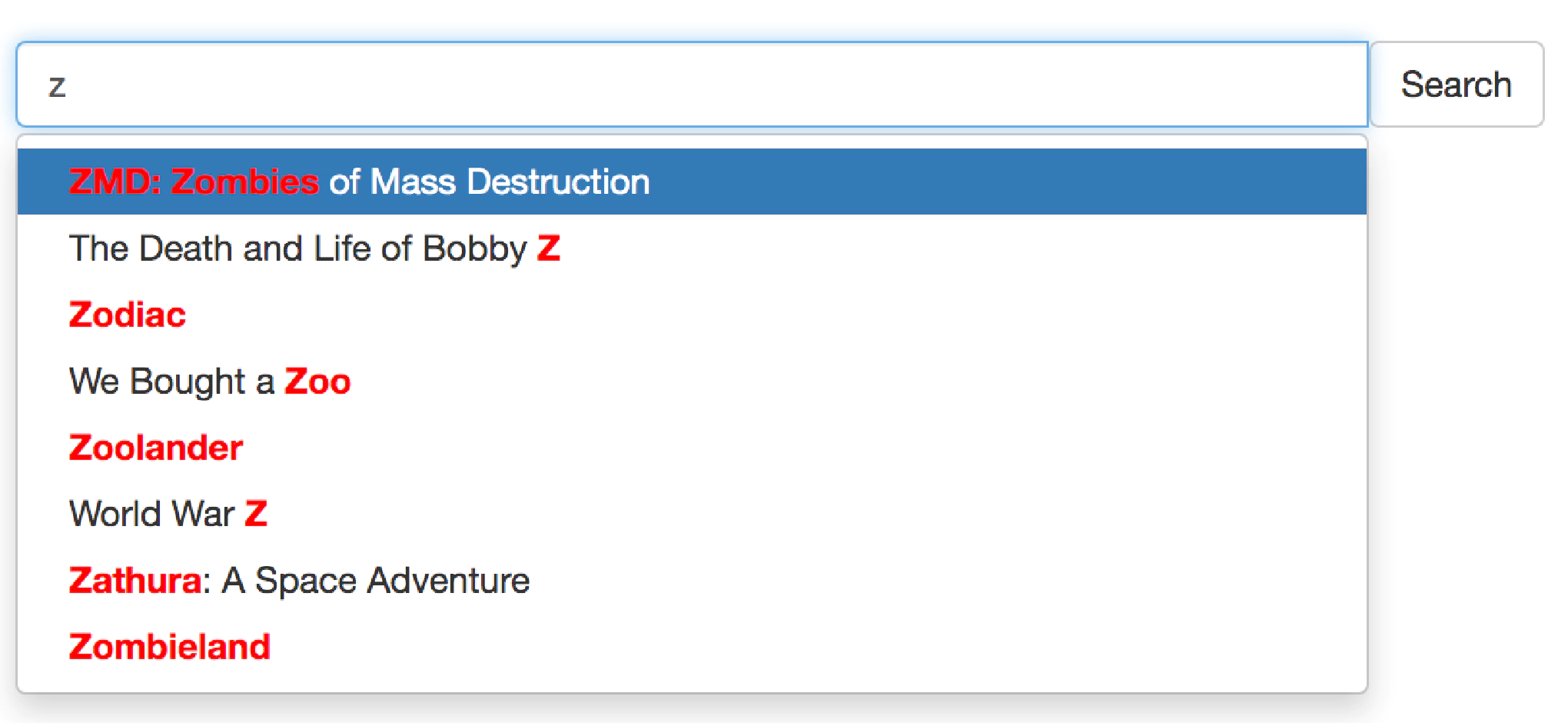
यह लेख Manticore Search में शब्द पूर्णता करने के तरीकों में से एक का वर्णन करता है।
ऑटो-कम्पलीट क्या है?
ऑटो-कम्पलीट (या शब्द पूर्णता) एक फीचर है जो एक एप्लिकेशन को उपयोगकर्ता द्वारा टाइप करते समय शब्द के शेष भाग की भविष्यवाणी करने की अनुमति देता है। यह सामान्यत: इस प्रकार काम करता है: उपयोगकर्ता खोज बार में एक शब्द टाइप करना शुरू करता है, और सुझावों के साथ एक ड्रॉपडाउन पॉपअप होता है ताकि उपयोगकर्ता सूची में से एक का चयन कर सके।
सुझावों का स्रोत विभिन्न हो सकते हैं। यह सबसे अच्छा है अगर प्रदर्शित शब्द या वाक्य मौजूदा डेटा संग्रह में उपलब्ध हो, ताकि उपयोगकर्ता कुछ ऐसा न चुने जो खाली परिणाम लौटाए। लेकिन कुछ मामलों में ऑटो-कम्पलीट पिछले (सफल) खोजों पर आधारित होता है जो सिद्धांत में शून्य परिणाम पा सकता है, लेकिन फिर भी समझ में आ सकता है। यह सब आपकी एप्लिकेशन की विशेषताओं पर निर्भर करता है।
सरलतम ऑटो-कम्पलीट डेटा सेट में वस्तुओं के शीर्षकों से सुझाव खोजकर बनाया जा सकता है। यह एक लेख/समाचार का शीर्षक, एक उत्पाद का नाम या जैसा कि हम जल्द ही दिखाएंगे, एक फ़िल्म का नाम हो सकता है। ऐसा करने के लिए हमें स्ट्रिंग एट्रीब्यूट या स्टोर्ड फील्ड के रूप में फ़ील्ड को परिभाषित करने की आवश्यकता है। बस मूल डेटा में अतिरिक्त लुकअप करने से बचने के लिए।
चूंकि उपयोगकर्ता को अधूरा शब्द प्रदान करने की उम्मीद होती है, हमें वाइल्डकार्ड खोज करने की आवश्यकता है। वाइल्डकार्ड खोजें अनुक्रमणिका में प्रीफिक्सिंग या इंफिक्सिंग को सक्रिय करके संभव हैं। क्योंकि यह प्रतिक्रिया समय को प्रभावित कर सकता है आपको यह तय करना है कि आप चाहते हैं कि इसे उन अनुक्रमणिका में सक्षम किया जाए जो खोजों के लिए उपयोग किया जाता है या केवल इसे ऑटो-कम्पलीट कार्यक्षमता के लिए समर्पित विशेष अनुक्रमणिका में सक्षम करें। ऐसा करने का एक और कारण यह है कि अंतिम को संभवतः जितना संभव हो उतना कॉम्पैक्ट बनाया जाए ताकि न्यूनतम विलंबता प्रदान की जा सके क्योंकि यह विशेष रूप से ऑटो-कम्पलीट के लिए UX के दृष्टिकोण से महत्वपूर्ण है। आमतौर पर हम दाईं ओर एक वाइल्डकार्ड एस्टेरिक्स जोड़ते हैं, क्योंकि हम मानते हैं कि उपयोगकर्ता एक शब्द शुरू कर रहा है, हालाँकि व्यापक परिणामों के लिए, हम दोनों पक्षों पर एस्टेरिक्स जोड़ते हैं ताकि उन शब्दों को प्राप्त किया जा सके जिनका एक प्रीफिक्स भी हो सकता है। इस पाठ्यक्रम में फिल्मों के डेटा सेट के लिए आइए इंफिक्सिंग का चयन करें, क्योंकि यह शब्द सुधार के लिए SUGGEST फीचर को भी सक्षम करता है (देखें कि यह इस पाठ्यक्रम में कैसे काम करता है )। हमारा अनुक्रमणिका घोषणा होगी:
index movies {
type = plain
path = /var/lib/manticore/data/movies
source = movies
min_infix_len = 3
}
चूंकि हम फिल्म के शीर्षक से ऑटो-कम्पलीट प्रदान करने जा रहे हैं, हमारी क्वेरी ‘movie_title’ फ़ील्ड में सीमित होगी।
फिल्म शीर्षक पर ऑटो-कम्पलीट
आपके एप्लिकेशन का फ्रंटेंड खोज बॉक्स में टाइप किए गए पहले अक्षर से सुझाव के लिए क्वेरी करना शुरू कर सकता है। हालाँकि, यदि अनुक्रमणिका विशाल हो तो यह सिस्टम पर अधिक दबाव डाल सकता है क्योंकि यह सर्वर पर अधिक अनुरोध करेगा और 1-2 कैरैक्टर के वाइल्डकार्ड खोज भी धीमी हो सकते हैं। चलिए मान लेते हैं कि उपयोगकर्ता ‘sha’ टाइप करता है।
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title sha*');
+------+---------------------------------------+
| id | movie_title |
+------+---------------------------------------+
| 118 | A Low Down Dirty Shame |
| 394 | Austin Powers: The Spy Who Shagged Me |
| 604 | Book of Shadows: Blair Witch 2 |
| 951 | Dark Shadows |
| 1318 | Fifty Shades of Black |
| 1319 | Fifty Shades of Grey |
| 1389 | Forty Shades of Blue |
| 1853 | In the Shadow of the Moon |
| 1928 | Jack Ryan: Shadow Recruit |
| 3114 | Shade |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 3117 | Shadowlands |
| 3118 | Shaft |
| 3119 | Shakespeare in Love |
| 3120 | Shalako |
| 3121 | Shall We Dance |
| 3122 | Shallow Hal |
| 3123 | Shame |
| 3124 | Shanghai Calling |
+------+---------------------------------------+
20 rows in set (0.00 sec)
हम मुख्य रूप से केवल फिल्म शीर्षक के बारे में परवाह करते हैं, इसलिए हम सभी कॉलम नहीं लौटाते हैं। जैसे कि हम देख सकते हैं, बहुत सारे परिणाम लौटाए गए हैं। हम उदाहरण के लिए फेसबुक लाइक्स द्वारा द्वितीयक क्रम को जोड़कर क्वेरी को ट्वीक करने का प्रयास कर सकते हैं, लेकिन यह अभी भी यह अनुमान लगाने के लिए बहुत जल्दी होगा कि उपयोगकर्ता क्या देख रहा है:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title sha*') ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3131 | Shark Tale |
| 394 | Austin Powers: The Spy Who Shagged Me |
| 3118 | Shaft |
| 4326 | The Shaggy Dog |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3134 | Shattered |
| 3123 | Shame |
| 3525 | The Adventures of Sharkboy and Lavagirl 3-D |
| 3117 | Shadowlands |
| 3129 | Shark Lake |
| 4328 | The Shawshank Redemption |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 3135 | Shattered Glass |
| 3130 | Shark Night 3D |
| 1319 | ग्रे की पचास शेड्स |
| 4619 | ट्रिस्टैम शैंडी: एक कॉक और बुल कहानी |
| 118 | एक नीच गंदा शर्म |
| 3132 | शार्कनाडो |
| 1318 | काले की पचास शेड्स |
+------+--------------------------------------------------+
20 rows in सेट (0.00 सेकंड)
मान लें कि उपयोगकर्ता एक और अक्षर टाइप करता है:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title शाफ*') ORDER BY WEIGHT() DES , cast_total_facebook_likes DESC;
+------+-------------+
| id | movie_title |
+------+-------------+
| 3118 | शाफ |
+------+-------------+
1 row in सेट (0.00 सेकंड)
अब हमारे पास एकल परिणाम है।
एक और उदाहरण लें जहां हम ‘शैड*’ टाइप करते हैं।
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title शैड*') ORDER BY WEIGHT() DES , cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | डार्क शैडोज |
| 3142 | शर्लक होम्स: ए गेम ऑफ शैडोज |
| 3117 | शैडोलैंड्स |
| 3494 | टीनएज म्यूटेंट निंजा कछुए: शैडोज से बाहर |
| 1319 | ग्रे की पचास शेड्स |
| 1318 | काले की पचास शेड्स |
| 4325 | द शेडो |
| 3115 | शैडो साजिश |
| 3116 | वैंपायर की छाया |
| 1928 | जैक रयान: शैडो रिक्रूट |
| 1389 | नीले के चौकस शेड्स |
| 604 | शैडोज की किताब: ब्लेयर विच 2 |
| 3114 | शेड |
| 1853 | चाँद की छाया में |
| 4353 | ध्वनि और छाया |
+------+--------------------------------------------------+
15 rows in सेट (0.00 सेकंड)
फिर शैडो*:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title शैडो*') ORDER BY WEIGHT() DE C, cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | डार्क शैडोज |
| 3142 | शर्लक होम्स: ए गेम ऑफ शैडोज |
| 3117 | शैडोलैंड्स |
| 3494 | टीनएज म्यूटेंट निंजा कछुए: शैडोज से बाहर |
| 4325 | द शेडो |
| 3115 | शैडो साजिश |
| 3116 | वैंपायर की छाया |
| 1928 | जैक रयान: शैडो रिक्रूट |
| 604 | शैडोज की किताब: ब्लेयर विच 2 |
| 1853 | चाँद की छाया में |
| 4353 | ध्वनि और छाया |
+------+--------------------------------------------------+
11 rows in सेट (0.00 सेकंड)
और ‘शैडो’:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title शैडो') ORDER BY WEIGHT() DE C, cast_total_facebook_likes DESC;
+------+---------------------------+
| id | movie_title |
+------+---------------------------+
| 4325 | द शेडो |
| 3115 | शैडो साजिश |
| 3116 | वैंपायर की छाया |
| 1928 | जैक रयान: शैडो रिक्रूट |
| 1853 | चाँद की छाया में |
| 4353 | ध्वनि और छाया |
+------+---------------------------+
6 rows in सेट (0.00 सेकंड)
मान लें कि उपयोगकर्ता ‘शैडो’ को पहले शब्द के रूप में देख रहा था, वह दूसरे शब्द को टाइप करना जारी रखेगा, जैसे ‘शैडो सी’:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title शैडो सी*') ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+------+-------------------+
| id | movie_title |
+------+-------------------+
| 3115 | शैडो साजिश |
+------+-------------------+
1 row in सेट (0.01 सेकंड)
इस मामले में, हमें एकल परिणाम मिलता है जो उपयोगकर्ता को संतुष्ट करना चाहिए, लेकिन अन्य मामलों में हम अधिक प्राप्त कर सकते हैं और उपयोगकर्ता पहले शब्द की तरह अक्षरों को टाइप करना जारी रखेगा और मैन्टिकोरे इनपुट के आधार पर अधिक सुझाव लौटाएगा:

अधिक फ़िल्टर जोड़ना
पिछले उदाहरणों में, मेल खाने वाले शर्तों के लिए एकमात्र प्रतिबंध निर्दिष्ट क्षेत्र का एक भाग होना था। यदि हम चाहें तो हमारे पास एक अधिक प्रतिबंधात्मक ऑटो-पूर्ण हो सकता है।
उदाहरण के लिए, यहां हम ‘अमेरिक’ से शुरू होने वाले मिलान प्राप्त करते हैं, जैसे ‘अमेरिकन हसल’, लेकिन ‘कैप्टन अमेरिका: सिविल युद्ध’ भी:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title अमेरिक* ') ORDER BY WEIGHT() D SC, cast_total_facebook_likes DESC;
+------+---------------------------------------------------+
| id | movie_title |
+------+---------------------------------------------------+
| 277 | अमेरिकन हसल |
| 701 | कैप्टन अमेरिका: सिविल युद्ध |
| 703 | कैप्टन अमेरिका: द विंटर सोल्जर |
| 282 | अमेरिकन सायको |
| 2612 | अमेरिका में एक बार |
| 272 | अमेरिकन गैंगस्टर |
| 702 | कैप्टन अमेरिका: द फ़र्स्ट एवेंजर |
| 269 | अमेरिकन ब्यूटी |
| 478 | बीविस और बट-हेड अमेरिका करें |
| 284 | अमेरिकन स्नाइपर |
| 4036 | द लेजेंड ऑफ हेल्स गेट: एन अमेरिकन साजिश |
| 273 | अमेरिकी ग्रैफिटी |
| 285 | अमेरिकन स्प्लेंडर |
| 274 | अमेरिकन हीस्ट |
| 287 | अमेरिका के मीठे बच्चे |
| 283 | अमेरिकन रियूनियन |
| 280 | अमेरिकन पाई |
| 281 | अमेरिकन पाई 2 |
| 271 | अमेरिकन ड्रीम्ज़ |
| 286 | अमेरिकन वेडिंग |
+------+---------------------------------------------------+
20 पंक्तियाँ मिलीं (0.00 सेकंड में)
हम स्टार्ट फील्ड ऑपरेटर का उपयोग कर सकते हैं ताकि केवल इनपुट शब्द से शुरू होने वाले रिकॉर्ड दिखाए जा सकें:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title ^americ* ') ORDER BY WEIGHT() ESC, cast_total_facebook_likes DESC;
+------+-------------------------------------+
| id | movie_title |
+------+-------------------------------------+
| 277 | अमेरिकन हसल |
| 282 | अमेरिकन साइको |
| 272 | अमेरिकन गैंगस्टर |
| 269 | अमेरिकन ब्यूटी |
| 284 | अमेरिकन स्नाइपर |
| 273 | अमेरिकन ग्रैफिटी |
| 285 | अमेरिकन स्पेलेंडर |
| 274 | अमेरिकन हेइस्ट |
| 287 | अमेरिका के मीठे बच्चे |
| 283 | अमेरिकन रियूनियन |
| 280 | अमेरिकन पाई |
| 281 | अमेरिकन पाई 2 |
| 271 | अमेरिकन ड्रीम्ज़ |
| 286 | अमेरिकन वेडिंग |
| 276 | अमेरिकन हिस्ट्री X |
| 268 | अमेरिका अभी भी एक जगह है |
| 279 | अमेरिकन आउटलॉज़ |
| 275 | अमेरिकन हीरो |
| 278 | अमेरिकन निंजा 2: द कन्फ्रंटेशन |
| 270 | अमेरिकन डेसी |
+------+-------------------------------------+
20 पंक्तियाँ मिलीं (0.00 सेकंड में)
एक और चीज़ जिस पर हमें ध्यान देना चाहिए वह है डुप्लीकेट्स। यह तब अधिक लागू होता है जब हम किसी ऐसे फील्ड पर ऑटोकंप्लीट करना चाहते हैं जिसमें अद्वितीय मान नहीं हैं। उदाहरण के लिए, आइए अभिनेता के नाम से ऑटोकंप्लीट करने का प्रयास करें:
MySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ');
+--------------------+
| actor_1_name |
+--------------------+
| जॉनी डेप्प |
| जॉनी डेप्प |
| जॉनी डेप्प |
| ड्वेन जॉनसन |
| जॉनी डेप्प |
| जॉनी डेप्प |
| डॉन जॉनसन |
| ड्वेन जॉनसन |
| जॉनी डेप्प |
| जॉनी डेप्प |
| जॉनी डेप्प |
| जॉनी डेप्प |
| जॉनी डेप्प |
| ड्वेन जॉनसन |
| जॉनी डेप्प |
| जॉनी डेप्प |
| आर. ब्रैंडन जॉनसन |
| ड्वेन जॉनसन |
| जॉनी डेप्प |
| जॉनी डेप्प |
+--------------------+
20 पंक्तियाँ मिलीं (0.09 सेकंड में)
हम बहुत सारे डुप्लीकेट्स देख सकते हैं। इसे उस फील्ड पर समूहीकरण करके हल किया जा सकता है - यह मानते हुए कि हमारे पास यह एक स्ट्रिंग विशेषता के रूप में है:
MySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name;
+------------------------+
| actor_1_name |
+------------------------+
| जॉनी डेप्प |
| ड्वेन जॉनसन |
| डॉन जॉनसन |
| आर. ब्रैंडन जॉनसन |
| जॉनी पकार |
| केनी जॉन्स्टन |
| जॉनी कैनिज़ारो |
| निकोल रैंडल जॉनसन |
| जॉनी लुईस |
| रिचर्ड जॉनसन |
| बिल जॉनसन |
| एरिक जॉनसन |
| जॉन बेलुशी |
| जॉन कॉथ्रन |
| जॉन रैत्जेनबर्गर |
| जॉन कैमरन मिचेल |
| जॉन सैक्सन |
| जॉन गेटिंस |
| जॉन बॉयेगा |
| जॉन माइकल हिगिंस |
+------------------------+
20 पंक्तियाँ मिलीं (0.10 सेकंड में)
हाइलाइटिंग
ऑटोकंप्लीट क्वेरी हाइलाइटिंग के साथ परिणाम वापस कर सकती है। हालांकि इसे एप्लिकेशन की तरफ से भी किया जा सकता है, लेकिन मैंटिकोर सर्च द्वारा की गई हाइलाइटिंग अधिक शक्तिशाली होती है क्योंकि यह खोज क्वेरी का पालन करेगी (टोकनाइजेशन सेटिंग्स, क्वेरी में ANDs, ORs और NOTs आदि)। पिछले उदाहरण को लेते हुए, हमें बस ‘SNIPPET’ फ़ंक्शन का उपयोग करना होगा:
MySQL [(none)]> SELECT SNIPPET(actor_1_name,' john*') FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+--------------------------------+
| snippet(actor_1_name,' john*') |
+--------------------------------+
| <b>जॉनी</b> डेप्प |
| ड्वेन <b>जॉनसन</b> |
| <b>जॉनी</b> पकार |
| डॉन <b>जॉनसन</b> |
| <b>जॉनी</b> कैनिज़ारो |
| <b>जॉनी</b> लुईस |
| एरिक <b>जॉनसन</b> |
| निकोल रैंडल <b>जॉनसन</b> |
| केनी <b>जॉन्स्टन</b> |
| आर. ब्रैंडन <b>जॉनसन</b> |
| बिल <b>जॉनसन</b> |
| रिचर्ड <b>जॉनसन</b> |
| <b>जॉन</b> रैत्जेनबर्गर |
| <b>जॉन</b> बेलुशी |
| <b>जॉन</b> कैमरन मिचेल |
| <b>जॉन</b> कॉथ्रन |
| ओलिविया न्यूटन-<b>जॉन</b> |
| <b>जॉन</b> माइकल हिगिंस |
| <b>जॉन</b> विदरस्पून |
| <b>जॉन</b> एमोस |
+------------------------+
20 पंक्तियाँ मिलीं (0.00 सेकंड में)
आप हाइलाइटिंग के बारे में अधिक जानकारी इस पाठ्यक्रम में पा सकते हैं।
Besides using the infixes and prefixes there are other ways to do Autocomplete in Manticore: using CALL KEYWORDS , with or without bigram_index turned on, using CALL QSUGGEST / CALL SUGGEST . But the way it’s shown in this article seems to be the easiest to get started with. If you want to play with Manticore Search try out our docker image which has a one-liner to run Manticore on any server in just few seconds.