в Manticore Search.
Что такое автодополнение?
Автодополнение (или завершение слова) — это функция, позволяющая приложению предсказывать оставшуюся часть слова, пока пользователь его вводит. Обычно это работает так: пользователь начинает вводить слово в строке поиска, и появляется выпадающий список с предложениями, из которого пользователь может выбрать один.
Источник предложений может быть разным. Лучше всего, если слово или фраза, отображаемая в подсказке, присутствует в существующей коллекции данных, чтобы пользователь не выбирал то, что вернёт пустой результат. Однако в некоторых случаях автодополнение основано на предыдущих (успешных) поисках, которые теоретически могут не дать результатов, но всё равно иметь смысл. Всё зависит от особенностей вашего приложения.
Самое простое автодополнение можно реализовать, находя подсказки в заголовках элементов набора данных. Это может быть заголовок статьи/новости, название продукта или, как мы скоро покажем, название фильма. Для этого необходимо, чтобы поле было определено как string attribute или stored field . Это позволяет избежать дополнительного обращения к оригинальным данным.
Поскольку пользователь вводит неполное слово, нам необходимо выполнить поиск с подстановочными символами. Поиск с подстановками возможен при включении префиксного или инфиксного индекса. Поскольку это может повлиять на время отклика , вам нужно решить, хотите ли вы включить эту возможность в индексе, используемом для поиска, или включить её только в специальном индексе, предназначенном для автодополнения. Ещё одной причиной является возможность сделать последний как можно более компактным, чтобы обеспечить минимальную задержку, что особенно важно для UX автодополнения. Обычно мы добавляем символ подстановки (*) справа, предполагая, что пользователь начинает слово, однако для более широких результатов мы добавляем звёздочки с обеих сторон, чтобы получить слова, которые могут иметь префикс. В этом примере для набора данных фильмов выберем инфиксный поиск, так как он также включает функцию SUGGEST для исправления слов (см. как это работает в этом курсе ). Наше объявление индекса будет:
index movies {
type = plain
path = /var/lib/manticore/data/movies
source = movies
min_infix_len = 3
}
Поскольку мы будем предоставлять автодополнение по названию фильма, наши запросы будут ограничены полем 'movie_title'.
Автодополнение по названию фильма
Фронтенд вашего приложения может начинать запрашивать подсказки уже с первого введённого символа в поле поиска. Однако это может увеличить нагрузку на систему при большом индексе, так как будет происходить больше запросов к серверу, а поиск с подстановкой по 1‑2 символам может быть медленнее. Предположим, пользователь вводит 'sha'.
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title sha*');
+------+---------------------------------------+
| id | movie_title |
+------+---------------------------------------+
| 118 | A Low Down Dirty Shame |
| 394 | Austin Powers: The Spy Who Shagged Me |
| 604 | Book of Shadows: Blair Witch 2 |
| 951 | Dark Shadows |
| 1318 | Fifty Shades of Black |
| 1319 | Fifty Shades of Grey |
| 1389 | Forty Shades of Blue |
| 1853 | In the Shadow of the Moon |
| 1928 | Jack Ryan: Shadow Recruit |
| 3114 | Shade |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 3117 | Shadowlands |
| 3118 | Shaft |
| 3119 | Shakespeare in Love |
| 3120 | Shalako |
| 3121 | Shall We Dance |
| 3122 | Shallow Hal |
| 3123 | Shame |
| 3124 | Shanghai Calling |
+------+---------------------------------------+
20 rows in set (0.00 sec)
Мы в основном интересуемся только названием фильма, поэтому мы не возвращаем все столбцы. Как видим, возвращается много результатов. Мы можем попытаться настроить запрос, например, добавив вторичную сортировку по лайкам в Facebook, но пока ещё слишком рано делать точный вывод о том, что ищет пользователь:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title sha*') ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3131 | Shark Tale |
| 394 | Austin Powers: The Spy Who Shagged Me |
| 3118 | Shaft |
| 4326 | The Shaggy Dog |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3134 | Shattered |
| 3123 | Shame |
| 3525 | The Adventures of Sharkboy and Lavagirl 3-D |
| 3117 | Shadowlands |
| 3129 | Shark Lake |
| 4328 | The Shawshank Redemption |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 3135 | Shattered Glass |
| 3130 | Shark Night 3D |
| 1319 | Fifty Shades of Grey |
| 4619 | Tristram Shandy: A Cock and Bull Story |
| 118 | A Low Down Dirty Shame |
| 3132 | Sharknado |
| 1318 | Fifty Shades of Black |
+------+--------------------------------------------------+
20 rows in set (0.00 sec)
Предположим, пользователь вводит ещё одну букву:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shaf*') ORDER BY WEIGHT() DES , cast_total_facebook_likes DESC;
+------+-------------+
| id | movie_title |
+------+-------------+
| 3118 | Shaft |
+------+-------------+
1 row in set (0.00 sec)
Теперь у нас один единственный результат.
Возьмём другой пример, где мы вводим 'shad*' вместо этого.
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shad*') ORDER BY WEIGHT() DES , cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3117 | Shadowlands |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 1319 | Fifty Shades of Grey |
| 1318 | Fifty Shades of Black |
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 1389 | Forty Shades of Blue |
| 604 | Book of Shadows: Blair Witch 2 |
| 3114 | Shade |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+--------------------------------------------------+
15 rows in set (0.00 sec)
Затем shado*:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shado*') ORDER BY WEIGHT() DE C, cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3117 | Shadowlands |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 604 | Book of Shadows: Blair Witch 2 |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+--------------------------------------------------+
11 rows in set (0.00 sec)
И 'shadow':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shadow') ORDER BY WEIGHT() DE C, cast_total_facebook_likes DESC;
+------+---------------------------+
| id | movie_title |
+------+---------------------------+
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+---------------------------+
6 rows in set (0.00 sec)
Если пользователь искал 'shadow' как первое слово, он продолжит вводить следующее слово, например 'shadow c':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shadow c*') ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+------+-------------------+
| id | movie_title |
+------+-------------------+
| 3115 | Shadow Conspiracy |
+------+-------------------+
1 row in set (0.01 sec)
В этом случае мы получаем один результат, который должен удовлетворить пользователя, но в других случаях может быть больше результатов, и пользователь будет продолжать вводить буквы, как и для первого слова, а Manticore будет возвращать больше подсказок на основе ввода:

Добавление дополнительных фильтров
В предыдущих примерах единственным ограничением для совпадающих терминов было то, что они являются частью указанного поля. При желании можно сделать автодополнение более строгим.
Например, здесь мы получаем совпадения, начинающиеся с 'americ', такие как 'American Hustle', но также и 'Captain America: Civil War':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title americ* ') ORDER BY WEIGHT() D SC, cast_total_facebook_likes DESC;
+------+---------------------------------------------------+
| id | movie_title |
+------+---------------------------------------------------+
| 277 | American Hustle |
| 701 | Captain America: Civil War |
| 703 | Captain America: The Winter Soldier |
| 282 | American Psycho |
| 2612 | Once Upon a Time in America |
| 272 | American Gangster |
| 702 | Captain America: The First Avenger |
| 269 | American Beauty |
| 478 | Beavis and Butt-Head Do America |
| 284 | American Sniper |
| 4036 | The Legend of Hell's Gate: An American Conspiracy |
| 273 | American Graffiti |
| 285 | American Splendor |
| 274 | American Heist |
| 287 | America's Sweethearts |
| 283 | American Reunion |
| 280 | American Pie |
| 281 | American Pie 2 |
| 271 | American Dreamz |
| 286 | American Wedding |
+------+---------------------------------------------------+
20 rows in set (0.00 sec)
Мы можем использовать оператор start field, чтобы показывать только записи, начинающиеся с введённого термина:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title ^americ* ') ORDER BY WEIGHT() ESC, cast_total_facebook_likes DESC;
+------+-------------------------------------+
| id | movie_title |
+------+-------------------------------------+
| 277 | American Hustle |
| 282 | American Psycho |
| 272 | American Gangster |
| 269 | American Beauty |
| 284 | American Sniper |
| 273 | American Graffiti |
| 285 | American Splendor |
| 274 | American Heist |
| 287 | America's Sweethearts |
| 283 | American Reunion |
| 280 | American Pie |
| 281 | American Pie 2 |
| 271 | American Dreamz |
| 286 | American Wedding |
| 276 | American History X |
| 268 | America Is Still the Place |
| 279 | American Outlaws |
| 275 | American Hero |
| 278 | American Ninja 2: The Confrontation |
| 270 | American Desi |
+------+-------------------------------------+
20 rows in set (0.00 sec)
Ещё один момент, который следует учитывать — дублирование. Это актуальнее в случаях, когда мы хотим выполнять автодополнение по полю, не имеющему уникальных значений. В качестве примера попробуем автодополнение по имени актёра:
MySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ');
+--------------------+
| actor_1_name |
+--------------------+
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| Don Johnson |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| R. Brandon Johnson |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
+--------------------+
20 rows in set (0.09 sec)
Мы видим много дубликатов. Это можно решить простым группированием по этому полю — при условии, что оно определено как string attribute:
MySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name; [AMySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name;
+------------------------+
| actor_1_name |
+------------------------+
| Johnny Depp |
| Dwayne Johnson |
| Don Johnson |
| R. Brandon Johnson |
| Johnny Pacar |
| Kenny Johnston |
| Johnny Cannizzaro |
| Nicole Randall Johnson |
| Johnny Lewis |
| Richard Johnson |
| Bill Johnson |
| Eric Johnson |
| John Belushi |
| John Cothran |
| John Ratzenberger |
| John Cameron Mitchell |
| John Saxon |
| John Gatins |
| John Boyega |
| John Michael Higgins |
+------------------------+
20 rows in set (0.10 sec)
Выделение
Запрос автодополнения может возвращать результаты с включённым выделением. Хотя это можно реализовать и на стороне приложения, выделение, выполненное Manticore Search, более мощное, поскольку оно следует запросу поиска (те же настройки токенизации, AND, OR и NOT в запросе и т.д. ). Возьмём предыдущий пример, всё, что нам нужно, — использовать функцию 'SNIPPET':
MySQL [(none)]> SELECT SNIPPET(actor_1_name,' john*') FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+--------------------------------+
| snippet(actor_1_name,' john*') |
+--------------------------------+
| <b>Johnny</b> Depp |
| Dwayne <b>Johnson</b> |
| <b>Johnny</b> Pacar |
| Don <b>Johnson</b> |
| <b>Johnny</b> Cannizzaro |
| <b>Johnny</b> Lewis |
| Eric <b>Johnson</b> |
| Nicole Randall <b>Johnson</b> |
| Kenny <b>Johnston</b> |
| R. Brandon <b>Johnson</b> |
| Bill <b>Johnson</b> |
| Richard <b>Johnson</b> |
| <b>John</b> Ratzenberger |
| <b>John</b> Belushi |
| <b>John</b> Cameron Mitchell |
| <b>John</b> Cothran |
| Olivia Newton-<b>John</b> |
| <b>John</b> Michael Higgins |
| <b>John</b> Witherspoon |
| <b>John</b> Amos |
+--------------------------------+
20 rows in set (0.00 sec)
Больше информации о выделении можно найти в этом курсе .
Кроме использования инфиксов и префиксов, есть и другие способы сделать автозаполнение в Manticore: используя CALL KEYWORDS , с включенным или выключенным bigram_index , используя CALL QSUGGEST / CALL SUGGEST . Но способ, показанный в этой статье, кажется самым простым для начала. Если вы хотите поиграть с Manticore Search, попробуйте наш docker image , который имеет однострочную команду для запуска Manticore на любом сервере всего за несколько секунд.