
Современные поисковые системы уже не просто сопоставляют ключевые слова. Когда вы ищете «уютный детектив, действие которого происходит в Париже», а получаете результаты вроде «атмосферный детективный роман во Франции», это векторный поиск в действии: документы и запросы превращаются в списки чисел — эмбеддинги, — а поисковый движок находит документы, чьи векторы ближе всего к вектору запроса.
Manticore Search поддерживает это из коробки. Внутри используется структура данных HNSW: граф, который соединяет близкие векторы и позволяет быстро находить ближайших соседей без сканирования каждого документа. Благодаря этому векторный поиск по миллионам документов выполняется за миллисекунды.
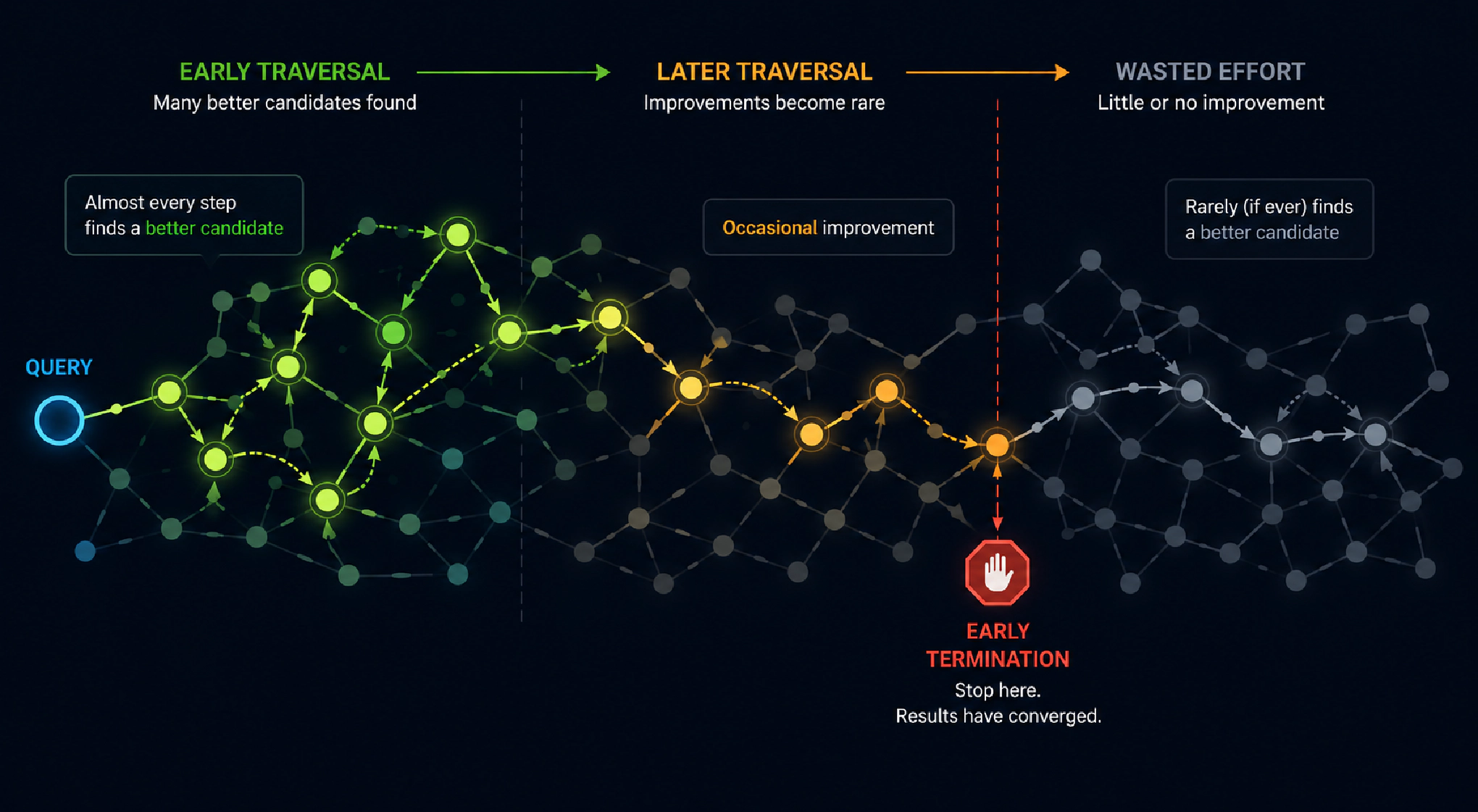
Но у HNSW есть источник лишней работы. В начале обхода почти каждое вычисление расстояния находит кандидата лучше тех, что уже есть в наборе результатов.
По мере поиска такие улучшения встречаются всё реже, но алгоритм продолжает обходить узлы графа, пока не исчерпает лимит обхода. К этому моменту результаты часто уже достаточно качественные, а оставшаяся работа почти ничего не улучшает. Раннее завершение позволяет определить момент сходимости и досрочно прекратить поиск.
Эффект становится заметнее по мере роста k, где k — число ближайших соседей, которое Manticore должен вернуть по запросу. Чтобы вернуть больше соседей, нужно глубже исследовать граф, и значительная часть этой дополнительной работы происходит уже после достижения приемлемого качества результатов. Поэтому раннее завершение становится полезнее: появляется больше избыточных вычислений, которые можно исключить.
С векторным квантованием
это выражено ещё сильнее. Квантование сжимает хранимые векторы и экономит память, но слегка снижает точность поиска. Чтобы вернуть часть точности, Manticore использует оверсэмплинг
: получает в 3 раза больше кандидатов, чем запрошено, а затем выполняет повторную оценку по исходным векторам полной точности. При стандартном 3-кратном оверсэмплинге HNSW исследует гораздо больше кандидатов на запрос. Большие значения k часто появляются именно из-за такого расширения кандидатов: приложение может запросить у векторного индекса сотни или тысячи кандидатов, а затем переоценить, повторно ранжировать или отфильтровать результаты до гораздо меньшего итогового набора, чтобы повысить recall и precision. Это увеличивает время ответа, а раннее завершение помогает вернуть часть этого времени.
Эффект экономии вычислений наглядно демонстрируют бенчмарки на датасете из 1 млн векторов: при k=60, то есть стандартном лимите результатов при дефолтном 3-кратном оверсэмплинге, раннее завершение сокращает число вычислений расстояний примерно до 65% от полного поиска. При k=1000 число вычислений падает до 30%, а при k=10000 — до 20%. Поиск сходится задолго до того, как заканчивается лимит обхода, и эффективность раннего завершения возрастает с увеличением k.
Раннее завершение даёт Manticore возможность выявить момент, когда результаты стабилизировались, и остановиться. Алгоритм разрабатывался с конкретной целью по точности: потерять не больше 2–4% точности набора результатов по сравнению с полным поиском HNSW.
Как это устроено
Алгоритм отслеживает простой сигнал: долю успешных обнаружений (англ. discovery rate), то есть долю вычислений расстояний, которые действительно улучшают набор результатов.
Каждый раз, когда вычисляется расстояние до новой ноды, происходит одно из двух: либо кандидат достаточно хорош, чтобы попасть в приоритетную очередь с текущими лучшими кандидатами, либо он хуже любого кандидата, который уже там, и отбрасывается. Включение в набор лучших кандидатов считается «обнаружением». В начале поиска успешных обнаружений много: куча заполняется, и большинство кандидатов полезны. По мере продвижения поиска в куче уже достаточно хороших результатов, а успешные обнаружения становятся редкими. Большинство новых вычислений расстояний не приводят к улучшению набора результатов.
Manticore фиксирует данный переход. После каждого раунда расширения списка соседних узлов алгоритм вычисляет показатель успешности обнаружений — то есть долю вычислений расстояний, которые приводят к обновлению набора лучших кандидатов:
discovery_rate = new_candidates_collected / distances_computed
Если эта доля остаётся ниже порога несколько раундов подряд, поиск останавливается.
Идея простая: если алгоритм продолжает вычислять расстояния, но результат уже не улучшается, значит поиск сошёлся.
Порог: адаптация по квантилям
Отсюда возникает очевидный вопрос: какой порог считать «низким»? Фиксированный порог здесь плохо работает: у разных датасетов и даже у разных областей одного датасета распределения этого показателя сильно отличаются. Что считать «низким», зависит от контекста.
Manticore использует адаптивный порог на основе квантилей. Вместо того чтобы сравнивать долю успешных обнаружений с фиксированным числом, он постоянно оценивает нижний процентиль недавних раундов (20-й процентиль, или 14-й процентиль для L2-расстояния) и использует его как ориентир. Так метод остаётся вычислительно дешёвым, но может адаптироваться к разным датасетам и разным областям графа.
Другими словами, порог подстраивается под локальный характер поиска. Если алгоритм попадает в разреженную область графа, порог снижается и помогает не остановиться слишком рано. Если он попадает в более плотную область, порог повышается.
Счётчик допустимых неудачных раундов: когда остановиться
Но одного порога недостаточно. Один раунд с низкой долей успешных обнаружений ещё не означает, что поиск сошёлся. Это может быть временное снижение эффективности перед нахождением более оптимального пути. Поэтому Manticore использует счётчик допустимых неудачных раундов (англ. patience): для завершения нужно несколько неудачных раундов подряд.
Значение счётчика допустимых неудачных раундов уменьшается по мере роста ef — фактора исследования HNSW, который управляет тем, сколько кандидатов остаётся в работе. Например, счётчик допустимых неудачных раундов меняется от 9 при низких значениях ef до 6 при очень высоких ef. Большие значения ef означают больше раундов в целом, поэтому даже при меньшем значении счётчика у алгоритма уже больше данных до того, как решить остановиться. Счётчик сбрасывается в ноль каждый раз, когда в раунде достаточная доля успешных обнаружений, так что один хороший раунд перезапускает окно счётчика. Это не даёт алгоритму остановиться в период отсутствия улучшений, за которым может быть продуктивная область графа.
Фаза разогрева
Алгоритм игнорирует сигнал завершения, пока набор лучших кандидатов ещё заполняется, то есть пока собрано меньше ef кандидатов. На этой фазе доля успешных обнаружений искусственно высокая, потому что почти все кандидаты включаются в набор лучших, поэтому сигнал бесполезен. Раннее завершение начинает работать только после заполнения этого набора, когда новые кандидаты уже конкурируют с уже найденными.
Результаты бенчмарков
Пороговые значения квантилей подбирались так, чтобы потеря точности оставалась в пределах 2–4%. Их настраивали отдельно для метрик L2 и cosine/IP и проверяли на обоих типах данных — квантованных и неквантованных векторных данных .
Следующие бенчмарки выполнены на датасете dbpedia-entities (1 млн векторов, 768 измерений) на машине с 8 физическими ядрами / 16 логическими ядрами.
- "Precision" здесь означает долю точных k ближайших соседей, которые попали в результирующий набор (при фиксированном k это то же самое, что recall@k).
- "Precision ratio" — точность HNSW с ранним завершением ("ET"), делённая на точность без него (1.0 означает, что потери точности нет).
- "Visit ratio" — доля вычислений расстояний по сравнению с полным поиском HNSW (меньше — лучше).
Оверсэмплинг и переоценку здесь отключили, чтобы изолировать влияние раннего завершения на чистый обход структуры HNSW.

Зелёная линия на графике (precision) остаётся почти ровной для всех значений k: precision ratio держится выше 0.97 на протяжении всего бенчмарка. Оранжевая линия (visit ratio), наоборот, резко падает. При k=100 раннее завершение сокращает вычисления расстояний почти вдвое. При k=1000 экономия по числу вычислений расстояний достигает 70%. При k=10000 — 80%.
При k <= 10 раннее завершение отключено: поиск и так "дешёвый", а экономия слишком мала, чтобы оправдать любую потерю точности. Эффективность раннего завершения возрастает с увеличением k, потому что более крупные наборы результатов приводят к большему числу раундов расширения соседей и дают больше возможностей обнаружить сходимость раньше.
Производительность при параллельной нагрузке
Бенчмарки выше показывают, что раннее завершение заметно сокращает вычисления расстояний и сохраняет точность. Но что это значит для времени ответа в реальных запросах, особенно при параллельной нагрузке? На графике ниже показано отношение времени ответа (ET / без ET) при 1, 8 и 16 одновременных потоках на том же датасете dbpedia:

При k=1000 раннее завершение уменьшает число вычислений расстояний на 71% (коэффициент 0.29). Улучшение времени ответа зависит от того, сколько потоков работает одновременно:
- 1 поток: ускорение выполнения на 24% (коэффициент 0.76)
- 8 потоков: ускорение выполнения на 45% (коэффициент 0.55)
- 16 потоков: ускорение выполнения на 48% (коэффициент 0.52)
Экономия на вычислениях расстояний остаётся одинаковой независимо от числа потоков, но выигрыш по времени ответа почти удваивается при переходе от 1 к 16 потокам.
Основная причина — меньшая нагрузка на подсистему памяти процессора. Каждое вычисление расстояния загружает в кэш данные вектора и ссылки графа. Когда несколько потоков одновременно выполняют обход структуры HNSW, они конкурируют за общий кэш и пропускную способность памяти. Меньшее число вычислений расстояний на запрос снижает число обращений к памяти, уменьшает рабочий набор каждого потока и реже вытесняет данные из кэша между запросами. В результате каждый поток завершает работу быстрее и меньше мешает остальным.
Результаты однопоточных тестов не полностью отражают преимущества раннего завершения. При нагрузке, близкой к продакшну, процентное снижение времени ответа примерно вдвое больше.
Когда включается раннее завершение (и когда нет)
Раннее завершение включено по умолчанию и работает как с квантованными, так и с неквантованными векторными данными. Оно автоматически отключается при k <= 10.
Выгода растёт вместе с эффективным лимитом вычислений, равным max(ef, k). Поскольку hnswlib использует его внутри как число кандидатов, оставляемых в работе, больший k означает больше кандидатов, больше раундов и больше возможностей обнаружить сходимость.
Квантованные векторные данные обычно используют вместе с переоценкой и оверсэмплингом (оба включены по умолчанию), чтобы восстановить точность, потерянную при квантизации. Оверсэмплинг (по умолчанию 3×) умножает эффективный k, передаваемый в HNSW. Например, для запроса с k=100 при оверсэмплинге 3× в HNSW используется 300 кандидатов. Такой больший лимит вычислений даёт раннему завершению больше возможностей обнаружить сходимость и остановиться раньше. Поскольку выигрыш от раннего завершения растёт вместе с k, оверсэмплинг переводит запросы в диапазон, где экономия максимальна.
Синтаксис
Раннее завершение включено по умолчанию. Чтобы его отключить:
SQL:
-- default: early termination enabled
SELECT id, knn_dist()
FROM products
WHERE knn(embedding, (0.12, 0.45, 0.78, 0.33));
-- explicitly disable early termination
SELECT id, knn_dist()
FROM products
WHERE knn(embedding, (0.12, 0.45, 0.78, 0.33), { early_termination=0 });
-- combine with other KNN options
SELECT id, knn_dist()
FROM products
WHERE knn(embedding, (0.12, 0.45, 0.78, 0.33), { ef=200, early_termination=0 });
JSON:
POST /search
{
"table": "products",
"knn": {
"field": "embedding",
"query": [0.12, 0.45, 0.78, 0.33],
"early_termination": false
}
}
Когда отключать
Есть несколько сценариев, где раннее завершение лучше отключить:
- Критична максимальная точность. Раннее завершение допускает небольшую потерю полноты результатов ради повышения скорости. Если приложению нужна максимально возможная полнота, которую HNSW может дать при заданном
ef, отключите его. - Небольшие значения k (<= 30). Алгоритм автоматически отключается при
k <= 10, но даже дляkот 11 до 30 прирост производительности невелик. Если вы замечаете разницу в полноте в этом диапазоне, отключение раннего завершения почти не увеличит время ответа. - Бенчмаркинг полноты HNSW. Если вы измеряете recall HNSW, вам, скорее всего, нужно детерминированное поведение без применения адаптивных механизмов остановки. В этом случае рекомендуется отключить раннее завершение, чтобы получить чистую базу для сравнения.
Как это связано с другими оптимизациями KNN
Раннее завершение — одна из нескольких оптимизаций, которые Manticore применяет к поиску KNN. Она работает независимо от остальных и сочетается с ними:
- Prefiltering сокращает лишнюю работу, пропуская документы, не прошедшие фильтр, во время обхода структуры HNSW. Раннее завершение тоже сокращает лишнюю работу: останавливает обход структуры графа, как только результаты стабилизировались. Это разные задачи, и эти оптимизации хорошо работают вместе.
- Oversampling
запрашивает больше кандидатов, чем
k, чтобы улучшить recall после переоценки. Раннее завершение может снизить стоимость такого расширенного поиска, останавливаясь после того, как найдено достаточно хороших кандидатов. - Rescoring повторно вычисляет расстояния по векторам полной точности после начального поиска с квантованными векторными данными. Раннее завершение работает на этапе начального квантованного поиска и уменьшает число кандидатов, оцениваемых до переоценки.
- Автоматический переход к полному перебору полностью пропускает HNSW, когда линейное сканирование дешевле. Раннее завершение применяется только тогда, когда действительно используется HNSW.