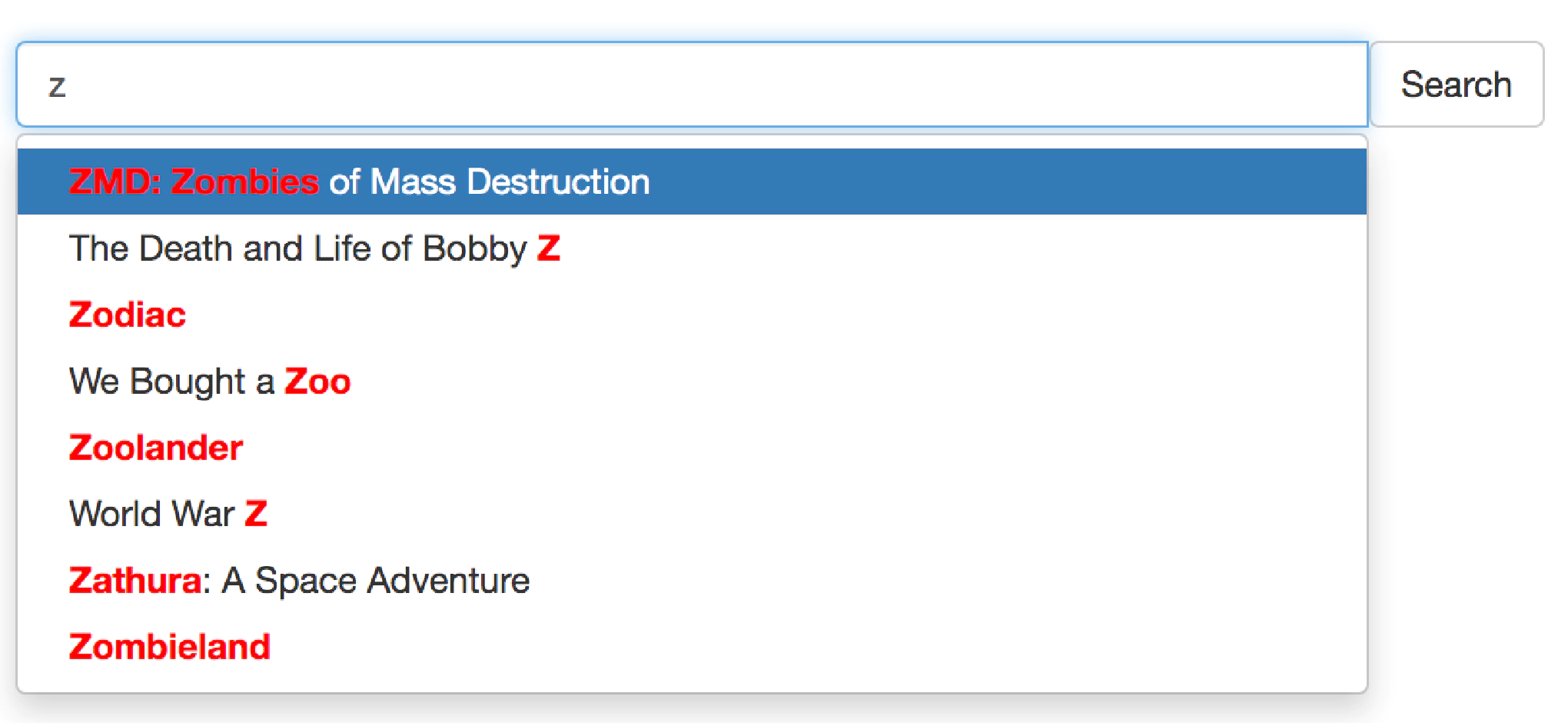
This article describes one of the ways to do word completion in Manticore Search.
What is Autocomplete?
Autocomplete (or word completion) is a feature which allows an application to predict the rest of a word while a user is typing it. How it usually works is: the user starts typing a word in the search bar, and a dropdown with suggestions pops up so the user can select one from the list.
The source of the suggestions can be various. It's best if the word or the sentence displayed is available in the existing data collection, so the user doesn't select something that will return empty results. But in some cases autocomplete is based on previous (successful) searches which in theory can find zero results, but might still make sense. It all depends on specifics of your application.
The simplest autocomplete can be made by finding suggestions from headlines of items in the dataset. That can be a title of an article/news, name of a product or as we will show soon name of a movie. To do that we need to have the field defined as a string attribute or a stored field . Just to not do an extra lookup in the original data.
Since the user is supposed to provide an incomplete word, we need to perform a wildcard search. Wildcard searches are possible by activating prefixing or infixing in the index. As it may affect the response time you need to decide whether you want that to be enabled in the index that is used for searches or you enable it only in a special index dedicated to the autocomplete functionality. Another reason to do so is to make the latter as compact as possible to provide minimal latency as it's especially important for autocomplete UX-wise. Usually we would add a wildcard asterisk to the right, as we assume the user starts a word, however for broader results, we add asterisks to both sides to get words that could have a prefix too. In this course for the movies dataset let's choose infixing, as it also enables the SUGGEST feature for word correction (see how it works in this course ). Our index declaration will be:
index movies {
type = plain
path = /var/lib/manticore/data/movies
source = movies
min_infix_len = 3
}
As we are going to provide autocomplete from the movie title, our queries will be limited to the 'movie_title' field.
Autocomplete on the movie title
Your application's frontend can start querying for suggestions from the first character typed in the search box. However that can put more pressure on the system in case of a huge index as it's going to do more requests to the server and also 1-2 chars wildcard searches can be slower. Let's assume the user types 'sha'.
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title sha*');
+------+---------------------------------------+
| id | movie_title |
+------+---------------------------------------+
| 118 | A Low Down Dirty Shame |
| 394 | Austin Powers: The Spy Who Shagged Me |
| 604 | Book of Shadows: Blair Witch 2 |
| 951 | Dark Shadows |
| 1318 | Fifty Shades of Black |
| 1319 | Fifty Shades of Grey |
| 1389 | Forty Shades of Blue |
| 1853 | In the Shadow of the Moon |
| 1928 | Jack Ryan: Shadow Recruit |
| 3114 | Shade |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 3117 | Shadowlands |
| 3118 | Shaft |
| 3119 | Shakespeare in Love |
| 3120 | Shalako |
| 3121 | Shall We Dance |
| 3122 | Shallow Hal |
| 3123 | Shame |
| 3124 | Shanghai Calling |
+------+---------------------------------------+
20 rows in set (0.00 sec)
We mostly care only about the movie title, so we're not returning all the columns. As we can see a lot of results are returned. We can try to tweak the query by for example adding a secondary sorting by facebook likes, but it will be still too early to make a good guess on what the user is looking for:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title sha*') ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3131 | Shark Tale |
| 394 | Austin Powers: The Spy Who Shagged Me |
| 3118 | Shaft |
| 4326 | The Shaggy Dog |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3134 | Shattered |
| 3123 | Shame |
| 3525 | The Adventures of Sharkboy and Lavagirl 3-D |
| 3117 | Shadowlands |
| 3129 | Shark Lake |
| 4328 | The Shawshank Redemption |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 3135 | Shattered Glass |
| 3130 | Shark Night 3D |
| 1319 | Fifty Shades of Grey |
| 4619 | Tristram Shandy: A Cock and Bull Story |
| 118 | A Low Down Dirty Shame |
| 3132 | Sharknado |
| 1318 | Fifty Shades of Black |
+------+--------------------------------------------------+
20 rows in set (0.00 sec)
Let's assume the user types another letter:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shaf*') ORDER BY WEIGHT() DES , cast_total_facebook_likes DESC;
+------+-------------+
| id | movie_title |
+------+-------------+
| 3118 | Shaft |
+------+-------------+
1 row in set (0.00 sec)
Now we have a single result.
Let's take another example where we type 'shad*' instead.
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shad*') ORDER BY WEIGHT() DES , cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3117 | Shadowlands |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 1319 | Fifty Shades of Grey |
| 1318 | Fifty Shades of Black |
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 1389 | Forty Shades of Blue |
| 604 | Book of Shadows: Blair Witch 2 |
| 3114 | Shade |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+--------------------------------------------------+
15 rows in set (0.00 sec)
Then shado*:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shado*') ORDER BY WEIGHT() DE C, cast_total_facebook_likes DESC;
+------+--------------------------------------------------+
| id | movie_title |
+------+--------------------------------------------------+
| 951 | Dark Shadows |
| 3142 | Sherlock Holmes: A Game of Shadows |
| 3117 | Shadowlands |
| 3494 | Teenage Mutant Ninja Turtles: Out of the Shadows |
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 604 | Book of Shadows: Blair Witch 2 |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+--------------------------------------------------+
11 rows in set (0.00 sec)
And 'shadow':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shadow') ORDER BY WEIGHT() DE C, cast_total_facebook_likes DESC;
+------+---------------------------+
| id | movie_title |
+------+---------------------------+
| 4325 | The Shadow |
| 3115 | Shadow Conspiracy |
| 3116 | Shadow of the Vampire |
| 1928 | Jack Ryan: Shadow Recruit |
| 1853 | In the Shadow of the Moon |
| 4353 | The Sound and the Shadow |
+------+---------------------------+
6 rows in set (0.00 sec)
Assuming the user was looking for 'shadow' as the first word, he'll proceed with typing another word, e.g. 'shadow c':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title shadow c*') ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+------+-------------------+
| id | movie_title |
+------+-------------------+
| 3115 | Shadow Conspiracy |
+------+-------------------+
1 row in set (0.01 sec)
In this case, we get a single result which should satisfy the user, but in other cases we may get more and the user would continue typing letters just like for the first word and Manticore would return more suggestions based on the input:

Adding more filters
In the previous examples the only restriction for the matched terms was to be a part of the specified field. We can have a more restrictive autocomplete, if we want.
For example here we get matches starting with 'americ', like 'American Hustle', but also 'Captain America: Civil War':
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title americ* ') ORDER BY WEIGHT() D SC, cast_total_facebook_likes DESC;
+------+---------------------------------------------------+
| id | movie_title |
+------+---------------------------------------------------+
| 277 | American Hustle |
| 701 | Captain America: Civil War |
| 703 | Captain America: The Winter Soldier |
| 282 | American Psycho |
| 2612 | Once Upon a Time in America |
| 272 | American Gangster |
| 702 | Captain America: The First Avenger |
| 269 | American Beauty |
| 478 | Beavis and Butt-Head Do America |
| 284 | American Sniper |
| 4036 | The Legend of Hell's Gate: An American Conspiracy |
| 273 | American Graffiti |
| 285 | American Splendor |
| 274 | American Heist |
| 287 | America's Sweethearts |
| 283 | American Reunion |
| 280 | American Pie |
| 281 | American Pie 2 |
| 271 | American Dreamz |
| 286 | American Wedding |
+------+---------------------------------------------------+
20 rows in set (0.00 sec)
We can use the start field operator to show only the records starting with the input term:
MySQL [(none)]> SELECT id, movie_title FROM movies WHERE MATCH('@movie_title ^americ* ') ORDER BY WEIGHT() ESC, cast_total_facebook_likes DESC;
+------+-------------------------------------+
| id | movie_title |
+------+-------------------------------------+
| 277 | American Hustle |
| 282 | American Psycho |
| 272 | American Gangster |
| 269 | American Beauty |
| 284 | American Sniper |
| 273 | American Graffiti |
| 285 | American Splendor |
| 274 | American Heist |
| 287 | America's Sweethearts |
| 283 | American Reunion |
| 280 | American Pie |
| 281 | American Pie 2 |
| 271 | American Dreamz |
| 286 | American Wedding |
| 276 | American History X |
| 268 | America Is Still the Place |
| 279 | American Outlaws |
| 275 | American Hero |
| 278 | American Ninja 2: The Confrontation |
| 270 | American Desi |
+------+-------------------------------------+
20 rows in set (0.00 sec)
Another thing we should take into consideration is duplicates. This applies more to the cases when we want to autocomplete on a field that doesn't have unique values. As an example let's try to do an autocomplete by an actor name:
MySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ');
+--------------------+
| actor_1_name |
+--------------------+
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| Don Johnson |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Johnny Depp |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
| R. Brandon Johnson |
| Dwayne Johnson |
| Johnny Depp |
| Johnny Depp |
+--------------------+
20 rows in set (0.09 sec)
We can see a lot of duplicates. It can be solved by simply grouping on that field - assuming we have it as a string attribute:
MySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name; [AMySQL [(none)]> SELECT actor_1_name FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name;
+------------------------+
| actor_1_name |
+------------------------+
| Johnny Depp |
| Dwayne Johnson |
| Don Johnson |
| R. Brandon Johnson |
| Johnny Pacar |
| Kenny Johnston |
| Johnny Cannizzaro |
| Nicole Randall Johnson |
| Johnny Lewis |
| Richard Johnson |
| Bill Johnson |
| Eric Johnson |
| John Belushi |
| John Cothran |
| John Ratzenberger |
| John Cameron Mitchell |
| John Saxon |
| John Gatins |
| John Boyega |
| John Michael Higgins |
+------------------------+
20 rows in set (0.10 sec)
Highlighting
The autocomplete query can return results with highlighting included. While it can be performed on the applications' side too highlighting done by Manticore Search is more powerful because it will follow the search query (the same tokenization settings, ANDs, ORs and NOTs in the query and so one ). Taking the previous example, all we need to do is to use the 'SNIPPET' function:
MySQL [(none)]> SELECT SNIPPET(actor_1_name,' john*') FROM movies WHERE MATCH('@actor_1_name john* ') GROUP BY actor_1_name ORDER BY WEIGHT() DESC, cast_total_facebook_likes DESC;
+--------------------------------+
| snippet(actor_1_name,' john*') |
+--------------------------------+
| <b>Johnny</b> Depp |
| Dwayne <b>Johnson</b> |
| <b>Johnny</b> Pacar |
| Don <b>Johnson</b> |
| <b>Johnny</b> Cannizzaro |
| <b>Johnny</b> Lewis |
| Eric <b>Johnson</b> |
| Nicole Randall <b>Johnson</b> |
| Kenny <b>Johnston</b> |
| R. Brandon <b>Johnson</b> |
| Bill <b>Johnson</b> |
| Richard <b>Johnson</b> |
| <b>John</b> Ratzenberger |
| <b>John</b> Belushi |
| <b>John</b> Cameron Mitchell |
| <b>John</b> Cothran |
| Olivia Newton-<b>John</b> |
| <b>John</b> Michael Higgins |
| <b>John</b> Witherspoon |
| <b>John</b> Amos |
+--------------------------------+
20 rows in set (0.00 sec)
You can find more info about the highlighting in this course .
Besides using the infixes and prefixes there are other ways to do Autocomplete in Manticore: using CALL KEYWORDS , with or without bigram_index turned on, using CALL QSUGGEST / CALL SUGGEST . But the way it's shown in this article seems to be the easiest to get started with. If you want to play with Manticore Search try out our docker image which has a one-liner to run Manticore on any server in just few seconds.