As you probably know recently a new release of Manticore 3.0 was released.
In this benchmark let’s see if it’s any better than 2.8. The test environment was as follows:
- Hacker News curated comments dataset of 2016 in CSV format
- OS: Ubuntu 18.04.1 LTS (Bionic Beaver), kernel: 4.15.0-47-generic
- CPU: Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz, 8 cores
- 32G RAM
- HDD
- Docker version 18.09.2
- Base image for indexing and searchd - Ubuntu:bionic
- stress-tester for benchmarking
The config is identical for the both versions of Manticore:
source full
{
type = csvpipe
csvpipe_command = cat /root/hacker_news_comments.prepared.csv|grep -v line_number
csvpipe_attr_uint = story_id
csvpipe_attr_timestamp = story_time
csvpipe_field = story_text
csvpipe_field = story_author
csvpipe_attr_uint = comment_id
csvpipe_field = comment_text
csvpipe_field = comment_author
csvpipe_attr_uint = comment_ranking
csvpipe_attr_uint = author_comment_count
csvpipe_attr_uint = story_comment_count
}
index full
{
path = /root/idx_full
source = full
html_strip = 1
mlock = 1
}
searchd
{
listen = 9306:mysql41
query_log = /root/query.log
log = /root/searchd.log
pid_file = /root/searchd.pid
binlog_path =
qcache_max_bytes = 0
}
Indexation
Indexation took 1303 seconds for Manticore 3.0 and 1322 seconds for Manticore 2.8.2:
Manticore 3.0:
indexing index 'full'...
collected 11654429 docs, 6198.6 MB
creating lookup: 11654.4 Kdocs, 100.0% done
creating histograms: 11654.4 Kdocs, 100.0% done
sorted 1115.7 Mhits, 100.0% done
total 11654429 docs, 6198580642 bytes
total <b>1303.470</b> sec, 4755444 bytes/sec, 8941.07 docs/sec
total 22924 reads, 16.605 sec, 238.4 kb/call avg, 0.7 msec/call avg
total 11687 writes, 13.532 sec, 855.1 kb/call avg, 1.1 msec/call avg
Manticore 2.8:
indexing index 'full'...
collected 11654429 docs, 6198.6 MB
sorted 1115.7 Mhits, 100.0% done
total 11654429 docs, 6198580642 bytes
total <b>1322.239</b> sec, 4687939 bytes/sec, 8814.15 docs/sec
total 11676 reads, 15.248 sec, 452.6 kb/call avg, 1.3 msec/call avg
total 9431 writes, 12.800 sec, 1065.3 kb/call avg, 1.3 msec/call avg
So with this data set and index schema indexation in 3.0 is faster than in 2.8 by ~1,5%.
Performance tests
The both instances were warmed up before testing.
Manticore 3.0:
total 4.7G
drwx------ 2 root root 4.0K May 14 17:41 .
drwxr-xr-x 3 root root 4.0K May 14 17:40 ..
-rw-r--r-- 1 root root 362M May 14 17:24 idx_full.spa
-rw-r--r-- 1 root root 3.1G May 14 17:36 idx_full.spd
-rw-r--r-- 1 root root 90M May 14 17:36 idx_full.spe
-rw-r--r-- 1 root root 628 May 14 17:36 idx_full.sph
-rw-r--r-- 1 root root 29K May 14 17:24 idx_full.sphi
-rw-r--r-- 1 root root 6.5M May 14 17:36 idx_full.spi
-rw------- 1 root root 0 May 14 17:41 idx_full.spl
-rw-r--r-- 1 root root 1.4M May 14 17:24 idx_full.spm
-rw-r--r-- 1 root root 1.1G May 14 17:36 idx_full.spp
-rw-r--r-- 1 root root 59M May 14 17:24 idx_full.spt
Manticore 2.8:
total 4.6G
drwx------ 2 root root 4.0K May 16 18:38 .
drwxr-xr-x 3 root root 4.0K May 14 17:43 ..
-rw-r--r-- 1 root root 362M May 14 17:24 idx_full.spa
-rw-r--r-- 1 root root 3.1G May 14 17:36 idx_full.spd
-rw-r--r-- 1 root root 27M May 14 17:36 idx_full.spe
-rw-r--r-- 1 root root 601 May 14 17:36 idx_full.sph
-rw-r--r-- 1 root root 6.3M May 14 17:36 idx_full.spi
-rw-r--r-- 1 root root 0 May 14 17:24 idx_full.spk
-rw------- 1 root root 0 May 16 18:38 idx_full.spl
-rw-r--r-- 1 root root 0 May 14 17:24 idx_full.spm
-rw-r--r-- 1 root root 1.1G May 14 17:36 idx_full.spp
-rw-r--r-- 1 root root 1 May 14 17:36 idx_full.sps
Test 1 - time to process top 1000 terms from the collection
First of all let’s just run a simple test - how long it takes to go through top 1000 frequent terms of the collection and find all documents for each:
The results are: 77.61 seconds for Manticore 2.8 and 71.79 seconds for Manticore 3.0.

So in this test Manticore Search 3.0 is faster than the previous version by 8%.
Test 2 - top 1000 frequent terms from the collection broken down by groups (top 1-50, top 50-100 etc.)
Now let’s see if 3.0 is better in terms of processing terms from different frequencies groups. Below you can find just few random examples from each of the groups:
| 1-50 | 50-100 | 100-150 | 150-200 | 200-250 | 250-300 |
| one | much | our | every | less | pay |
| with | really | into | without | another | understand |
| was | other | still | down | already | everyone |
| 300-350 | 350-400 | 400-450 | 450-500 | 500-550 | 550-600 |
| search | developers | create | interest | general | co |
| reason | whole | given | tried | model | office |
| nothing | name | friends | access | amount | paid |
| 600-650 | 650-700 | 700-750 | 750-800 | 800-850 | 850-900 |
| management | themselves | across | pg | paper | core |
| related | marketing | learned | opinion | pick | highly |
| goes | unless | posts | risk | strong | traffic |
| 900-950 | 950-1000 | ||||
| thoughts | decent | ||||
| interface | young | ||||
| response | english |


Manticore 2.8 is in average faster than 3.0 by 0,4% for latency and provides 0.5% higher throughput. This is within the error range.
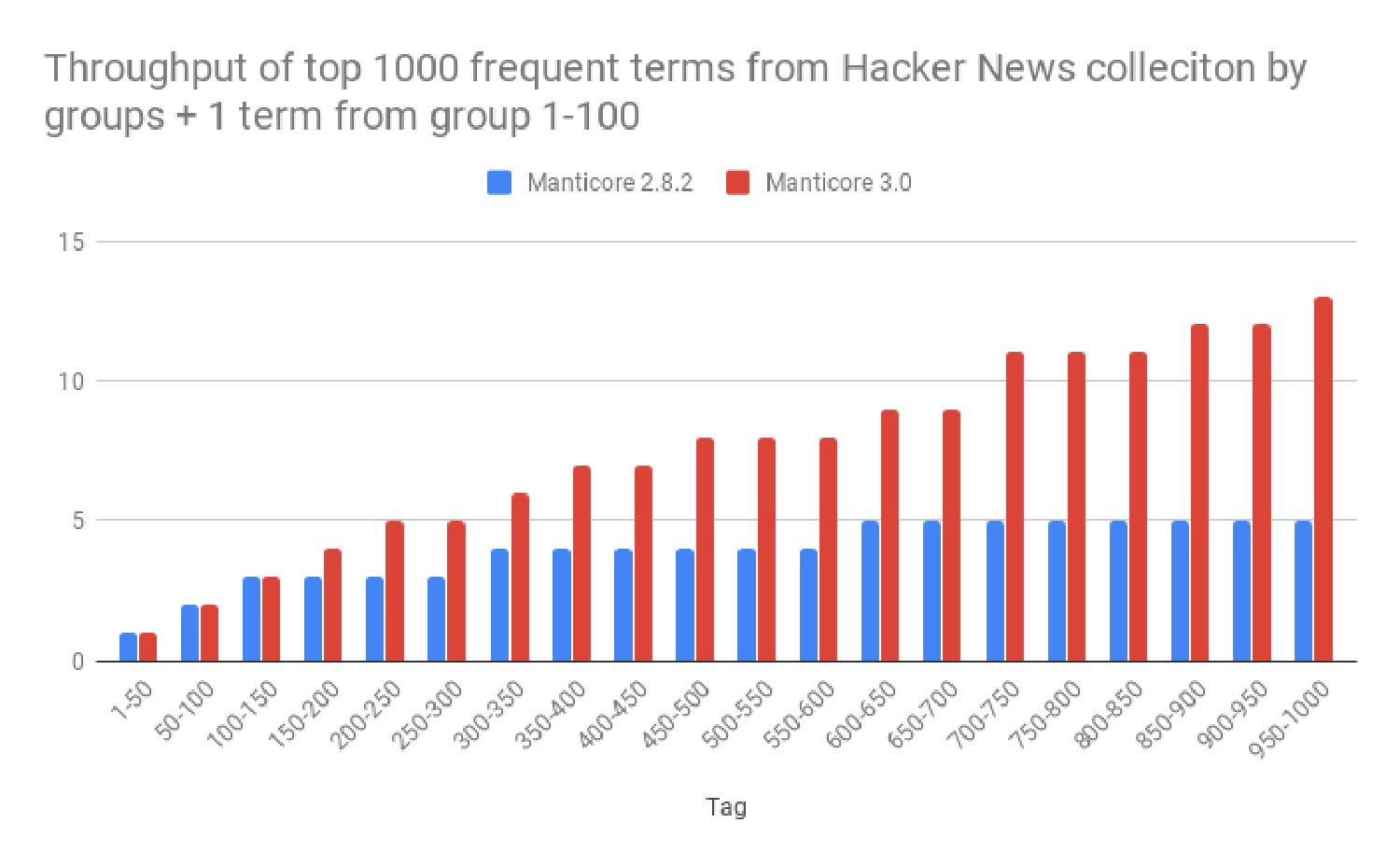
Test 3 - top 1000 frequent terms from the collection broken down by groups + 1 term from group 1-100
Let’s see how it works when you have one very frequent term and another less frequent from different frequency groups. The examples are:
| 1-50 | 50-100 | 100-150 | 150-200 | 200-250 | 250-300 |
| other can | the no | on over | about his | should big | s ever |
| no are | my use | other why | had day | had give | them let |
| here some | been know | s where | how sure | been big | here e |
| 300-350 | 350-400 | 400-450 | 450-500 | 500-550 | 550-600 |
| who developer | it book | now single | not access | at solution | their called |
| work started | an ycombinator | from add | use sites | know microsoft | as mostly |
| at hours | now value | also given | which built | than power | of early |
| 600-650 | 650-700 | 700-750 | 750-800 | 800-850 | 850-900 |
| know science | should marketing | should kids | the numbers | their drive | who highly |
| if agree | an minutes | t posts | time pg | there pick | has opportunity |
| would related | has country | get posts | http education | also extremely | could topic |
| 900-950 | 950-1000 | ||||
| any party | on particularly | ||||
| only response | could computers | ||||
| people firefox | about computers |


Manticore 3.0 shows in average 86.3% higher throughput and 109,5% lower 95p latency.
Test 4 - top 1000 frequent terms from the collection broken down by groups + 1 term from group 1-100, both terms enclosed in quotes to make a phrase
| 1-50 | 50-100 | 100-150 | 150-200 | 200-250 | 250-300 |
| "work not" | "you their" | "we still" | "s own" | "me getting" | "could run" |
| "my for" | "the very" | "your job" | "use got" | "here bad" | "then ever" |
| "but that" | "get com" | "i first" | "now day" | "up help" | "then making" |
| 300-350 | 350-400 | 400-450 | 450-500 | 500-550 | 550-600 |
| "it information" | "them community" | "1 care" | "what mobile" | "out happy" | "to watch" |
| "com side" | "this server" | "com position" | "at huge" | "how stop" | "s written" |
| "he looks" | "was x" | "time become" | "the tried" | "should comes" | "other sounds" |
| 600-650 | 650-700 | 700-750 | 750-800 | 800-850 | 850-900 |
| "by api" | "don soon" | "t curious" | "was multiple" | "of fix" | "things absolutely" |
| "of three" | "use coming" | "that lack" | "who ui" | "ve understanding" | "most topic" |
| "really talking" | "make applications" | "really environment" | "will whoishiring" | "at expensive" | "more core" |
| 900-950 | 950-1000 | ||||
| "just framework" | "it sorry" | ||||
| "work resources" | "want benefit" | ||||
| "their resources" | "s further" |


Manticore v3 is in average 5.6% faster for throughput and 25.1% lower for 95p latency.
Test 5 - 2 terms each from group 600-750 under different concurrencies
This test aims to show the difference in throughput under different query concurrencies. Few random examples:
Query examples: “talking view”, “imagine 15”, “curious term”


So version 3 is faster under all the concurrencies by average 18% with avg 95p latency lower by 15%.
Тest 6 - 3-5 terms from different groups
Let’s now check performance with longer queries.
- 3 terms from groups 100-200 400-500 800-900
- 4 terms from groups 100-200 300-400 500-600 800-900
- 5 terms from groups 100-200 300-400 500-600 800-900 900-1000
Query examples:
| 3 terms | 4 terms | 5 terms |
| doing under poor | these search awesome background |
got reason results taken ad |
| always tried stories | working again comment links |
feel process situation faster bring |
| job text card | google number network function |
going days browser known salary |


Version 3 wins again: throughput - 104% higher with 113% lower 95p latency.
TEST 7: 3 AND terms from groups 300-600 and 1 NOT from 300-400
Let’s now add one NOT term to 3 AND.


throughput in v3 - 33.3% higher, 95p latency - 32% lower.
Conclusions
The new version demonstrates significantly higher performance in all the tests except for the test #2, but the difference there is within the error range (0.4-0.5%).
The test is fully dockerized and open sourced in our github. The detailed results can be found here We’ll appreciate if you run the same tests on your hardware or contibute by adding more tests to the suite and let us know the results.
If you find any issue or inaccuracy don’t hesitate to let us know.
Thank you for reading!