
Об авторе

Привет, я Майк.
Недавно я начал работать в компании Manticore на должности Developer Advocate. Я не совсем далёк от ИТ, но сейчас активно осваиваю современные технологии. В этом блоге я буду делиться своим опытом и тем, что узнаю о Manticore. Я планирую вести дневник, где буду рассказывать, что такое Manticore и как с ним работать. Давайте вместе разбираться, как все устроено, выявлять проблемы и взаимодействовать с разработчиками.
Если вам интересно изучать Manticore вместе со мной, я буду держать вас в курсе в:
О репликации
Для чего в целом может потребоваться репликация?
В прошлой статье мы делали обновление настроек полнотекстового поиска в виде замены файла словоформ, и в это время таблица была недоступна. В формате нашего примера с магазином — это не заняло критически много времени, несколько секунд недоступности сервера ведь не такая большая цена за удобство? Для маленьких проектов - возможно да. Но наш магазин растёт, товаров становится всё больше, как и клиентов, и теперь подобные изменения настроек сервера могут привести к ограничениям работы системы на несколько часов. Ведь чем больше база данных, тем дольше придется её переиндексировать, хоть для Мантикоры это и не критические дни и недели, а пусть только пара часов, но даже такую задержку допускать бы не хотелось. Также, если с нашим единственным сервером что-то случится? Или количество клиентов на него одного станет слишком большим — все преимущества высокоскоростного поисковика будут утеряны. Поэтому теперь нам стоит озаботиться созданием нескольких, одновременно и параллельно работающих копий одной базы данных, и так, чтобы при записи в одной из них данные автоматически копировались на остальные связанные сервера или ноды.
В Мантикоре репликация между нодами реализована через библиотеку Galera. Galera использует технологию синхронной мульти-мастер репликации, которая обеспечивает высокую доступность и отказоустойчивость для кластеров баз данных. При добавлении новой записи на одном из серверов (ноде), изменение мгновенно транслируется на все подключенные ноды. Этот процесс включает в себя три фазы: запись в локальный журнал транзакций на исходной ноде, репликация изменений на другие ноды и подтверждение получения данных всеми нодами перед фактическим применением транзакции. Транзакция применяется только после получения подтверждения от всех нод кластера, что гарантирует консистентность данных на всех нодах. Для пользователя эти процессы остаются незаметными, и доступ к новым данным с любой ноды происходит мгновенно после успешного завершения транзакции на этой ноде.
Первоначальная настройка
На данный момент наш контейнер из прошлой статьи нормально работает, но в случае его остановки и удаления данные будут утеряны безвозвратно. Руководство по запуску контейнеров с Мантикорой настоятельно рекомендует использовать маппинг диска (папки) с данными за пределы докера. Кроме того, конфигурация, которую мы делали в прошлый раз, не предусматривала проброс нужного для репликации бинарного порта 9312. Давайте это исправим, создав слепок папки с работающего контейнера и запустим новый с правильными настройками портов и хранилища.
Сначала надо обеспечить целостность данных, заходим в контейнер и в Мантикоре делаем “заморозку” таблицы, так все данные, что могут находиться в оперативной памяти, будут надежно перемещены на диск и во время копирования на диске ничего не изменится.
FREEZE products;
Теперь скопируем директорию с данными мантикоры из контейнера наружу:
docker cp Manticore:/var/lib/manticore .
Команда состоит из трех частей:
cp- копировать,Manticore:/var/lib/manticore- имя контейнера и путь к папке внутри него,.- локальный путь, куда копировать, в данном случае это текущий каталог.
Для того чтобы текущий контейнер продолжил работать в прежнем режиме — делаем “разморозку”:
UNFREEZE products;
Теперь создадим новый контейнер с нужными нам настройками:
docker run -e EXTRA=1 --name manticore_new -v $(pwd)/manticore:/var/lib/manticore -p 10306:9306 -p 10312:9312 -d manticoresearch/manticore
docker exec -it manticore_new mysql
В результате этой манипуляции у нас есть клон нашего контейнера с проброшенными портами и местоположением файлов базы на сервере за пределами контейнера. Давайте проверим, всё ли в нашем новом контейнере на месте: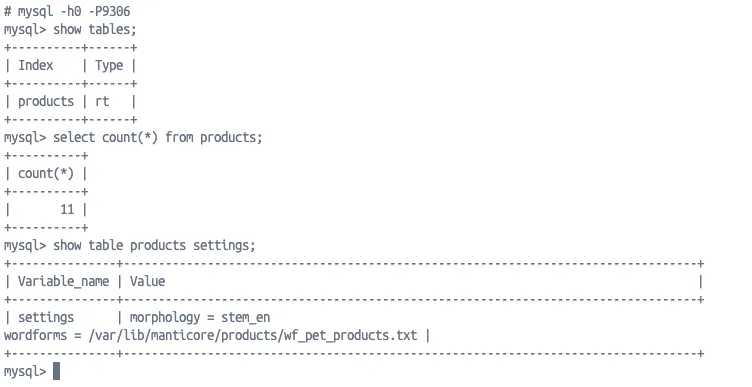
Отлично, все данные перенеслись, включая конфигурацию и файл словоформ, и теперь на базе этого контейнера мы будем создавать кластер.
Кстати, немного про файл словоформ: в скопированной нами папке есть экземпляр этого файла, рекомендую его оттуда скопировать, ведь в дальнейшем, как показала практика, править его может пригодиться, а использовать для этого файл, находящийся в папке с таблицей, неправильная затея, которая в итоге может привести к некоторым проблемам. Я себе сделал копию за пределы папки базы данных: cp manticore/products/wf_pet_products.txt wf_pet_products.txt
И еще приятная новость, поговорили с коллегами — скоро файл словоформ при использовании mysqldump таскать руками никуда не надо будет, всё автоматом будет складываться в дамп. Вот задачка на гитхабе.
Создаём наш первый кластер
Для того чтобы реализовать наш новый кластер каких-то сложных операций не требуется — достаточно с помощью одной команды создать кластер с именем, потом присоединить к нему нужную таблицу. Далее останется только проверить, как всё сложилось.
- Для добавления кластера используется команда
CREATE CLUSTER - Для добавления таблицы к кластеру используется команда
ALTER CLUSTER ADD. Тут важно подчеркнуть, что кластеризация, репликация и прочие радости Мантикоры доступны только для таблиц RT типа!
Итак — создаём наш первый кластер, и сразу добавим в него нашу таблицу:
CREATE CLUSTER pet_shop;
ALTER CLUSTER pet_shop add products;
Теперь проверим, что у нас получилось, для этого используется команда show status, но она выдаст фантастически много информации, и чтобы в ней не теряться, можно использовать запись с помощью операнда like:
show status like '%cluster%';
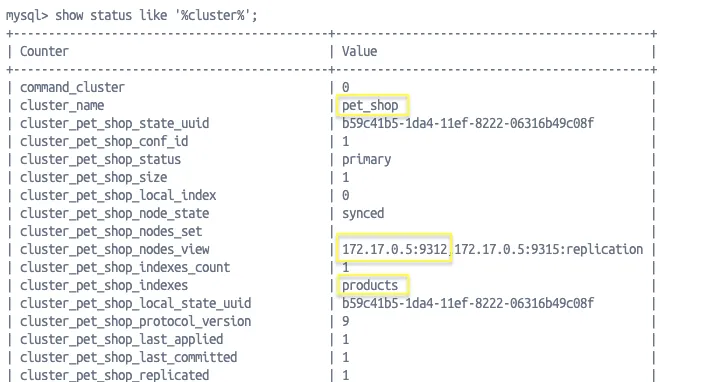
На данный момент нам интересны следующие строчки: cluster_name, cluster_pet_shop_status, cluster_pet_shop_indexes. В них отображается имя кластера, состояние (если Primary — значит, всё хорошо) и таблицы, которые в этот кластер сейчас входят.
Отдельно запомним строку cluster_pet_shop_incoming_addresses, в моей сборке она выглядит так: 172.17.0.5:9312,172.17.0.5:9315:replication, из нее нам понадобится адрес 172.17.0.5:9312, при этом порт 9312 проброшен на порт 10312 в условиях сервера за пределами Докера, но в примере мы будем запускать новую ноду в условиях того же Докера и сети 172.17.0.0, что упрощает нам задачу по использованию портов.
Технически, можно было бы использовать и исходный контейнер из статьи про Wordforms, просто добавив на него кластер и подключив таблицу, а новый контейнер уже собрать с подключением внешнего хранилища и быть спокойными, что репликация всё перетащит и в локальный образ. Но тогда бы я не показал, как можно решить задачу иным способом, с сохранением дампа через копирование папки из контейнера… =)
Мы уверенно придумываем себе проблемы и героически их решаем! =)
Первая нода у нас уже настроена, больше никаких дополнительных действий не требуется. Просто? По-моему — очень!
Добавляем ещё одну ноду в кластер
Для начала нам нужно запустить ещё один контейнер с Мантикорой. Переносить на неё мы уже ничего не будем, просто подключим её в уже существующий кластер. Разве что локальное хранилище должно быть другим (подключаемые папки должны быть разными, если вы это делаете на одном сервере). Важно снова напомнить о портах, поскольку у нас уже использованы порты 9306, 10306 и 10312. Следовательно, назначим другие порты, например, 11306 и 11312.
Создаём еще один контейнер с экземпляром Мантикоры, называем его Manticore_new_1. В качестве портов указываем 11306 и 11312, для тома укажем manticore_new_1 (локальная папка должна уже существовать), и не забудем установить переменную окружения EXTRA=1.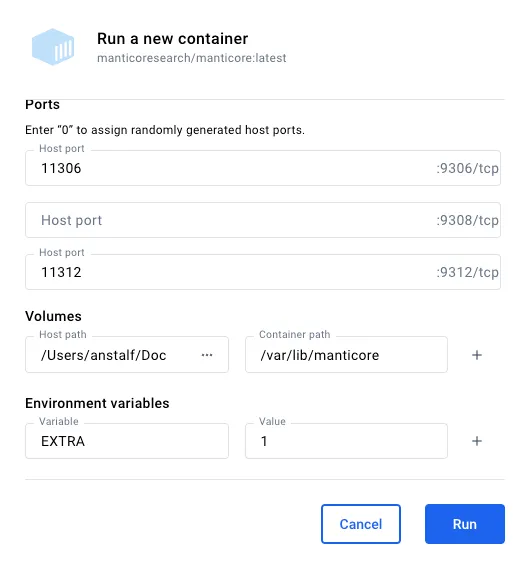
Или всё то же самое одной командой:
docker run -e EXTRA=1 --name manticore_new_1 -v $(pwd)/manticore_new_1:/var/lib/manticore -p 11306:9306 -p 11312:9312 -d manticoresearch/manticore
Заходим через клиент mysql. Тут есть нюанс: если вы используете для подключения локальный клиент mysql, а не тот, что внутри контейнера — то для подключения используйте внешний порт, который указывали при создании ноды — 11306, если же используется интерфейс докера и входите через терминал контейнера (docker exec), то используется порт, который для Мантикоры установлен по умолчанию — 9306. В любом случае — подключились. Посмотрим, есть ли таблица — show tables. Результат, ожидаемо, пустой, так как мы только что создали пустой контейнер с Мантикорой. Теперь подключим его к существующему кластеру — join cluster pet_shop at '172.17.0.5:9312';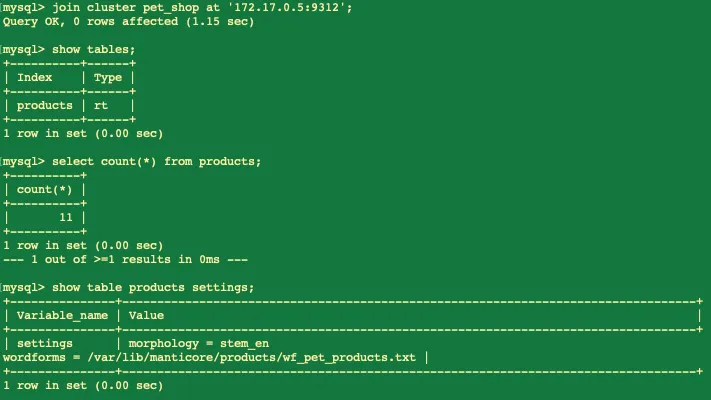
Для наглядности изменил цвет консоли для второй ноды.
Как видим, таблица добавилась, результат количества записей совпадает с исходной нодой, конфигурация стеммера и файла словоформ правильная.
В принципе — на этом всё, кластер собран и работает, данные передаются между нодами.
Важное замечание. Если на подключаемой к кластеру ноде есть таблицы с тем же названием, что и таблицы в кластере, то таблицы на ноде при подключении к кластеру будут перезаписаны данными из кластера. Запись в кластере имеет более высокий приоритет над локальными таблицами, поэтому, если вы подключаете существующую ноду уже с некоторым наполнением, убедитесь, что имена существующих таблиц отличаются от тех, что есть в кластере. Ну, и как обычно — в любой непонятной ситуации, делайте бэкап.
Управление данными в кластере
При работе с данными таблицы в кластере есть некоторые отличия, так как команда insert уже требует некоторых доработок — теперь нам надо указывать, кроме имени таблицы, еще и ее принадлежность к кластеру: insert into <cluster name>:<table name>(<fields>) values (<values>). Не забудьте исправить эту команду в своем клиенте.
Добавим еще одну запись, находясь в только что созданной ноде:
insert into pet_shop:products (name, info, price, avl) values ('Aquarium ship', 'Decorative ship model for aquarium', 6, 1);
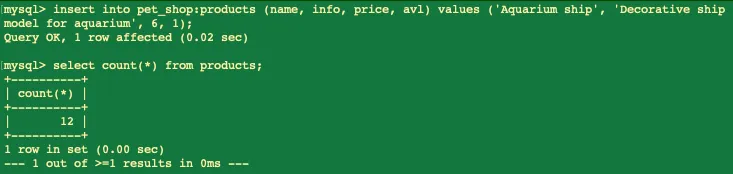
Судя по результату - запись добавлена, а как дело обстоит в другой ноде?
И тут всё на месте!
Попробуем обновить данные:
mysql> update products set price = 8.0 where id = 3317338896206921730;
ERROR 1064 (42000): table products: table 'products' is a part of cluster 'pet_shop', use 'pet_shop:products'
Для действий с обновлением, изменением и уж тем более, удалением записей теперь также необходимо указывать имя кластера в имени таблицы:
update pet_shop:products set price = 8 where id = 3317338896206921730;
Query OK, 1 row affected (0.01 sec)
С данными разобрались, они у нас теперь передаются между нодами автоматически и без особых усложнений всей конструкции, кроме, разве что, небольшого изменения процесса обновления записей.
Изменения настроек реплицируемой таблицы
А что делать в случае, если нам нужно изменить конфигурацию таблицы, или вообще её удалить, например, чтобы изменить файл словоформ? В прошлой статье для этого нам пришлось удалять и создавать таблицу заново, при этом оставив на некоторое время пользователя без ответов сервера. В том примере время, потребовавшееся нам для выполнения обновления настройки, было совсем небольшим, но и таблица была маленькая. В случае с большими базами данных, таблицами по много миллионов записей и т.д., обновление и индексация могут занять продолжительное время, во многих случаях измеряемое часами. Для того чтобы обеспечить бесперебойную работу сервисов, построенных на базе Мантикоры, имеются дистрибутивные таблицы, но мы рассмотрим это в другой статье.
А пока что у нас есть реплицированная на несколько нод база данных с таблицей продуктов, изменить конфигурацию этой таблицы можно с помощью использования приставки к имени таблицы с именем кластера, но удалить её уже не получится, даже с добавлением этой приставки. Для того, чтобы изменить настройки реплицируемой таблицы, сначала её нужно отключить от кластера: ALTER CLUSTER <cluster name> DROP <table name>, при этом таблица будет удалена только из кластера, но не из базы. С момента удаления таблицы из кластера обновить данные из приложения уже будет невозможно, так как оно ссылается на кластер (например, insert into pet_shop:products ...), а в нём таблицы уже нет (в приложении рекомендуется обработать эту ситуацию). А вот все операции по удалению или переконфигурации нам станут доступны напрямую с этой таблицей. Давайте поправим конфигурацию таблицы: переключимся со стеммера на лемматизатор.
Для этого нам потребуется сделать следующие шаги:
- Отключение таблицы от кластера
- Изменение морфологии в таблице со стеммера на лемматизатор
- Перезаливка данных в таблицу
- Восстановление таблицы в кластере
- Проверку на второй ноде
Отключение таблицы от кластера:
ALTER CLUSTER pet_shop DROP products;
Теперь таблица на всех нодах в кластере отключена от него и её схема и настройки могут быть модифицированы. Логика нашей работы подразумевает то, что на одной ноде мы выполняем некоторые технические работы, в свою очередь вторая выдает пользователю информацию по запросу select, но добавлять новые записи уже не получится, так как в клиенте при попытке записи используются команды в формате <cluster>:<table>, а в кластере этой таблицы уже нет.
update pet_shop:products set price = 9 where id = 3317338896206921730;
ERROR 1064 (42000): table products: table 'products' is not in any cluster, use just 'products'
После того, как мы отключили таблицу от кластера, попробуем выполнить запрос select: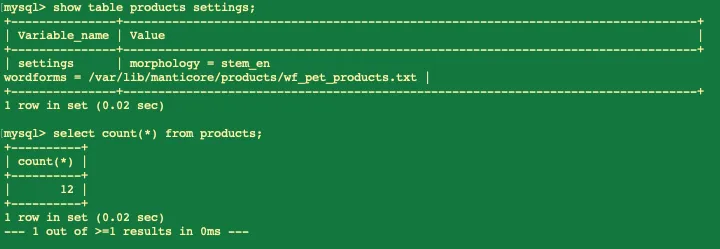
Как мы видим, запрос обрабатывается, данные все выдаются и конечный пользователь счастлив.
Теперь сделаем модификацию морфологии со стеммера на лемматизатор, переиндексируем записи и подключим все обратно. В прошлый раз мы выполняли замену файла словоформ и стеммера с помощью лома и некоторых нецензурных словесных форм. Тут будем использовать более цивилизованные инструменты - ведь все операции по замене файла словоформ или для смены морфологии, используемой в таблице можно сделать с помощью одной команды: ALTER TABLE <table name> morphology='<morph type>'. Заменим наш стеммер на лемматизатор:
ALTER TABLE products morphology='lemmatize_en_all';
После смены любых параметров связанных с предобработкой текста в базе данных необходимо выполнить переиндексацию всех существующих записей, чтобы новая морфология и прочие настройки токенизации применились к ним:
mysqldump -P9306 -h0 --replace -etc --skip-comments manticore products|mysql -P9306 -h0;
Тут мы используем технику работы с mysqldump, при этом перенапрявляя вывод дампа сразу на вход в мантикору через mysql. При этом --replace заставляет mysqldump генерировать не INSERT, а REPLACE команды, что позволяет “перезалить” всю таблицу за один раз. Тут надо иметь ввиду, что время выполнения этой команды для большой таблицы или на слабом сервере может быть продолжительным, но нас это не сильно пугает, так как у нас есть резервная нода, которая в данный момент отдаёт данные на запросы пользователей. Кроме того, команда mysqldump не блокирует таблицу.
Выполнив эту фантастически несложную манипуляцию по реконфигурации таблицы с продуктами, получили новую версию: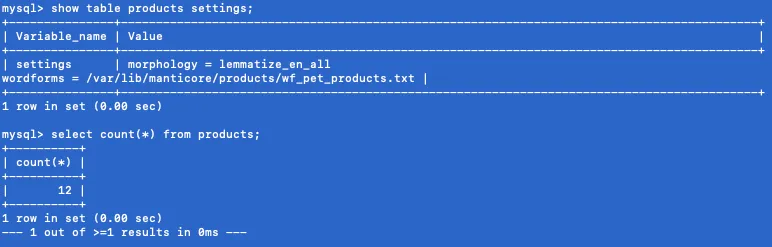
Новые настройки и все данные применены, теперь добавим эту таблицу снова в кластер:
ALTER CLUSTER pet_shop add products;
Всё, теперь таблица обновлена на всех серверах, при этом данные были доступны пользователям всё время со второй ноды, пока мы вылавливали недостающие файлы или конфигурировали и проверяли, чтобы всё работало корректно.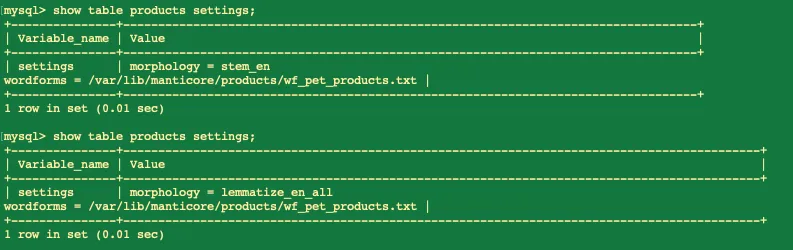
Стоит обратить внимание на восстановление всего кластера, если все ноды вышли из строя — при неправильной последовательности восстановления есть вероятность потери всех его настроек. Подробно способы восстановления описаны в документации.
Кстати, попробовать работу с репликацией и администрированием нод можно на сервисе курсов play.manticoresearch.com.
На этом на сегодня всё! Высокой доступности, меньше коллизий! С вами был Майк, удачи!