Всем привет!
2025‑й был очень практичным годом для Manticore Search. Много моментов «окей, почему это медленно в продакшене», много исправлений без блеска и постоянное стремление заставить движок делать больше, не превращая ваш стек в научный проект.
«Большие штуки», которые мы выпустили
- Векторный поиск: варианты индексации, фильтрация, гибридные настройки — то, что понимаешь только после того, как построишь систему ( читать )
- Автоэмбеддинги: вставляйте текст, получайте векторы, делайте запросы с
knn()… без добавления отдельного конвейера эмбеддингов ( читать ) - Квантование векторов (и связанные улучшения): более дешёвое хранение, более быстрые запросы, больше настроек, когда они нужны ( читать )
- Нечёткий поиск: реальный поиск товаров, который не ломается из‑за опечаток ( читать )
- Автодополнение: просто включить, и достаточно хорошее для выпуска ( читать )
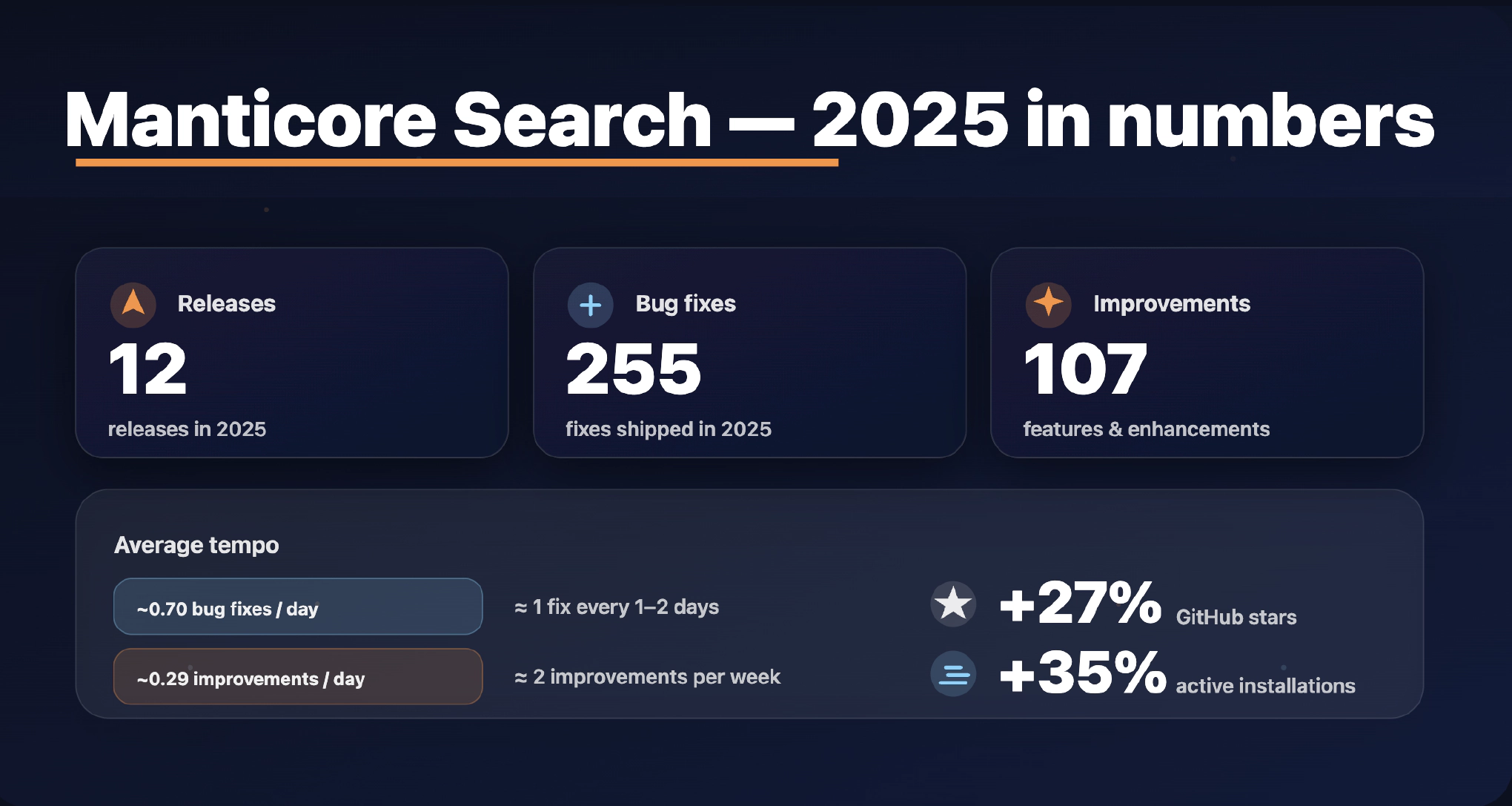
Итоги в цифрах
- 📦 выпущено 12 релизов
- 🐞 исправлено 255 багов
- ✨ доставлено 107 функций и улучшений
- ⭐ звёзд на GitHub стало на 27% больше по сравнению с прошлым годом
- 📈 активных инстансов стало примерно на 35% больше по сравнению с прошлым годом
Если вам нравятся статистики темпа (нам тоже — немного):
- ~1 исправление бага каждые 1,4 дня
- ~1 функция/улучшение каждые 3,4 дня
- в среднем — примерно одно значимое изменение в день
То, что действительно имело значение (для нас и, надеемся, для вас):
Производительность
- Вторичные индексы для JSON, чтобы быстрее фильтровать JSON‑насыщенные документы (плюс
secondary_index_block_cache, если вы на них реально опираетесь) - Пакетирование JOIN‑ов для заметного ускорения JOIN‑запросов
- Квантование векторов (и друзья: рескоринг/оверсэмплинг, изменения хранения) для более дешёвого и быстрого векторного поиска
- Автоматический сброс RT‑дисковых чанков на диск — плюс лучшее логирование и наблюдаемость — чтобы производительность не проседала незаметно под нагрузкой
Удобство использования
- Автоматическая генерация эмбеддингов (одна из тех «наконец» функций)
- Скролл‑пагинация для больших наборов результатов без странных ухищрений
- Нечёткий поиск и автодополнение , которые можно просто включить
- Китайская токенизация на базе Jieba (потому что без правильного сегментирования вы получаете «почему это не совпало» и «почему это совпало вот с этим»)
- Встроенный
экспортёр Prometheus
(и
/metrics, который отдаёт настоящий Prometheus‑текст, а не JSON) - Поддержка JOIN в JSON‑HTTP API
Качество поиска и язык запросов
- Явный
|(OR) внутри PHRASE / PROXIMITY / QUORUM , чтобы продвинутые запросы перестали ощущаться как обходной путь - boolean_simplify включён по умолчанию (более чистые булевые запросы без необходимости думать об этом)
- Запросы HAVING стали лучше: можно получить общие подсчёты без лишних ухищрений
Безопасность данных
- Поддержка
LOCK TABLESдля более безопасных логических бэкапов через mysqldump - Улучшения репликации: периодическое сохранение seqno, проверка уникального
server_idпри подключении к кластеру, индикатор прогресса SST
Интеграции
- Интеграция Kibana для дашбордов «что происходит» (и реальная история производительности в демо Kibana: читать )
- Загрузка данных из Kafka для потоковой передачи данных в Manticore
- Поддержка DBeaver для GUI‑ориентированных рабочих процессов
Прочие детали
- Статистика использования по таблицам и счётчики
JOIN ONс произвольными выражениями фильтра- JOIN‑ы для локальных распределённых таблиц
Больше материалов, которые мы опубликовали в 2025 году (чтобы вы могли углубиться, если захотите):
- Manticore Load Emulator — инструмент, который мы создали для бенчмаркинга/тюнинга без расплывчатых результатов
- Manticore Search Re-indexing with mysqldump — перестроение индексов / бэкапы / «как безопасно переместить данные без паники из‑за простоя»
- About Versioning in Manticore — что означают наши версии и чего ожидать при обновлении
- Manticore Search vs Elasticsearch: 3x Faster Kibana Dashboard Rendering for Log Analysis — дашборды Kibana + анализ журналов, и почему скорость рендеринга может быть… очень разной
- Understanding Pagination in Manticore Search — скролл‑пагинация, глубокая пагинация, чего не стоит делать, когда у вас миллион результатов
- Integrating Kafka with Manticore Search: A Step-by-Step Guide to Real-Time Data Processing — загрузка данных из Kafka в Manticore, шаг за шагом
- OR Inside Phrase, Quorum and Proximity — узконаправленно, но действительно полезно, когда вы попадаете в область «расширенных запросов»
❤️ Спасибо всем, кто поставил звёздочку репозиторию, сообщал об ошибках (особенно раздражающих), делился отзывами и использует Manticore Search в продакшене. Если вы прислали нам воспроизводимый пример, который сэкономил день догадок, — вы лучшие.
— Команда Manticore Search