
Table of Contents
- Vector Search in Manticore: The Details
- What Are Embeddings (And Why Should You Care)?
- How Does Vector Search Work?
- Getting Started: Setting Up Vector Search
- Advanced Search Features
- Real-World Applications
- Making Vector Search Fast: Performance Tips
- Keeping Your Vector Data Safe: Backup Options
- Keeping Your Search System Available: Replication
- See Vector Search in Action: Live Demos
- Running Vector Search in Production
- Conclusion: The Future of Vector Search
1. Vector Search in Manticore: The Details
If you've been following our blog, you already know that Manticore Search offers powerful vector search capabilities. In this post, we're going beyond the basics to show how it all works behind the scenes — and how you can make the most of it.
Before we get into the technical bits, a quick announcement: on June 6 2025, the Manticore team is sponsoring Vector Search Conference 2025

We'll be giving two talks focused on real-world vector search:
- Speed Meets Precision: How Vector Quantization Supercharges Search — Sergey Nikolaev
- RAG Time: Smarter Answers with Retrieval-Augmented Generation — Dmitrii Kuzmenkov
If you're working with semantic search, recommendations, or retrieval-augmented generation (RAG), this is one event you won't want to miss.
Now, back to the topic.
Manticore's vector search is built on top of our Columnar Library , and it lets you:
- Find content with similar meaning, even if the words are different
- Build recommendation systems that feel personal
- Group similar items together with zero manual tagging
- Deliver search results that are much more relevant than basic keyword matches
Under the hood, Manticore uses a highly efficient algorithm called HNSW (Hierarchical Navigable Small World) for vector search. It's designed to quickly find the most relevant results, even in large datasets — like finding the nearest neighbors in a massive city, but without needing a map.
Let's break down how embeddings power all of this and how HNSW helps turn those embeddings into fast, accurate search results.
2. What Are Embeddings (And Why Should You Care)?
To understand vector search, you first need to know about embeddings. They're the core idea behind it all.
Think of embeddings as a way to convert things — like words, images, or sounds — into a list of numbers that represent their meaning. It's a method that helps computers "understand" the world in a way that's closer to how we do.
How Do Embeddings Work?
Imagine a huge map where every point stands for a thing: a word, a sentence, an image, etc. The closer two points are, the more similar the things they represent. That's what embeddings do — they transform data into vectors (just sequences of numbers) that:
- Place similar things near each other in this multi-dimensional space
- Capture the meaning behind the data
– It lets us do math with ideas (remember the famous example from Word2Vec by Google researchers: king – man + woman = queen ?)

What Can You Turn Into Vectors?
Almost anything. Some common examples include:
- Text: Single words, full sentences, or even entire books. The vector for "beach" would be closer to "shore" than to "mountain."
- Images: Travel photos, product pics, or memes. Pictures of dogs will end up closer to each other than to pictures of cars.
- Audio: Speech, music, or sound effects. Heavy metal tracks cluster together, far away from quiet piano music.
These embeddings are the starting point. Once you have them, algorithms like HNSW help you search through them fast.
How Do We Measure Similarity?
Once we have these vectors, we need a way to measure how similar they are. Manticore Search supports three similarity metrics:
- Euclidean Distance (L2)
- Cosine Similarity
- Inner Product (Dot Product)
However, it's important to note that the choice of similarity metric is not arbitrary. The optimal metric often depends on the embedding model used to generate the vectors. Many embedding models are trained with a specific similarity measure in mind. For instance, some models are optimized for cosine similarity, while others may be designed for inner product or Euclidean distance. Using a different similarity measure than the one the model was trained with can lead to suboptimal results.
When setting up your Manticore Search table for vector search, you specify the similarity metric during the table creation process. This choice should align with the characteristics of your embedding model to ensure accurate and efficient search results.
Here's a brief overview of each metric:
Euclidean Distance (L2): Measures the straight-line distance between two vectors in space. It's sensitive to the magnitude of the vectors and is suitable when absolute differences are meaningful.
Cosine Similarity: Measures the cosine of the angle between two vectors, focusing on their orientation rather than magnitude. It's commonly used in text analysis where the direction of the vector (representing the concept) is more important than its length.
Inner Product (Dot Product): Calculates the sum of the products of the corresponding entries of two sequences of numbers. It's effective when both the magnitude and direction of the vectors are significant.
How Are These Vectors Created?
To use vector search, you first need to convert your data into vectors — and that's where embedding models come in. These models take raw data like text, images, or audio and turn it into numerical representations that capture meaning, context, or features.
Here are some widely used models that generate embeddings:
- Word2Vec: One of the earliest word embedding models. It helped show that relationships between words can be captured mathematically — like "king" is to "queen" as "man" is to "woman."
- GloVe: Developed by Stanford, this model also creates word embeddings by analyzing global word co-occurrence statistics. It's efficient and still widely used.
- FastText: From Facebook, this model improves on Word2Vec by understanding subword information. It can generate embeddings for words it hasn't seen before by breaking them into pieces.
- BERT: A transformer-based model from Google that understands words in context. For example, it distinguishes between "bank" in "river bank" vs. "bank account." It can produce embeddings for sentences, paragraphs, or entire documents.
- MPNet / MiniLM / all-MiniLM-L6-v2: These are optimized sentence embedding models from the SentenceTransformers family, ideal for tasks like semantic search, FAQ matching, and duplicate detection.
- OpenAI Embeddings (e.g.,
text-embedding-3-small): These are highly general-purpose embeddings used in applications like search, clustering, and classification. - CLIP: A model by OpenAI that understands both images and text in the same space. Show it a photo of a puppy, and it can match it to the text "cute dog."
- ResNet: A deep convolutional neural network that's great at converting images into embeddings. Commonly used for visual similarity and image classification.
- VGG / EfficientNet / Vision Transformers (ViT): Other strong image models widely used for turning pictures into vector embeddings.
- Whisper: OpenAI's model for transcribing audio into text, which can then be embedded for tasks like voice search or audio classification.
Manticore Search works with all of these and more. It doesn't lock you into a particular model — you can use whatever fits your project best, whether you're working with text, images, or audio. As long as you can convert your data into vectors, Manticore can search it.
3. How Does Vector Search Work?
Now that we've covered what embeddings are and how they represent similarity, let's look at how Manticore actually performs vector search. The real power behind the scenes comes from a clever algorithm called HNSW — short for Hierarchical Navigable Small World.
Yeah, it sounds like something out of a sci-fi novel — and honestly, it kind of is. But instead of guiding spaceships through wormholes, HNSW helps us navigate massive collections of vectors really, really fast.
HNSW: The Algorithm with the Terrible Name

Searching through a huge vector index is a bit like looking for a needle in a haystack — except the haystack has millions of straws, and some of them look a lot like the needle. If you had to check each one individually, it would take forever.
That's where HNSW comes in. It builds a clever structure so you can skip over most of the haystack and zero in on the best candidates quickly.
Here's how it works:
- It creates several layers of vectors — kind of like a multi-story building or a layered cake.
- The bottom layer has every single vector — your full dataset.
- Each higher layer has fewer vectors and longer-range links.
- When you search, it starts at the top layer, which helps you jump across the data quickly.
- At each level, it gets closer to the right area, refining the search as it goes down.
- By the time it hits the bottom, it's already in the right neighborhood.
This layered approach means you avoid scanning the whole dataset. Instead, you zoom in fast — which makes vector search in Manticore super efficient.
But What About Accuracy?
There's a small tradeoff. Because HNSW skips a lot of the data during search, there's a chance it won't find the absolute best match — just a very good one. In most real-world scenarios, that's totally fine. Whether you're doing semantic search, product recommendations, or clustering similar documents, "really close" is more than good enough.
But if your use case demands 100% precision — like matching DNA sequences or running scientific analyses — you might need a brute-force method instead. It'll be slower, but perfectly accurate.
For everything else, HNSW gives you the best of both worlds: blazing speed with high accuracy.
HNSW Algorithm Structure

Tweak It to Your Liking
Vector search in Manticore isn't just fast — it's also flexible. You can tune a couple of key settings to better fit your specific use case, depending on what you care about most: speed, accuracy, memory usage, or index build time.
Here are the main knobs you can turn:
hnsw_m(default: 16): This controls how many connections each vector makes to others — kind of like how many friends each person has in a social network. More connections mean better search accuracy but also more memory usage and slightly slower queries.hnsw_ef_construction(default: 200): This setting affects how thoroughly the index is built. Higher values result in better quality (and thus better search results), but they also make the indexing process slower and more memory-intensive.
These two parameters let you find the right balance between:
- 🔍 Search accuracy — How close the results are to the true nearest neighbors
- ⚡ Search speed — How fast the results come back
- 🧠 Memory usage — How much RAM the index consumes
- 🏗️ Indexing time — How long it takes to build the index
The default settings work well for most use cases, but here are some tips if you want to tweak:
- Want ultra-accurate results? Increase both
hnsw_mandhnsw_ef_construction - Tight on memory? Lower
hnsw_mto reduce connections - Need faster indexing? Lower
hnsw_ef_construction
Feel free to experiment — it's all about finding the sweet spot for your workload.
4. Getting Started: Setting Up Vector Search
Understanding the theory is great — but now let's get hands-on. Setting up vector search in Manticore is simple and flexible, and you can be up and running in just a few steps.
What You'll Need
To enable vector search, you'll need to define a table with at least one float_vector attribute. This is where your vectors — the actual embeddings — will be stored.
Key Settings to Define
When creating your table, there are three essential parameters you'll need to set:
knn_type: Set this tohnsw. (It's currently the only supported option, so no decisions to make here.)knn_dims: This defines the number of dimensions your vectors have. The value depends on the embedding model you're using:- BERT typically uses 768
- CLIP often uses 512
- Some sentence transformers use 384 or 1024
- Just make sure it matches the size of the vectors you'll be inserting
hnsw_similarity: Choose the similarity metric that matches how your embedding model was trained. The options are:L2(Euclidean Distance): Use this for geometric data, image features, and any case where physical distance mattersCOSINE: Best for text embeddings, semantic search, and when you care about direction, not magnitudeIP(Inner Product): Good for normalized vectors or use cases like recommendations where both size and direction are meaningful
🔍 Pro tip: Most modern text embedding models are trained with cosine similarity in mind. If you're not sure, check the model docs — or just start with
COSINEand experiment.
Once you've defined your table with these settings, you're ready to insert your vectors and start running lightning-fast, similarity-based searches.
Vector Search Workflow

Let's See a Real Example
Time to get hands-on. Here's how you'd create a table to store image vectors in Manticore Search:
create table cool_images (
id int,
title text,
image_vector float_vector knn_type='hnsw' knn_dims='4' hnsw_similarity='l2'
);
Now let's add some data:
insert into cool_images values
(1, 'yellow bag', (0.653448,0.192478,0.017971,0.339821)),
(2, 'white bag', (-0.148894,0.748278,0.091892,-0.095406));
(Of course, your real vectors will probably have hundreds of dimensions — we're keeping it small here for clarity.)
Transaction Support for Vector Operations
Vector operations in Manticore are fully transactional, which means you can perform multiple operations in a row and make sure they either all succeed or none do. That's super useful when you're updating both vector and non-vector fields and need to keep everything in sync.
Transaction Basics
- Transactions are supported for real-time tables with vector attributes
- Each transaction is atomic - either all operations succeed or none do
- Transactions are integrated with binary logging for durability and consistency
- By default, each command is its own mini-transaction (
autocommit = 1)
What You Can Do in a Transaction
You can include the following operations in a transaction:
- INSERT: Add new vectors
- REPLACE: Update existing vectors
- DELETE: Remove vectors
Vector fields don't support the UPDATE command. You can learn more about the difference between REPLACE and UPDATE here .
How to Control Transactions
You can control transactions in two ways:
- Automatic Mode (Default):
SET AUTOCOMMIT = 1
In this mode, each operation is automatically committed.
- Manual Mode:
SET AUTOCOMMIT = 0
This allows you to group multiple operations into a single transaction:
BEGIN;
INSERT INTO cool_images VALUES (3, 'red bag', (0.1, 0.2, 0.3, 0.4));
INSERT INTO cool_images VALUES (4, 'blue bag', (0.5, 0.6, 0.7, 0.8));
COMMIT;
Bulk Operations
For bulk operations, you can use the /bulk endpoint which supports transactions for multiple vector operations:
POST /bulk
{
"insert": {"table": "cool_images", "id": 5, "doc": {"title": "green bag", "image_vector": [0.1, 0.2, 0.3, 0.4]}},
"insert": {"table": "cool_images", "id": 6, "doc": {"title": "purple bag", "image_vector": [0.5, 0.6, 0.7, 0.8]}}
}
Notes to Keep in Mind
- Transactions are limited to a single real-time table
- Vector operations in transactions are atomic and consistent
- Changes are not visible until explicitly committed
- The binary log ensures durability of vector operations
- Transactions are particularly useful when you need to maintain consistency between vector data and other attributes
Searching for Similar Stuff
Now the cool part—searching for similar images:
Using SQL:
select id, title, knn_dist()
from cool_images
where knn (image_vector, 5, (0.286569,-0.031816,0.066684,0.032926), 2000);
This gives us:
+------+------------+------------+
| id | title | knn_dist() |
+------+------------+------------+
| 1 | yellow bag | 0.28146550 |
| 2 | white bag | 0.81527930 |
+------+------------+------------+
The yellow bag is closer to our query vector (smaller distance value), so it's more similar to what we're looking for.
Using the HTTP API:
Manticore provides a RESTful HTTP API for vector search operations. The main endpoint for vector search is:
POST /search
The request body should be in JSON format with the following structure:
{
"table": "<table_name>",
"knn": {
"field": "<vector_field_name>",
"query_vector": [<vector_values>],
"k": <number_of_results>,
"ef": <search_accuracy>
}
}
Key parameters:
table: The name of the table to search inknn.field: The name of the vector field to search againstknn.query_vector: The query vector as an array of float valuesknn.k: Number of nearest neighbors to returnknn.ef: (Optional) Size of the dynamic list used during search. Higher values give more accurate but slower results
Example request:
POST /search
{
"table": "products",
"knn": {
"field": "image_vector",
"query_vector": [0.1, 0.2, 0.3, 0.4],
"k": 5,
"ef": 2000
}
}
The response will be in JSON format:
{
"took": 6,
"timed_out": false,
"hits": {
"total": 2,
"total_relation": "eq",
"hits": [
{
"_id": 1,
"_score": 1,
"_knn_dist": 0.28146550,
"_source": {
"title": "yellow bag",
"image_vector": [0.653448, 0.192478, 0.017971, 0.339821]
}
},
{
"_id": 2,
"_score": 1,
"_knn_dist": 0.81527930,
"_source": {
"title": "white bag",
"image_vector": [-0.148894, 0.748278, 0.091892, -0.095406]
}
}
]
}
}
The response includes:
took: Time taken for the search in millisecondstimed_out: Whether the search timed outhits.total: Total number of matches foundhits.hits: Array of matching documents, each containing:_id: Document ID_score: Search score (always 1 for KNN search)_knn_dist: Distance to the query vector_source: Original document data
You can also combine KNN search with additional filters:
POST /search
{
"table": "products",
"knn": {
"field": "image_vector",
"query_vector": [0.1, 0.2, 0.3, 0.4],
"k": 5,
"filter": {
"bool": {
"must": [
{ "match": {"_all": "white"} },
{ "range": { "id": { "lt": 10 } } }
]
}
}
}
}

5. Advanced Search Features
With the basics of setup and configuration under our belts, let's explore the powerful capabilities that vector search brings to your applications. These features go far beyond traditional keyword search.
Two Ways to Search
You can search in two main ways:
- Direct Vector Search: Give me stuff similar to this vector. Great when you have a vector representation of what you want (like an image embedding or text embedding).
-- Example: Find items similar to a specific vector SELECT id, knn_dist() FROM products WHERE knn(image_vector, 5, (0.286569,-0.031816,0.066684,0.032926)); - Similar Document Search: Give me stuff similar to this document in my index. Perfect for "more like this" features, where users can click on something they like and find similar items.
-- Example: Find items similar to document with ID 1 SELECT id, knn_dist() FROM products WHERE knn(image_vector, 5, 1);
Both methods return results sorted by similarity (distance) to your query, with the most similar items appearing first.
Fine-Tuning Your Search
Two important settings control how your search behaves:
kparameter: How many results you want back. Too few and you might miss good matches. Too many and you might get irrelevant stuff.efparameter: How hard the algorithm tries to find the best matches. Higher values give more accurate results but take longer.
Results Come Sorted by Closeness
All search results automatically come sorted by how close they are to your query vector. The knn_dist() function shows you the actual distance value for each result, so you can see just how similar (or different) they are.
For example, if we search for images similar to a query vector:
select id, title, knn_dist()
from images
where knn (image_vector, 3, (0.1, 0.2, 0.3, 0.4));
The results will be automatically sorted by distance, with the closest matches first:
+------+----------------+------------+
| id | title | knn_dist() |
+------+----------------+------------+
| 1 | sunset beach | 0.12345678 |
| 3 | ocean view | 0.23456789 |
| 2 | mountain lake | 0.34567890 |
+------+----------------+------------+
Notice how the knn_dist() values increase as we go down the list - this shows that each result is progressively less similar to our query vector.
Mix and Match with Regular Search
The real magic happens when you combine vector search with traditional filters. For example, you can find images similar to a vector while also matching text:
select id, title, knn_dist()
from cool_images
where knn (image_vector, 5, (0.286569,-0.031816,0.066684,0.032926))
and match('white');
This finds images similar to our vector, but only if they have "white" in them:
+------+-----------+------------+
| id | title | knn_dist() |
+------+-----------+------------+
| 2 | white bag | 0.81527930 |
+------+-----------+------------+
Even though the yellow bag was technically more similar (vector-wise), it didn't match our text filter, so only the white bag appears.
6. Real-World Applications
Now that we've covered the core capabilities, let's look at some real-world applications where vector search can transform your user experience. These examples will help you understand how to apply these concepts in your own projects.
Smart Search That Understands What You Mean

Ever searched for something and thought "that's not what I meant!"? Smart search understands the meaning behind your query, not just the exact words.
With vector search you can:
- Find results that match what you're looking for, even if they use different words
- Search across languages (the meaning gets translated, not just the words)
- Actually understand what users are looking for
Real-world example: A knowledge base where customers find the right help article even when they use different terminology than your documentation.
Recommendation Systems That Make Sense

We've all experienced terrible recommendations: "You bought a refrigerator, would you like another refrigerator?". Vector search helps build recommendations that make sense:
- Find products similar to ones a customer liked
- Match user preferences with items
- Recommend across categories based on underlying attributes
- Personalize search results based on browsing history
Real-world example: An e-commerce site that can recommend a blue leather jacket after you looked at a blue leather bag, because it understands the style connection.
Image Search That Sees Like You Do

Traditional image search relies on text tags and metadata. Vector search lets you:
- Find images that look similar
- Upload an image and find matching ones (reverse image search)
- Group similar images without manual tagging
- Detect duplicates or near-duplicates
Real-world example: A stock photo site where designers can find visually similar images by uploading a reference image or concept sketch.
Video and Sound Search Beyond Tags
Apply the same principles to video and audio:
- Find similar video clips based on their content
- Search music by "sounds like this" rather than just genre tags
- Find moments in videos with similar visual elements
- Detect duplicate or similar audio tracks
Real-world example: A video editing platform that can instantly find all clips with similar visual compositions across all your projects.
Search Across Different Languages
Vector search really shines when it comes to multilingual applications. With the right embeddings, you can search across different languages — without needing to translate queries or documents manually.
How Cross-Language Search Works
- Language-Agnostic Embeddings
Modern multilingual models like mBERT, XLM-R, and LaBSE are trained to place semantically similar text — even in different languages — close together in the same vector space.
That means "apple" in English and "manzana" in Spanish end up near each other. So, when you search in one language, you can find results written in another. - Simple Table Setup
create table multilingual_docs ( id bigint, content text, language string, content_vector float_vector knn_type='hnsw' knn_dims='768' hnsw_similarity='cosine' );- Store documents in their original language
- Generate embeddings using a multilingual model
- Search just works — regardless of what language the query or document is in
- Search Across Languages:
select id, content, language, knn_dist() from multilingual_docs where knn (content_vector, 5, (0.1, 0.2, ...));- Enter your query in any supported language
- Results come back based on meaning, not language
- No translation or language detection needed
Real-World Applications
Multilingual vector search unlocks a wide range of global use cases, such as:
- Global E-commerce: Search and recommend products across languages, and support international customer queries
- Content Management: Find similar documents, detect duplicates, and build multilingual knowledge bases
- Customer Support: Match questions to answers across languages and route support tickets intelligently
- Social Media & Communities: Discover content, trends, and users across language boundaries
With the right multilingual embeddings, you can build search experiences that feel seamless — no matter what language your users speak.
Implementation Tips
- Pick the Right Model
Choose multilingual embedding models like LaBSE, XLM-R, or mBERT based on your language needs and task. Make sure the model you use supports the languages you expect in both queries and documents. - Preprocess Thoughtfully
Normalize and clean your input text consistently across languages before generating embeddings. Even small preprocessing differences (like punctuation or casing) can affect vector quality. - Store Language Info
Keep alanguagefield in your data. While vector search doesn't require it, it can help with filtering, analytics, or improving the user experience. - Design for Clarity
Show language information in search results, and allow users to filter or switch languages easily — especially if your app mixes multiple languages.
With these in place, you'll be ready to build search features that work naturally across languages — no translation layers required.
7. Making Vector Search Fast: Performance Tips
Building cool features is great, but they need to perform well in production. Let's dive into the performance considerations and optimization strategies that will ensure your vector search implementation runs smoothly.
Understanding RAM vs. Disk Storage
In Manticore, vector search works differently depending on whether your vectors are stored in RAM chunks or disk chunks:
- Disk Chunks:
- Each disk chunk maintains its own independent HNSW index
- For KNN queries that span multiple disk chunks, each chunk's index is searched separately
- This can impact search accuracy as each chunk's HNSW graph is limited to vectors within that chunk
- When searching across many disk chunks, query performance may be slower
- For tables with vector attributes, Manticore automatically sets a lower optimize_cutoff value (physical CPU cores divided by 2) to improve vector search performance
- RAM Chunk:
- Uses a more direct search approach for vectors
- May provide faster results for recently added data
- As the RAM chunk grows, vector search performance might gradually degrade
- Every RAM chunk eventually becomes a disk chunk when it reaches the size limit defined by
rt_mem_limit(default 128M) or when you explicitly convert it usingFLUSH RAMCHUNK
For optimal vector search performance, consider:
- Using batch inserts to minimize RAM chunk segment fragmentation
- Leveraging Manticore's auto-optimize feature, which automatically merges disk chunks to maintain optimal performance
- Adjusting
optimize_cutoffbased on your specific workload and CPU resources - Using
diskchunk_flush_write_timeoutanddiskchunk_flush_search_timeoutsettings to control auto-flushing behavior
The performance of vector search across disk chunks depends on the number of chunks and how they're distributed. Fewer disk chunks will generally provide better KNN search performance than many small chunks.
Understanding the ef Parameter
The ef parameter allows you to balance speed and accuracy:
- What It Does:
- Higher values give more accurate results but take longer
- Lower values are faster but might miss some good matches
- Finding the Sweet Spot:
- Start with the default (200)
- Increase if accuracy is critical
- Decrease if speed is paramount
- Test with your actual data!
8. Keeping Your Vector Data Safe: Backup Options
As your vector search implementation grows, ensuring data safety becomes crucial. Let's explore the backup strategies specifically designed for vector data in Manticore.
Physical Backups
Physical backups are particularly well-suited for vector data because:
- Speed: They directly copy the raw vector data files, which is crucial for large vector datasets
- Consistency: They ensure all vector data and HNSW indexes are backed up together
- Lower System Load: They don't require additional processing of vector data
You can use either:
- The
manticore-backupcommand-line tool:
manticore-backup --backup-dir=/path/to/backup --tables=your_vector_table
- The SQL BACKUP command:
BACKUP TABLE your_vector_table TO /path/to/backup
Logical Backups
Logical backups can be useful for vector data when you need:
- Portability: Moving vector data between different systems
- Selective Restoration: Restoring specific vector attributes or dimensions
- Version Migration: Switching between different Manticore versions. Newer versions usually support backward compatibility, so you probably won't need to use a data dump when upgrading. However, if you're downgrading to an older version, using a data dump might be useful.
You can use mysqldump for logical backups of vector data:
mysqldump -h0 -P9306 -e "SELECT * FROM your_vector_table" > vector_backup.sql
Best Practices for Vector Data Backups
Just like with any other type of backup, there are some good practices to follow when backing up your vector data.
- Regular Backups:
- Set up regular backups, especially after making big updates to your vector data
- Take the size of your vector data into account when deciding how often to back up
- Backup Location:
- Save backups in a place that has enough space for large vector data
- Use compression if your vector data is very large
- Testing:
- Test your backups regularly to make sure they can be restored
- After restoring, check that vector search still works correctly
- Version Control:
- Keep a record of the Manticore version you're using
- Make sure your backups will work with that version if you need to restore
- Monitoring:
- Keep an eye on backup sizes and how long they take
- Set up alerts in case any backups fail
9. Keeping Your Search System Available: Replication
Beyond backups, high availability is essential for production systems. Let's examine how Manticore's replication features work with vector search to ensure your system remains available and consistent.
Multi-Master Replication
Manticore supports the Galera library for replication and offers several key features:
- True Multi-Master: Read and write operations can be performed on any node at any time
- Virtually Synchronous: No slave lag and no data loss after node crashes
- Hot Standby: Zero downtime during failover scenarios
- Tightly Coupled: All nodes maintain the same state with no data divergence
- Automatic Node Provisioning: No manual backup/restore needed for new nodes
- Certification-Based Replication: Ensures data consistency across the cluster
Setting Up Replication for Vector Search
To enable replication for vector search:
- Configuration Requirements:
- The
data_diroption is set by default in the searchd configuration - A
listendirective with an accessible IP address is optional - replication will work without it - Optionally set unique
server_idvalues for each node
- The
- Creating a Replication Cluster:
CREATE CLUSTER vector_cluster - Adding Vector Tables to the Cluster:
ALTER CLUSTER vector_cluster ADD vector_table - Joining Nodes to the Cluster:
JOIN CLUSTER vector_cluster AT 'host:port'
When working with vector data in a replicated environment:
- Write Operations:
- All vector modifications (INSERT, REPLACE, DELETE, TRUNCATE) must use the
cluster_name:table_namesyntax - Changes are automatically propagated to all replicas
- Vector operations maintain consistency across the cluster
- All vector modifications (INSERT, REPLACE, DELETE, TRUNCATE) must use the
- Transaction Support:
- Vector operations are atomic across the cluster
- Changes are not visible until explicitly committed
- Binary logging ensures durability of vector operations
Limitations and Considerations
- Replication is supported for real-time tables with vector attributes
- Windows native binaries do not support replication (use WSL instead)
- macOS has limited replication support (recommended for development only)
- Each table can only belong to one cluster
10. See Vector Search in Action: Live Demos
Theory and configuration are important, but seeing is believing. Let's explore some real-world demos that showcase the power of Manticore's vector search capabilities in action.
GitHub Issue Search
Our GitHub Issue Search demo lets you search through GitHub issues with understanding the meaning behind the words. Unlike GitHub's native search that only matches keywords, our demo understands what you're looking for.
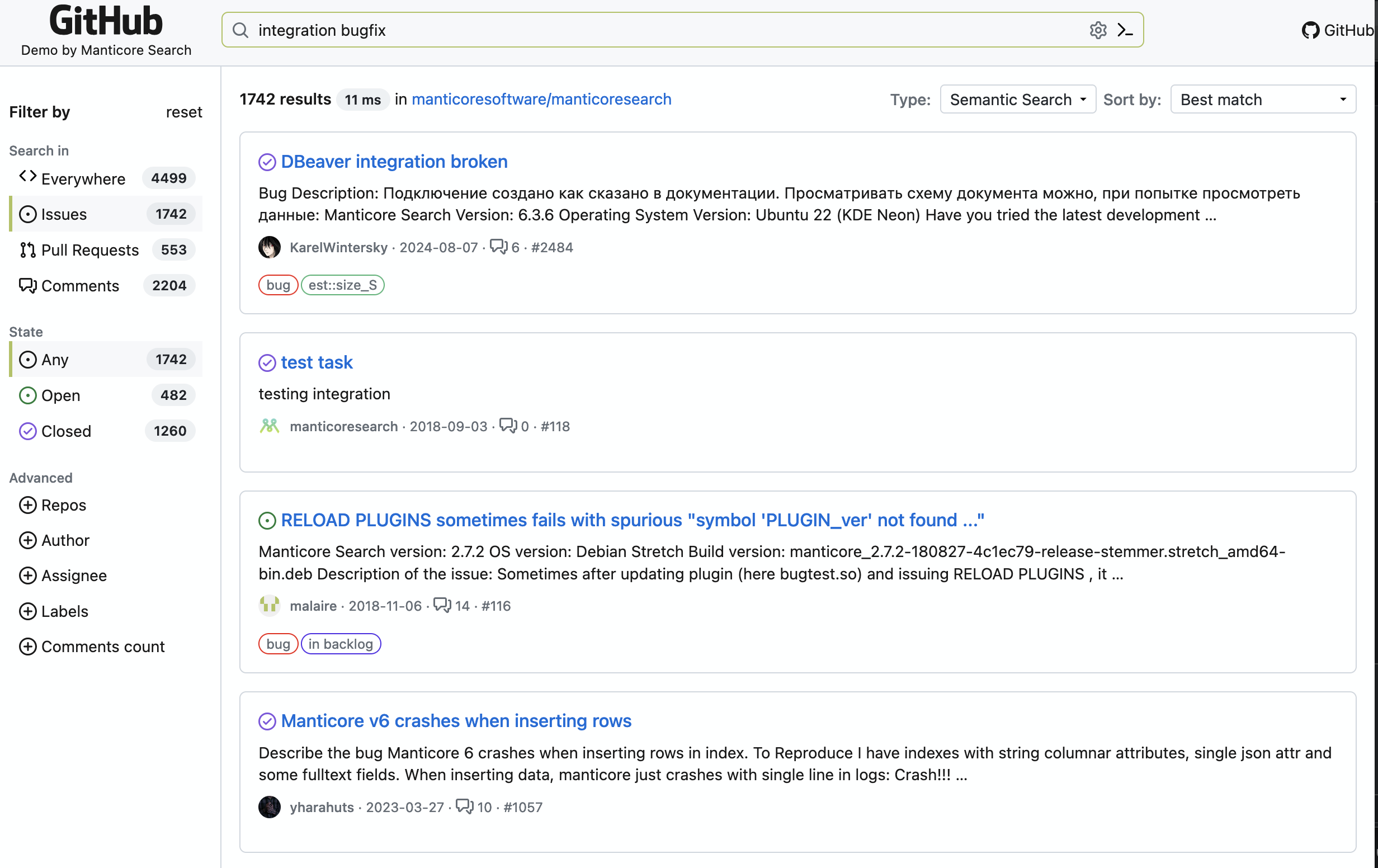
This demo is built on Manticore Search's vector capabilities and is fully open source. You can explore the source code on GitHub to see how we implemented it.
Try searching for concepts rather than just keywords - the search understands what you're looking for even when the exact words don't match!
How the GitHub Issue Demo Works
The GitHub Issue Search demo uses a powerful embedding model to convert both GitHub issues and your search queries into semantic vector representations. This allows the system to find issues that are conceptually similar to your query, even if they use different terminology.
Key features:
- Smart search across thousands of GitHub issues
- Real-time filtering by repository, labels, and more
- User-friendly interface with syntax highlighting
- Fast response times powered by Manticore's HNSW algorithm
This approach dramatically improves search quality compared to traditional keyword-based search, helping developers find solutions to their problems more efficiently.
Image Search Demo
Our Image Search demo shows how vector search can power visual similarity searches. Upload any image, and the system will find visually similar images based on what's actually in the picture, not just tags or metadata.
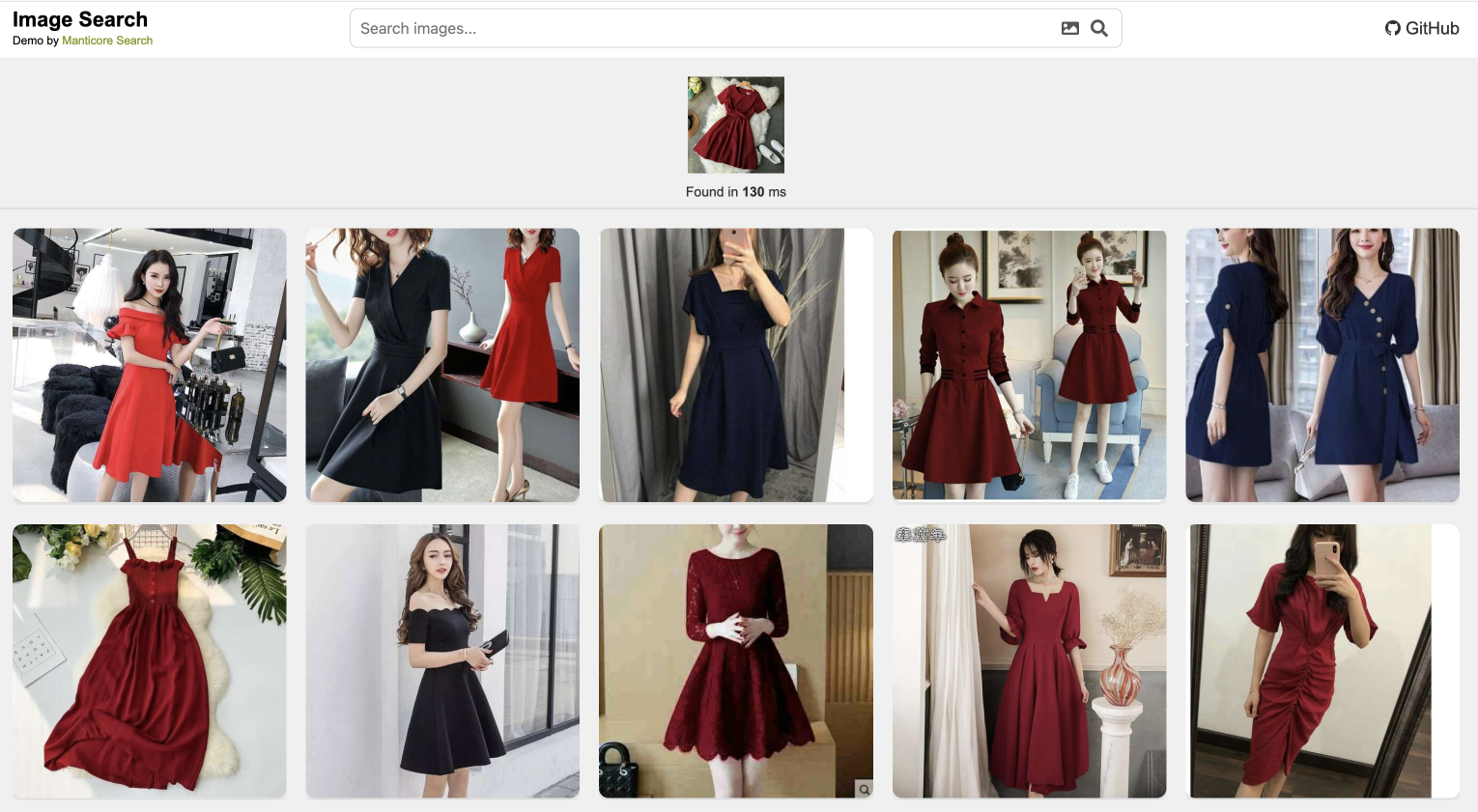
This demo uses a machine learning model to convert images into vectors, then uses Manticore's KNN search to find similar images. The source code is available in our manticore-image-search repository .
How the Image Search Demo Works
The Image Search demo leverages a pre-trained vision model to extract meaningful features from images and represent them as high-dimensional vectors. When you upload an image or select one from the gallery:
- The image is processed by the vision model to generate a feature vector
- Manticore's vector search finds the nearest neighbors to this vector
- The most similar images are returned, ranked by their similarity score
- All of this happens in milliseconds, providing a smooth user experience
The demo handles a diverse range of image types and can find similarities based on content, style, color patterns, and even abstract concepts present in the images.
Create Your Own Demo
Both demos are excellent starting points for building your own vector search applications. Whether you're interested in:
- Smart document search
- Image or video retrieval systems
- Recommendation engines
- Content classification
You can leverage the same architecture and adapt it to your specific use case. The source code for both demos provides practical examples of how to:
- Generate embeddings for your data
- Structure your Manticore tables for vector search
- Implement efficient search APIs
- Build user-friendly interfaces
These demos demonstrate how vector search can be applied to real-world problems with impressive results. They're also fully open source, so you can learn from them or even deploy your own version!
By tweaking these settings, you can make vector search lightning-fast for your specific needs. Remember, the right configuration depends on your data, your hardware, and what you're trying to accomplish. Don't be afraid to experiment!
11. Running Vector Search in Production
After exploring all these features and capabilities, it's time to discuss what it takes to deploy vector search in a production environment. Let's cover the critical factors that will ensure your implementation is reliable, scalable, and performs optimally.
What You Need: Infrastructure Requirements
- Hardware Considerations:
- CPU: Vector operations are CPU-intensive
- Modern multi-core processors recommended
- Consider CPU cache size for vector operations
- Monitor CPU utilization during peak loads
- Memory:
- HNSW indexes require significant RAM
- Plan for 2-3x the size of your vector data
- Consider memory fragmentation over time
- Storage:
- Fast SSDs recommended for disk chunks
- Consider RAID configurations for reliability
- Plan for backup storage requirements
- CPU: Vector operations are CPU-intensive
- Network Configuration:
- High bandwidth for replication
- Low latency for distributed setups
- Proper firewall rules for cluster communication
- Load balancer configuration for high availability
12. Conclusion: The Future of Vector Search
Vector search represents a fundamental shift in how we approach search and similarity matching in modern applications. Throughout this deep dive, we've explored how Manticore Search implements this powerful technology, from the underlying concepts of embeddings to production-ready deployment strategies.
Key takeaways from our exploration:
- Powerful Capabilities: Vector search enables understanding the meaning behind the words, going beyond traditional keyword matching to find truly relevant results based on meaning and context.
- Flexible Implementation: Manticore's vector search can be applied to various use cases, from text search to image matching, recommendations, and multilingual applications.
- Production-Ready: With features like replication, backup options, and performance optimization, Manticore's vector search is ready for enterprise deployment.
- Easy to Get Started: Despite its sophisticated capabilities, vector search in Manticore is accessible and can be implemented with minimal configuration.
As we look to the future, vector search will continue to evolve and become even more integral to modern applications. The ability to understand and match content based on meaning rather than just keywords is transforming how users interact with data. Whether you're building a search engine, recommendation system, or content discovery platform, vector search provides the foundation for creating more intelligent and user-friendly applications.
To get started with vector search in your own projects, check out our GitHub repository and join our community . We're excited to see what you'll build with Manticore's vector search capabilities!
Remember: The best way to understand the power of vector search is to try it yourself. Start with our demos and experiment with your own use cases. The possibilities are endless, and we're here to help you explore them.