
FOSDEM सम्मेलन 3 फरवरी 2024 को Manticore वेक्टर खोज पर पीटर ज़ैतसेव द्वारा प्रस्तुतिकरण का आयोजन किया गया, जो Manticore के सह-संस्थापक हैं और सर्गे निकोलेव , Manticore के CEO हैं। इस कार्यक्रम ने डेटाबेस में वेक्टर खोज के बारे में नवीनतम जानकारी प्रस्तुत की। निकटता से देखने के लिए, ज़ैतसेव की वार्ता की रिकॉर्डिंग ऊपर उपलब्ध है। नीचे, आप इस विषय का अधिक विस्तृत सारांश एक लेख के रूप में देख सकते हैं।
परिचय
पिछले दो से तीन वर्षों में, डेटाबेस परिदृश्य में कई प्रमुख परिवर्तन देखे गए हैं:
- ‘वेक्टर डेटाबेस’ की एक नई श्रेणी उभरी है, जिसमें 2019 में मिल्वस, 2020 में वेस्पा, 2021 में वीवेइट और 2022 में क्यूड्रंट जैसे ओपन-सोर्स प्लेटफार्म शामिल हैं, साथ ही 2019 में पेश की गई क्लाउड समाधान जैसे पाइनकोन। ये डेटाबेस वेक्टर खोज के लिए समर्पित हैं, विभिन्न मशीन लर्निंग मॉडल के उपयोग पर ध्यान केंद्रित करते हैं। हालाँकि, इनमें पारंपरिक डेटाबेस सुविधाएँ जैसे लेनदेन, विश्लेषण, डेटा प्रतिकृति आदि की कमी हो सकती है।
- Elasticsearch ने 2019 में वेक्टर खोज क्षमताएँ जोड़ी।
- फिर 2022 से 2023 के बीच, Redis, OpenSearch, Cassandra, ClickHouse, Oracle, MongoDB और Manticore Search जैसे स्थापित डेटाबेस, Azure, Amazon AWS और Cloudflare की क्लाउड सेवाओं के साथ, वेक्टर खोज कार्यक्षमता की पेशकश करने लगे।
- अन्य प्रसिद्ध डेटाबेस, जैसे MariaDB, वेक्टर खोज क्षमताओं को एकीकृत करने की प्रक्रिया में हैं।
- PostgreSQL उपयोगकर्ताओं के लिए, ‘pgvector’ एक्सटेंशन है जो 2021 से इस कार्यक्षमता को लागू करता है।
- जबकि MySQL ने मूल वेक्टर खोज कार्यक्षमता के लिए योजनाएँ घोषित नहीं की हैं, PlanetScale और AlibabaCloud जैसे प्रदाताओं से स्वामित्व वाले एक्सटेंशन उपलब्ध हैं।

वेक्टर स्पेस और वेक्टर समानता
चलो चर्चा करते हैं कि इतने सारे डेटाबेस ने हाल ही में वेक्टर खोज कार्यक्षमता को सक्षम क्यों बनाया और यह वास्तव में क्या है।
आइए एक ठोस उदाहरण से शुरू करें। दो रंगों पर विचार करें: लाल, जिसका RGB कोड (255, 0, 0) है, और नारंगी, जिसका RGB कोड (255, 200, 152) है। इन्हें तुलना करने के लिए, चलिए इन्हें एक त्रिविमीय ग्राफ पर चित्रित करते हैं, जहाँ हर बिंदु एक अलग रंग का प्रतिनिधित्व करता है, और धुरी लाल, हरा और नीला रंग के घटकों के अनुरूप है। फिर हम ग्राफ के उत्पत्ति से हमारे रंगों का प्रतिनिधित्व करने वाले बिंदुओं तक वेक्टर खींचते हैं। अब हमारे पास दो वेक्टर हैं: एक लाल का और दूसरा - नारंगी का।
यदि हम इन दोनों रंगों के बीच समानता खोजने के लिए चाहते हैं, तो एक दृष्टिकोण यह हो सकता है कि बस वेक्टरों के बीच कोण को मापा जाए। यह कोण 0 से 90 डिग्री तक भिन्न हो सकता है, या यदि हम इसे कोसाइन लेकर सामान्यीकृत करते हैं, तो यह 0 से 1 तक भिन्न होगा। हालाँकि, यह विधि वेक्टरों की मात्रा पर विचार नहीं करती है, जिसका अर्थ है कि कोसाइन विभिन्न रंगों A, A1, A2 के लिए समान मान देगा, भले ही वे विभिन्न शेड्स का प्रतिनिधित्व करते हों।
इस मुद्दे को हल करने के लिए, हम कोसाइन समानता सूत्र का उपयोग कर सकते हैं, जो वेक्टर की लंबाई को ध्यान में रखकर उनकी डॉट उत्पाद को उनके मात्रा के उत्पाद से विभाजित करता है।

यह अवधारणा वेक्टर खोज का सार है। यह रंगों के साथ दृश्य रूप से स्पष्ट है, लेकिन अब कल्पना करें कि, तीन रंग धुरी के बजाय, हमारे पास सैकड़ों या हजारों आयामों के साथ एक स्थान है, जहाँ प्रत्येक धुरी एक ऑब्जेक्ट के विशिष्ट गुण का प्रतिनिधित्व करती है। जबकि हम इसे किसी स्लाइड पर चित्रित करना या पूरी तरह से दृश्य बनाना आसान नहीं है, गणितीय रूप से यह संभव है, और सिद्धांत वही रहता है: आपके पास एक बहु-आयामी स्थान में वेक्टर हैं और आप उनके बीच समानता की गणना करते हैं।
वेक्टर समानता खोजने के लिए कुछ अन्य सूत्र भी हैं: जैसे डॉट उत्पाद समानता और युक्लिडियन दूरी, लेकिन जैसे कि OpenAI API डॉक्स कहता है, उनके बीच का अंतर सामान्यतः अधिक मायने नहीं रखता।
Screenshot: https://platform.openai.com/docs/guides/embeddings/which-distance-function-should-i-use
वेक्टर विशेषताएँ: Sparse वेक्टर
तो, एक ऑब्जेक्ट में विभिन्न विशेषताएँ हो सकती हैं। लाल, हरा, और नीला घटक वाला रंग सबसे सरल उदाहरण है। वास्तविक जीवन में यह आमतौर पर अधिक जटिल होता है।
पाठ खोज में, उदाहरण के लिए, हम दस्तावेजों को उच्च-आयामी वेक्टर के रूप में प्रस्तुत कर सकते हैं। इससे हमें “बैग ऑफ वर्ड्स” के सिद्धांत पर पहुँचने का मौका मिलता है। यह मॉडल पाठ को वेक्टर में परिवर्तित करता है जहाँ प्रत्येक आयाम एक अनूठे शब्द के अनुरूप है, और मान शब्द की उपस्थिति का एक द्विआधारी संकेतक, घटनाओं की गणना, या शब्द के वजन के रूप में हो सकता है जो उसकी आवृत्ति और उल्टे दस्तावेज़ आवृत्ति (जिसे TF-IDF कहा जाता है) पर आधारित होता है, जो दर्शाता है कि किसी शब्द का एक संग्रह में दस्तावेज़ के लिए कितना महत्वपूर्ण है। यह तथाकथित स्पार्स वेक्टर है क्योंकि अधिकांश मान शून्य होते हैं क्योंकि अधिकांश दस्तावेज़ों में बहुत से शब्द नहीं होते।
पुस्तकालयों और खोज इंजनों जैसे Lucene , Elasticsearch , और Manticore Search में पूर्ण-पाठ खोज के बारे में बात करते समय, स्पार्स वेक्टर खोज को तेज बनाने में मदद करते हैं। मूलतः, आप ऐसा विशेष प्रकार का अनुक्रमण बना सकते हैं जो खोज शब्द के बिना दस्तावेजों को अनदेखा करता है। इसलिए, आपको हर बार अपनी खोज के खिलाफ हर एक दस्तावेज़ की जाँच करने की आवश्यकता नहीं होती। स्पार्स वेक्टर भी आसानी से समझने योग्य होते हैं, वे, एक अर्थ में, रिवर्स-इंजीनियर्ड किए जा सकते हैं। प्रत्येक आयाम एक विशिष्ट स्पष्ट विशेषता का प्रतिनिधित्व करता है, इसलिए हम अपने वेक्टर प्रतिनिधित्व से मूल पाठ में पीछे की ओर जा सकते हैं। यह अवधारणा पहले से ही लगभग 50 वर्षों के लिए अस्तित्व में है।

वेक्टर विशेषताएँ: Dense वेक्टर
पारंपरिक पाठ खोज विधियाँ जैसे TF-IDF , जो दशकों से मौजूद हैं, शब्द आवृत्ति पर निर्भर स्पार्स शब्द वेक्टर उत्पन्न करती हैं। मुख्य समस्या? वे आमतौर पर शब्दों के उपयोग के संदर्भ को नजरअंदाज करती हैं। उदाहरण के लिए, “सेब” शब्द फल और प्रौद्योगिकी कंपनी दोनों से जुड़ा हो सकता है बिना किसी भेद के, जिससे खोज में उन्हें समान रैंक मिल सकता है।
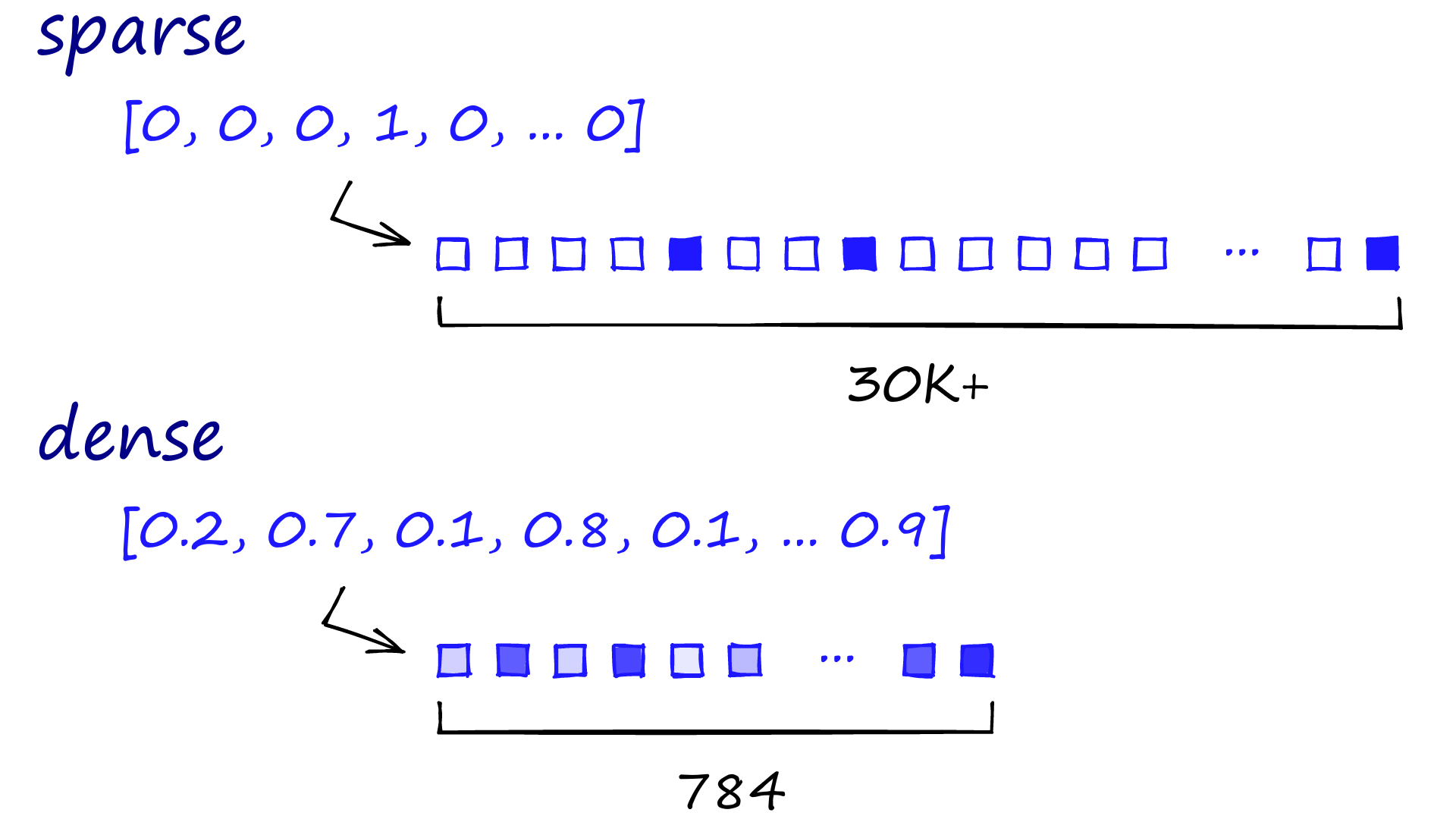
लेकिन इस उदाहरण पर विचार करें: एक वेक्टर स्पेस में, किन दो वस्तुओं की निकटता अधिक होगी: एक बिल्ली और एक कुत्ता, या एक बिल्ली और एक कार? पारंपरिक विधियाँ जो स्पार्स वेक्टर उत्पन्न करती हैं — जैसा कि नीचे दी गई छवि के शीर्ष भाग में दिखाया गया है - एक सार्थक उत्तर देने में संघर्ष कर सकती हैं। स्पार्स वेक्टर अक्सर उच्च-आयामी होते हैं, जिनमें अधिकांश मान शून्य होते हैं, जो किसी दिए गए दस्तावेज या संदर्भ में अधिकांश शब्दों की अनुपस्थिति का प्रतिनिधित्व करते हैं।
फिर गहन शिक्षण की क्रांति आई, संदर्भात्मक एम्बेडिंग्स को प्रस्तुत करते हुए। ये घने वेक्टर प्रतिनिधित्व हैं, जैसा कि छवि के निचले भाग में चित्रित किया गया है। स्पार्स वेक्टर के विपरीत, जिनमें दसियों हजार आयाम हो सकते हैं, घने वेक्टर कम-आयामी होते हैं (जैसे छवि में 784 आयाम) लेकिन सूक्ष्म सांझिक संबंधों को पकड़ने वाले निरंतर मानों से भरे होते हैं। इसका मतलब है कि एक ही शब्द का अलग-अलग संदर्भों में अलग-अलग वेक्टर प्रतिनिधित्व हो सकता है, और विभिन्न शब्द समान वेक्टर हो सकते हैं यदि वे समान संदर्भ साझा करते हैं। BERT और GPT जैसी तकनीकें इन घने वेक्टरों का उपयोग जटिल भाषा विशेषताओं को पकड़ने के लिए करती हैं, जिनमें सांझिक संबंध, समानार्थक और विपरीतार्थक शब्दों में भेद, और व्यंग्य तथा स्लैंग को समझना शामिल है — जो पहले की विधियों के लिए काफी चुनौतीपूर्ण कार्य थे।
इसके अलावा, गहन शिक्षण पाठ से परे जाता है, जिससे छवियों, ऑडियो और वीडियो जैसे जटिल डेटा को संसाधित किया जा सकता है। इन्हें वर्गीकरण, पहचान और निर्माण जैसे कार्यों के लिए घने वेक्टर प्रतिनिधित्व में परिवर्तित किया जा सकता है। गहन शिक्षण का उदय डेटा की उपलब्धता और संगणना क्षमता में विस्फोट के साथ हुआ, जिससे जटिल मॉडल को प्रशिक्षित किया जा सका जो डेटा में गहरे और सूक्ष्म पैटर्न को उजागर करते हैं।

एम्बेडिंग्स
ऐसे मॉडल द्वारा प्रदान किए गए वेक्टर को “एम्बेडिंग्स” कहा जाता है। यह समझना महत्वपूर्ण है कि पहले दिखाए गए स्पार्स वेक्टर के विपरीत, जहाँ प्रत्येक तत्व एक स्पष्ट विशेषता जैसे दस्तावेज में मौजूद एक शब्द का प्रतिनिधित्व कर सकता है, एक एम्बेडिंग के प्रत्येक तत्व भी एक विशिष्ट विशेषता का प्रतिनिधित्व करता है, लेकिन अधिकांश मामलों में हमें यह भी नहीं पता कि वह विशेषता क्या है।
उदाहरण के लिए,
जे अलमर ने एक दिलचस्प प्रयोग किया
और GloVe मॉडल का उपयोग करके विकिपीडिया को वेक्टराइज़ किया और फिर कुछ शब्दों के मानों को विभिन्न रंगों के साथ दृश्यात्मक बनाया। यहाँ हम देख सकते हैं कि:
- विभिन्न शब्दों में एक स्थिर लाल रेखा दिखाई देती है, जो एक आयाम पर समानता का संकेत देती है, हालांकि विशिष्ट विशेषता जो इसका प्रतिनिधित्व करती है, अज्ञात रहती है।
- “महिला” और “लड़की” या “पुरुष” और “लड़का” जैसे शब्द कई आयामों में समानताएं प्रदर्शित करते हैं, जो उनकी संबंधितता का संकेत देता है।
- दिलचस्प बात यह है कि “लड़का” और “लड़की” की समानताएं “महिला” और “पुरुष” से अलग हैं, जो किशोरावस्था के एक अंतर्निहित विषय का संकेत देता है।
- “पानी” शब्द से संबंधित एक उदाहरण को छोड़कर, सभी विश्लेषित शब्द लोगों से संबंधित हैं, “पानी” अवधारणात्मक श्रेणियों के बीच अंतर करने के लिए काम करता है।
- अन्य शब्दों से अलग “राजा” और “रानी” के बीच विशिष्ट समानताएं शाही को एक अमूर्त प्रतिनिधित्व का संकेत दे सकती हैं।

छवि:
https://jalammar.github.io/illustrated-word2vec/
इसलिए गहन शिक्षण द्वारा उत्पन्न घने वेक्टर एम्बेडिंग्स, एक संक्षिप्त रूप में विशाल मात्रा में जानकारी को संधारित करते हैं। स्पार्स वेक्टर के विपरीत, एक घने एम्बेडिंग के हर आयाम में आमतौर पर शून्य से अलग मान होता है और कुछ सांझिक महत्व वहन करता है। यह समृद्धता एक लागत के साथ आती है - घने एम्बेडिंग्स के साथ, चूँकि हर आयाम मानों से घना होता है, हम सरलता से उन दस्तावेजों को छोड़ नहीं सकते जिनमें कोई विशिष्ट शब्द नहीं है। इसके बजाय, हमें क्वेरी वेक्टर को डेटासेट में हर दस्तावेज वेक्टर के साथ तुलना करने की संगणनात्मक तीव्रता का सामना करना पड़ता है। यह एक ब्रूट-फोर्स दृष्टिकोण है जो स्वाभाविक रूप से संसाधन-गहन है।
हालाँकि, घने वेक्टरों के लिए विशेष सूचकांक विकसित किए गए हैं। ये सूचकांक, जैसे KD-वृक्ष, बॉल वृक्ष, या अधिक आधुनिक दृष्टिकोण जैसे HNSW (पदानुक्रमित नेविगेशन योग्य छोटा विश्व) ग्राफ, काफी चतुर हैं, लेकिन वे तेज होने के लिए कभी-कभी अनुमान लगाते हैं। यह अनुमान का अर्थ है कि वे हमेशा 100% सही उत्तर नहीं देते। डेटाबेस द्वारा अपनाया जाने वाला सबसे लोकप्रिय सूचकांक HNSW है जो Hierarchical Navigable Small World का संक्षिप्त रूप है। इसका उपयोग pgvector एक्सटेंशन फॉर पोस्टग्रेस, Lucene , Opensearch , Redis , SOLR , Cassandra , Manticore Search और Elasticsearch द्वारा किया जाता है। इसका एल्गोरिदम एक बहु-परतीय ग्राफ संरचना बनाता है। प्रत्येक परत एक ग्राफ है जहाँ प्रत्येक नोड (एक डेटा बिंदु का प्रतिनिधित्व करता है) अपने सबसे निकटतम पड़ोसियों से जुड़ा होता है। निचली परत में सभी नोड्स (डेटा बिंदु) होते हैं, और प्रत्येक उच्च परत में नीचे की परत से नोड्स का एक उप-समूह होता है। शीर्ष परत में सबसे कम नोड होते हैं। खोज ऊपरी परतों से शुरू होती है और धीरे-धीरे निचली परतों की ओर बढ़ती है। यह पदानुक्रमित दृष्टिकोण खोज प्रक्रिया को कुशल बनाता है। संक्षेप में HNSW जैसा कि कोई अन्य सूचकांक, पहले से कुछ शॉर्टकट बनाता है जिनका आप बाद में तेज क्वेरी प्रसंस्करण के लिए उपयोग कर सकते हैं। अन्य वेक्टर सूचकांक भी हैं, जैसे Annoy जो Spotify द्वारा रखा जाता है और अन्य, जिनमें से प्रत्येक के पास प्रदर्शन, संसाधन उपभोग और सटीकता हानि के संदर्भ में अपने फायदे और नुकसान हैं।

{kind=link}
{kind=link}
K-nearest neighbours
वेक्टर खोज वास्तव में एक छत्र शब्द है जिसमें विभिन्न कार्य शामिल हैं जैसे कि क्लस्टरिंग और वर्गीकरण और अन्य। लेकिन आमतौर पर, एक डेटाबेस जो वेक्टर खोज के लिए जोड़ता है वह ‘के-निकटतम पड़ोसी खोज’ (KNN) है, या इसका करीबी रिश्तेदार, ‘लगभग निकटतम पड़ोसी खोज’ (ANN)। यह आकर्षक है क्योंकि यह डेटाबेस को दिए गए दस्तावेज़ के वेक्टर के सबसे समान दस्तावेज़ों को खोजने की अनुमति देता है, जो डेटाबेस को एक सशक्त खोज इंजन की क्षमताओं के साथ बढ़ाता है, जिसकी पहले कमी थी।
पारंपरिक खोज इंजन जैसे लुसिन, एलास्टिकसर्च, SOLR, और मैन्टिकोरे सर्च विभिन्न प्राकृतिक भाषा प्रोसेसिंग कार्यों को संभालते हैं - जैसे कि रूपविज्ञान, समानार्थक, स्टॉपवर्ड्स, और अपवाद - सभी एक दिए गए प्रश्न के लिए मेल खाते दस्तावेजों को खोजने के लक्ष्य के साथ। KNN एक समान लक्ष्य प्राप्त करता है लेकिन विभिन्न तरीकों से - बस तालिका में उन दस्तावेज़ों से जुड़े वेक्टरों की तुलना करना जो आमतौर पर एक बाहरी मशीन लर्निंग मॉडल द्वारा प्रदान किए जाते हैं।
चलो देखते हैं कि डेटाबेस में एक सामान्य वेक्टर खोज कैसी दिखती है,
मैन्टिकोर सर्च
को उदाहरण के रूप में लेते हुए।
पहले, हम एक तालिका बनाते हैं जिसमें एक कॉलम है जिसका शीर्षक image_vector है:
create table test ( title text, image_vector float_vector knn_type='hnsw' knn_dims='4' hnsw_similarity='l2' );
यह वेक्टर
फ्लोट प्रकार
का है, जो महत्वपूर्ण है क्योंकि ऐसे डेटाबेस जो इस डेटा प्रकार का समर्थन नहीं करते हैं, उन्हें पहले इसे जोड़ना होगा, क्योंकि घने वेक्टर आमतौर पर फ्लोट ऐरे में संग्रहीत होते हैं। इस समय, आप आमतौर पर क्षेत्र को वेक्टर आयाम आकार, वेक्टर निर्देशांक प्रकार, और इसकी विशेषताओं को निर्दिष्ट करके कॉन्फ़िगर करते हैं। उदाहरण के लिए, हम यह निर्दिष्ट करते हैं कि हम HNSW निर्देशांक का उपयोग करना चाहते हैं, वेक्टर का आयाम 5 होगा, और समानता फ़ंक्शन l2 होगा, जो युक्लिडियन दूरी है।
फिर, हम तालिका में कुछ रिकॉर्ड डालते हैं:
insert into test values ( 1, 'yellow bag', (0.653448,0.192478,0.017971,0.339821) ), ( 2, 'white bag', (-0.148894,0.748278,0.091892,-0.095406) );
प्रत्येक रिकॉर्ड में एक शीर्षक और एक संबंधित वेक्टर होता है, जो एक वास्तविक दुनिया के परिदृश्य में एक गहरी सीखने वाले मॉडल से आउटपुट हो सकता है जो कुछ उच्च-आयामी डेटा जैसे कि एक छवि या ध्वनि, पाठ से एक एम्बेडिंग, या ओपनएआई एपीआई से कुछ और को एन्कोड करता है। यह ऑपरेशन डेटा को डेटाबेस में संग्रहीत करता है और समन्वय या परिवर्तन करने के लिए अनुक्रमणिका को पुन: निर्माण करने के लिए ट्रिगर कर सकता है।
अगला, हम KNN फ़ंक्शन का उपयोग करके वेक्टर खोज करते हैं :
select id, knn_dist() from test where knn ( image_vector, 5, (0.286569,-0.031816,0.066684,0.032926) );
+------+------------+
| id | knn_dist() |
+------+------------+
| 1 | 0.28146550 |
| 2 | 0.81527930 |
+------+------------+
2 rows in set (0.00 sec)
यहाँ हम डेटाबेस को उस वेक्टर को खोजने के लिए प्रश्न कर रहे हैं जो हमारे निर्दिष्ट इनपुट वेक्टर के निकटतम हैं। पैरेंथेसिस में दिए गए संख्याएँ वह विशेष वेक्टर निर्धारित करती हैं जिसके लिए हम निकटतम पड़ोसियों की खोज कर रहे हैं। यह चरण किसी भी डेटाबेस के लिए महत्वपूर्ण है जो वेक्टर खोज क्षमताओं को लागू करने का लक्ष्य रखता है। इस चरण में डेटाबेस या तो विशिष्ट अनुक्रमणक विधियों जैसे कि HNSW, का उपयोग कर सकता है, या तालिका में प्रत्येक वेक्टर के खिलाफ क्वेरी वेक्टर की तुलना करके निकटतम मेल्स खोजने के लिए ब्रूट-फोर्स खोज कर सकता है।
वापस किए गए परिणाम हमारे इनपुट वेक्टर के निकटतम वेक्टरों के शीर्षकों और उनके प्रश्न से संबंधित दूरी को दिखाते हैं। कम दूरी मान खोज प्रश्न के लिए निकटतम मेल का संकेत करते हैं।

Embedding computation
अधिकतर डेटाबेस और खोज इंजनों ने अभी तक बाहरी एम्बेडिंग पर निर्भर किया है। इसका मतलब है कि जब आप एक दस्तावेज़ डालते हैं, तो आपको पहले उसके एम्बेडिंग को एक बाहरी स्रोत से प्राप्त करना होगा और इसे दस्तावेज़ के अन्य क्षेत्रों के साथ शामिल करना होगा। समान दस्तावेज़ों की खोज करते समय भी यही लागू होता है: यदि खोज एक उपयोगकर्ता प्रश्न के लिए है न कि एक मौजूदा दस्तावेज़ के लिए, तो आपको इसके लिए एक मशीन लर्निंग मॉडल का उपयोग करना होगा ताकि इसके लिए एक एम्बेडिंग की गणना की जा सके, जिसे फिर डेटाबेस को पास किया जाएगा। यह प्रक्रिया संगतता मुद्दों, अतिरिक्त डेटा प्रोसेसिंग परतों के प्रबंधन की आवश्यकता, और खोज प्रदर्शन में संभावित असक्षमताओं का कारण बन सकती है। इस दृष्टिकोण की संचालनात्मक जटिलता भी आवश्यक से अधिक है। डेटाबेस के साथ, आपको एम्बेडिंग बनाने के लिए एक और सेवा चलानी पड़ सकती है।
कुछ खोज इंजन जैसे ओपनसर्च, एलास्टिकसर्च, और टाइपसेन्स अब स्वचालित रूप से एम्बेडिंग बनाने से चीजों को आसान बना रहे हैं। वे इसके लिए अन्य कंपनियों के उपकरणों का भी उपयोग कर सकते हैं, जैसे ओपनएआई। मुझे लगता है कि हम इसे जल्द ही अधिक देखेंगे। अधिक डेटाबेस अपने आप एम्बेडिंग बनाना शुरू करेंगे, जो वास्तव में हमारी डेटा खोजने और विश्लेषण करने के तरीके को बदल सकता है। यह परिवर्तन इस अर्थ में है कि डेटाबेस केवल डेटा संग्रहित नहीं करेंगे; वे वास्तव में इसे समझेंगे। मशीन लर्निंग और एआई का उपयोग करके, ये डेटाबेस अधिक स्मार्ट होंगे, भविष्यवाणी करने और अनुकूलित करने में सक्षम होंगे, और डेटा को अधिक उन्नत तरीकों से संभाल सकेंगे।
Hybrid search approaches
कुछ खोज इंजन एक विधि का पालन कर रहे हैं जिसे हाइब्रिड खोज कहा जाता है, जो पारंपरिक कीवर्ड-आधारित खोज को उन्नत न्यूरल नेटवर्क तकनीकों के साथ जोड़ती है। हाइब्रिड खोज मॉडल उन परिस्थितियों में उत्कृष्टता प्राप्त करते हैं जो दोनों सटीक कीवर्ड मिलान की मांग करती हैं, जैसा कि पारंपरिक खोज तकनीकों द्वारा प्रदान किया जाता है, और विस्तृत संदर्भ पहचान प्रदान करते हैं, जैसा कि वेक्टर खोज क्षमताओं द्वारा प्रस्तुत किया जाता है। यह संतुलित दृष्टिकोण खोज परिणामों की सटीकता को बढ़ा सकता है। उदाहरण के लिए, वेस्पा ने अपनी हाइब्रिड खोज की सटीकता को क्लासिकल BM25 रैंकिंग और ColBERT मॉडल की तुलना करके मापा। उनके दृष्टिकोण में, उन्होंने पहले विधानसभा के रैंकिंग मॉडल के रूप में क्लासिकल BM25 का उपयोग किया और BM25 मॉडल के अनुसार शीर्ष-स्थान K दस्तावेज़ों के लिए केवल हाइब्रिड स्कोर की गणना की। यह पाया गया कि हाइब्रिड खोज मोड अधिकांश परीक्षणों में इनमें से प्रत्येक से बेहतर प्रदर्शन करता है।
एक और सरल विधि है रेसिप्रोकल रैंक फ्यूजन (RRF), एक तकनीक जो विभिन्न खोज एल्गोरिदम से रैंकिंग को मिलाती है। RRF प्रत्येक आइटम के लिए एक स्कोर की गणना करता है जो उसकी स्थिति के आधार पर होती है, जहाँ उच्च रैंकिंग वाले आइटम बेहतर स्कोर प्राप्त करते हैं। स्कोर का निर्धारण 1 / (rank + k) के सूत्र द्वारा किया जाता है, जहाँ ‘rank’ सूची में आइटम की स्थिति है, और ‘k’ एक स्थिरांक है जिसका उपयोग निम्न रैंकिंग के प्रभाव को समायोजित करने के लिए किया जाता है। प्रत्येक स्रोत से इन संशोधित विपरीत रैंक का योग करने से, RRF विभिन्न प्रणालियों के बीच सहमति पर जोर देता है। यह विधि विभिन्न एल्गोरिदम की ताकतों को मिलाती है, जिसके परिणामस्वरूप अधिक मजबूत और व्यापक खोज परिणाम मिलते हैं।

तालिका:
https://blog.vespa.ai/improving-zero-shot-ranking-with-vespa-part-two/
सूत्र:
https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf
निष्कर्ष
वेक्टर खोज केवल एक अवधारणा या खोज इंजनों की एक विशिष्ट कार्यक्षमता नहीं है; यह डेटा पुनः प्राप्त करने के तरीके को बदलने वाला एक व्यावहारिक उपकरण है। हाल के वर्षों में, डेटाबेस क्षेत्र में बड़े बदलाव आए हैं, नए वेक्टर-केंद्रित डेटाबेस के उदय के साथ और स्थापित डेटाबेस में वेक्टर खोज सुविधाएँ जोड़ी जा रही हैं। यह अधिक उन्नत खोज कार्यों की एक मजबूत आवश्यकता को दर्शाता है, जिस आवश्यकता को वेक्टर खोज पूरा कर सकता है। उन्नत अनुक्रमण विधियाँ, जैसे HNSW, ने वेक्टर खोज को तेज़ बना दिया है।
आगे देखते हुए, हम अपेक्षा करते हैं कि डेटाबेस सिर्फ वेक्टर खोज का समर्थन करने से अधिक करेंगे; वे स्वयं एम्बेडिंग बनाने की संभावना रखते हैं। इससे डेटाबेस का उपयोग करना सरल और अधिक शक्तिशाली हो जाएगा, जो उन्हें मूल भंडारण स्थानों से स्मार्ट सिस्टम में बदल देगा जो डेटा को समझने और विश्लेषण करने में सक्षम हैं। संक्षेप में, वेक्टर खोज डेटा प्रबंधन और पुनर्प्राप्ति में एक महत्वपूर्ण बदलाव है, जो इस क्षेत्र में एक रोमांचक विकास को चिह्नित करता है।