
Starting with 2.8.2 a new major feature is available - replication for percolate indexes.
The replication is based on Galera library (also used by Percona's mysql fork and MariaDB). We considered it would be better to use a tried and proven existing solution rather than inventing a bicycle and build it from the ground up which would have taken much longer.
Why only for percolate indexes? The percolate index is a modified Real-Time index which is easier to manipulate and thus a better candidate for the initial testing. But stay tuned as the next step will be to add Real-Time indexes support for replication!
How this affects me if I don't want to use replication? The replication feature comes built-in in the official packages, but if you don't plan to use it there is nothing that should prevent you from upgrading to the newest Manticore version. If you compile Manticore by yourself the requirements for compiled have been changed. Consult the documentation for the changes.
Replication clusters are index-based. Once a cluster is defined your can add percolate indexes to it.
The replication is multi-master and synchronous. This means you can write to any node and the changes will propagate to all nodes in the cluster immediately.
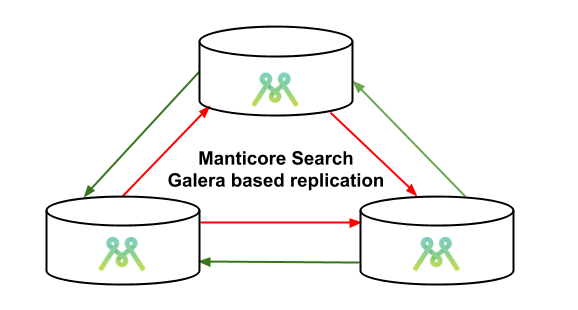
Replication setup
Requirements:
An API listen port must be opened on a dedicated interface (not 0.0.0.0).
A range of ports opened on dedicated interface used for replication. It's recommended to use at least 2 ports per cluster.
An open SphinxQL port to execute commands for configuring the node.
data_dir must be set in searchd configuration. That's needed for temporary replication data.
Optional:
- server_id - an unique number per node, used for UUID seeding, if not present the daemon will generate one based on MAC address
searchd configuration should look like:
searchd {
listen = 9306:mysql41
listen = my_ip1:9312
listen = my_ip1:9350-9459:replication
...
data_dir = /var/lib/manticore/data_dir
server_id = 1
...
}
On the first node we connect to it using SphinxQL and create the cluster:
mysql> CREATE CLUSTER test;
Alternative you can also specify the nodes that are going to connect to the new cluster. Beside the IP we also need to specify the API port.
mysql> CREATE CLUSTER test 'my_ip1:9312,my_ip2:9312,my_ip3:9312' as nodes;
The defined list of nodes is used in case of a cluster restart. If the nodes are not defined at creation or more nodes are added, the command ALTER CLUSTER cluster_name UPDATE nodes must be run to update the list of all active nodes, otherwise in case of restart the nodes not in the list must be added back into the cluster manually.
Next we connect to the other nodes and join them to the cluster by linking them with the existing node (using it's IP and API port):
mysql> JOIN CLUSTER test AT 'my_ip1:9312';
At this moment, we defined a cluster and next is to add an index (or more) to it. This can be done from any node:
mysql> ALTER CLUSTER test ADD pq1;
To add new stored queries to the index pq1 our usual INSERT query needs a small change: it's required to prefix the index name with the cluster name:
mysql> INSERT INTO test:pq1 VALUES('samsung');
The cluster prefix is only required for write statements (INSERT, REPLACE,DELETE TRUNCATE). Read statements (CALL PQ, SELECT and DESCRIBE) can use the regular index name.
What's next?
For more information about all replication options check the documentation .
In our online courses you can find an introduction to replication course as well as a simple recovery failover course.
At the time of writing this article replication for RealTime indexes is under development.